 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECA: Efficient Continual Alignment for Open-Ended Image-to-Text Generation
Jun 10, 2026Incremental Learning (IL) for Open-ended Image-to-Text Generation (OpenITG) enables models to continuously generate accurate, contextually relevant text for new images while preserving previously acquired knowledge. Unlike prior studies, this paper addresses a more practical scenario in which the predominant category of visual data shifts over time as environments evolve. In this context, we introduce a new notion of continual alignment, which incrementally adapts the alignment module within pre-trained VLMs to preserve high-quality cross-modal representations. Based on this idea, we propose Efficient Continual Alignment (ECA), a novel exemplar-free IL approach for OpenITG. The key challenge is enabling the model to acquire new, task-specific features while minimizing interference with the established alignment without accessing raw data from previous tasks. To address this, ECA employs three core mechanisms: a Mixture of Query (MoQ) module that adapts task-specific query tokens, a Fisher Dynamic Expansion (FeDEx) that dynamically expands model structure based on a Fisher Information Matrix (FIM)-based metric, and an embedding dictionary with Dictionary Replay (DR) to retain past knowledge. To evaluate ECA's performance, we construct four new IL OpenITG benchmarks that better reflect real-world scenarios. Experimental results demonstrate that ECA significantly mitigates catastrophic forgetting and improves IL performance compared to baseline methods. Code and benchmarks are available at https://github.com/Snowball0823/ECA.
Error Bound Analysis of Physics-Informed Neural Networks-Driven T2 Quantification in Cardiac Magnetic Resonance Imaging
Dec 16, 2025



Physics-Informed Neural Networks (PINN) are emerging as a promising approach for quantitative parameter estimation of Magnetic Resonance Imaging (MRI). While existing deep learning methods can provide an accurate quantitative estimation of the T2 parameter, they still require large amounts of training data and lack theoretical support and a recognized gold standard. Thus, given the absence of PINN-based approaches for T2 estimation, we propose embedding the fundamental physics of MRI, the Bloch equation, in the loss of PINN, which is solely based on target scan data and does not require a pre-defined training database. Furthermore, by deriving rigorous upper bounds for both the T2 estimation error and the generalization error of the Bloch equation solution, we establish a theoretical foundation for evaluating the PINN's quantitative accuracy. Even without access to the ground truth or a gold standard, this theory enables us to estimate the error with respect to the real quantitative parameter T2. The accuracy of T2 mapping and the validity of the theoretical analysis are demonstrated on a numerical cardiac model and a water phantom, where our method exhibits excellent quantitative precision in the myocardial T2 range. Clinical applicability is confirmed in 94 acute myocardial infarction (AMI) patients, achieving low-error quantitative T2 estimation under the theoretical error bound, highlighting the robustness and potential of PINN.
Simultaneous Deep Learning of Myocardium Segmentation and T2 Quantification for Acute Myocardial Infarction MRI
May 17, 2024



In cardiac Magnetic Resonance Imaging (MRI) analysis, simultaneous myocardial segmentation and T2 quantification are crucial for assessing myocardial pathologies. Existing methods often address these tasks separately, limiting their synergistic potential. To address this, we propose SQNet, a dual-task network integrating Transformer and Convolutional Neural Network (CNN) components. SQNet features a T2-refine fusion decoder for quantitative analysis, leveraging global features from the Transformer, and a segmentation decoder with multiple local region supervision for enhanced accuracy. A tight coupling module aligns and fuses CNN and Transformer branch features, enabling SQNet to focus on myocardium regions. Evaluation on healthy controls (HC) and acute myocardial infarction patients (AMI) demonstrates superior segmentation dice scores (89.3/89.2) compared to state-of-the-art methods (87.7/87.9). T2 quantification yields strong linear correlations (Pearson coefficients: 0.84/0.93) with label values for HC/AMI, indicating accurate mapping. Radiologist evaluations confirm SQNet's superior image quality scores (4.60/4.58 for segmentation, 4.32/4.42 for T2 quantification) over state-of-the-art methods (4.50/4.44 for segmentation, 3.59/4.37 for T2 quantification). SQNet thus offers accurate simultaneous segmentation and quantification, enhancing cardiac disease diagnosis, such as AMI.
milliFlow: Scene Flow Estimation on mmWave Radar Point Cloud for Human Motion Sensing
Jul 03, 2023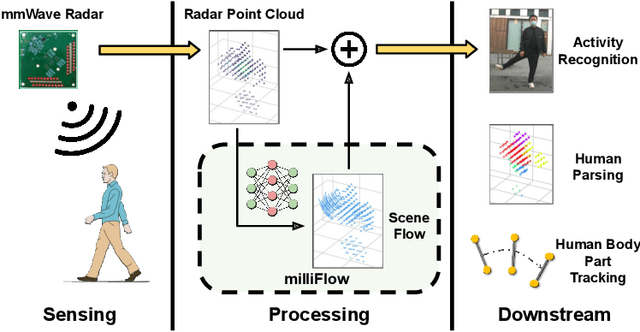
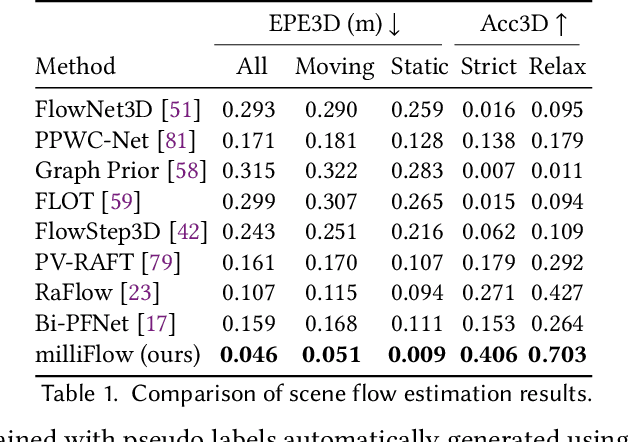
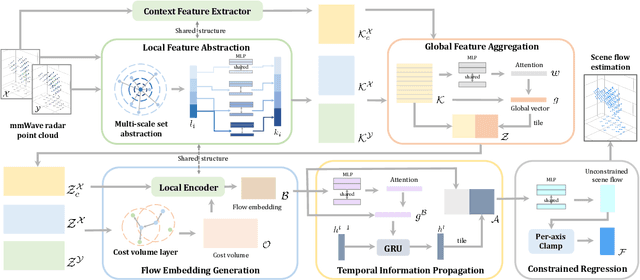
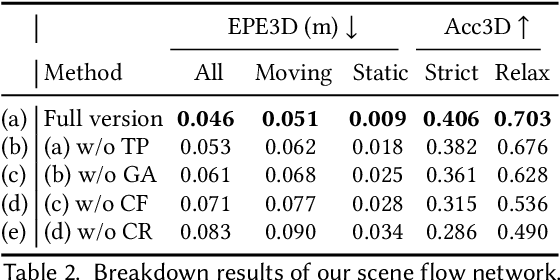
Approaching the era of ubiquitous computing, human motion sensing plays a crucial role in smart systems for decision making, user interaction, and personalized services. Extensive research has been conducted on human tracking, pose estimation, gesture recognition, and activity recognition, which are predominantly based on cameras in traditional methods. However, the intrusive nature of cameras limits their use in smart home applications. To address this, mmWave radars have gained popularity due to their privacy-friendly features. In this work, we propose \textit{milliFlow}, a novel deep learning method for scene flow estimation as a complementary motion information for mmWave point cloud, serving as an intermediate level of features and directly benefiting downstream human motion sensing tasks. Experimental results demonstrate the superior performance of our method with an average 3D endpoint error of 4.6cm, significantly surpassing the competing approaches. Furthermore, by incorporating scene flow information, we achieve remarkable improvements in human activity recognition, human parsing, and human body part tracking. To foster further research in this area, we provide our codebase and dataset for open access.
CubeLearn: End-to-end Learning for Human Motion Recognition from Raw mmWave Radar Signals
Nov 07, 2021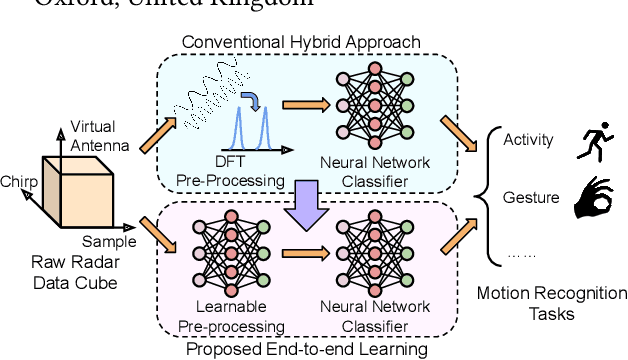

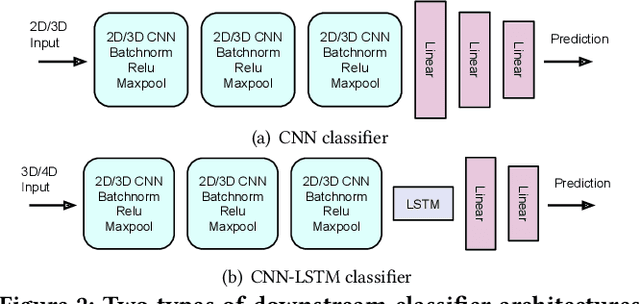

mmWave FMCW radar has attracted huge amount of research interest for human-centered applications in recent years, such as human gesture/activity recognition. Most existing pipelines are built upon conventional Discrete Fourier Transform (DFT) pre-processing and deep neural network classifier hybrid methods, with a majority of previous works focusing on designing the downstream classifier to improve overall accuracy. In this work, we take a step back and look at the pre-processing module. To avoid the drawbacks of conventional DFT pre-processing, we propose a learnable pre-processing module, named CubeLearn, to directly extract features from raw radar signal and build an end-to-end deep neural network for mmWave FMCW radar motion recognition applications. Extensive experiments show that our CubeLearn module consistently improves the classification accuracies of different pipelines, especially benefiting those previously weaker models. We provide ablation studies on initialization methods and structure of the proposed module, as well as an evaluation of the running time on PC and edge devices. This work also serves as a comparison of different approaches towards data cube slicing. Through our task agnostic design, we propose a first step towards a generic end-to-end solution for radar recognition problems.
P2-Net: Joint Description and Detection of Local Features for Pixel and Point Matching
Mar 01, 2021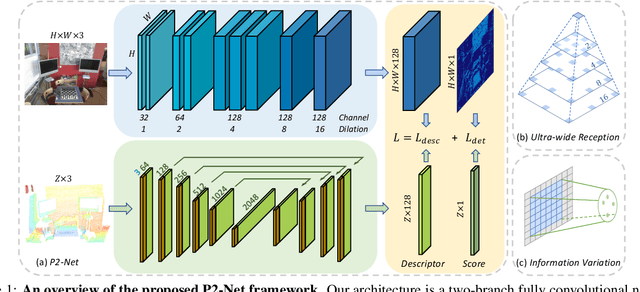
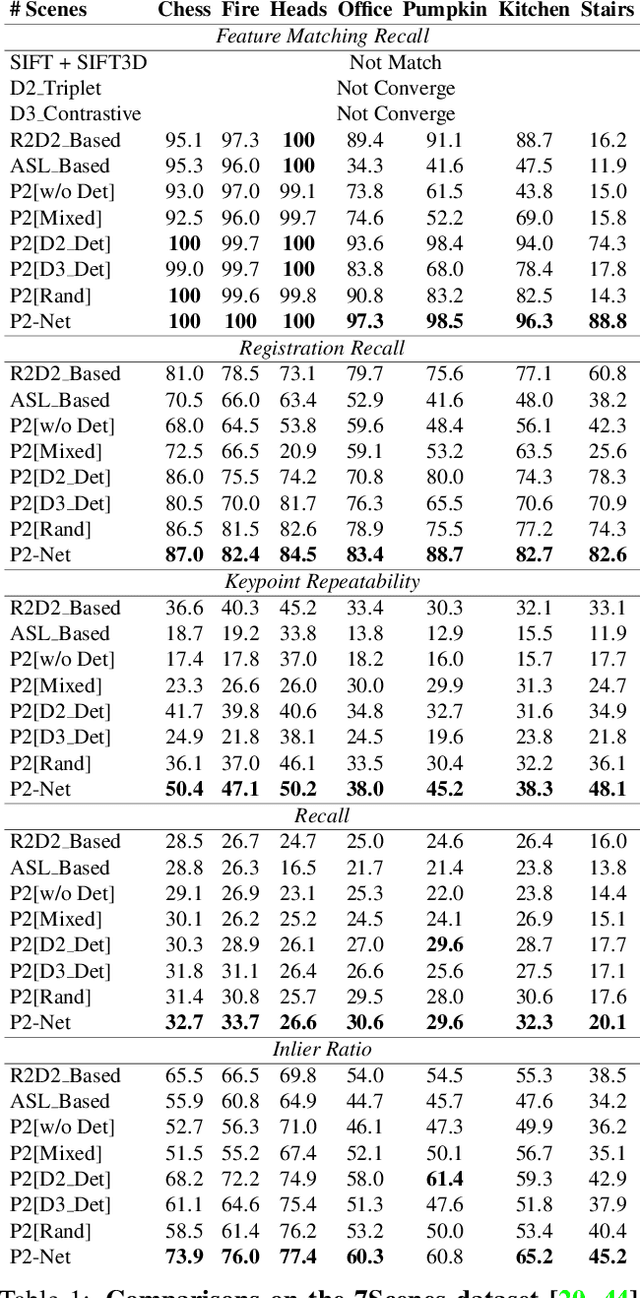
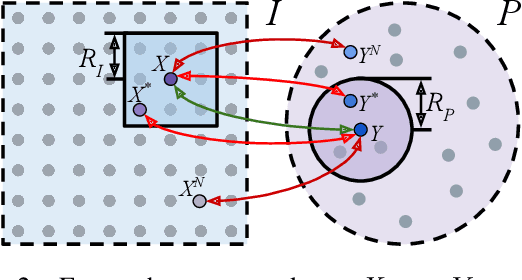
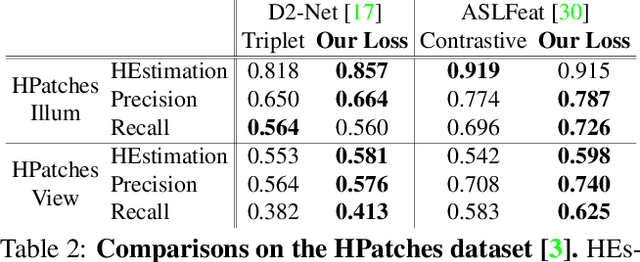
Accurately describing and detecting 2D and 3D keypoints is crucial to establishing correspondences across images and point clouds. Despite a plethora of learning-based 2D or 3D local feature descriptors and detectors having been proposed, the derivation of a shared descriptor and joint keypoint detector that directly matches pixels and points remains under-explored by the community. This work takes the initiative to establish fine-grained correspondences between 2D images and 3D point clouds. In order to directly match pixels and points, a dual fully convolutional framework is presented that maps 2D and 3D inputs into a shared latent representation space to simultaneously describe and detect keypoints. Furthermore, an ultra-wide reception mechanism in combination with a novel loss function are designed to mitigate the intrinsic information variations between pixel and point local regions. Extensive experimental results demonstrate that our framework shows competitive performance in fine-grained matching between images and point clouds and achieves state-of-the-art results for the task of indoor visual localization. Our source code will be available at [no-name-for-blind-review].
3-D Motion Capture of an Unmodified Drone with Single-chip Millimeter Wave Radar
Nov 13, 2020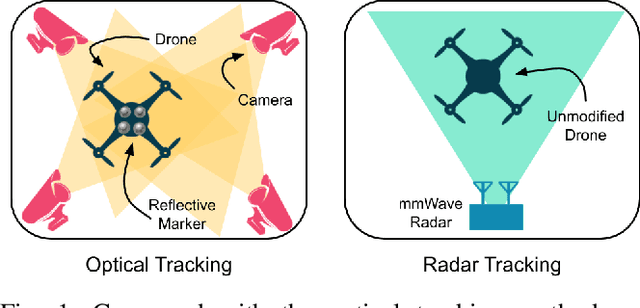
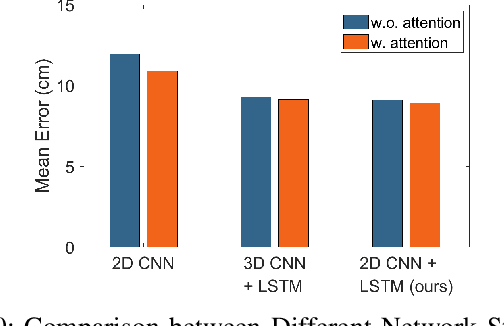

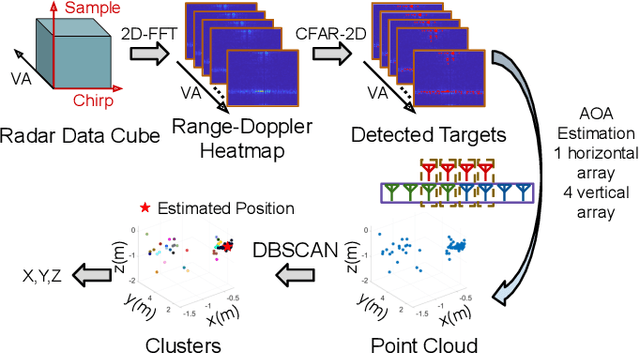
Accurate motion capture of aerial robots in 3-D is a key enabler for autonomous operation in indoor environments such as warehouses or factories, as well as driving forward research in these areas. The most commonly used solutions at present are optical motion capture (e.g. VICON) and Ultrawideband (UWB), but these are costly and cumbersome to deploy, due to their requirement of multiple cameras/sensors spaced around the tracking area. They also require the drone to be modified to carry an active or passive marker. In this work, we present an inexpensive system that can be rapidly installed, based on single-chip millimeter wave (mmWave) radar. Importantly, the drone does not need to be modified or equipped with any markers, as we exploit the Doppler signals from the rotating propellers. Furthermore, 3-D tracking is possible from a single point, greatly simplifying deployment. We develop a novel deep neural network and demonstrate decimeter level 3-D tracking at 10Hz, achieving better performance than classical baselines. Our hope is that this low-cost system will act to catalyse inexpensive drone research and increased autonomy.
milliEgo: mmWave Aided Egomotion Estimation with Deep Sensor Fusion
Jun 03, 2020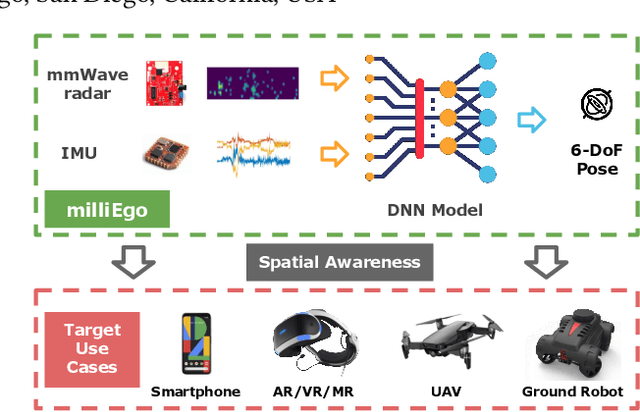
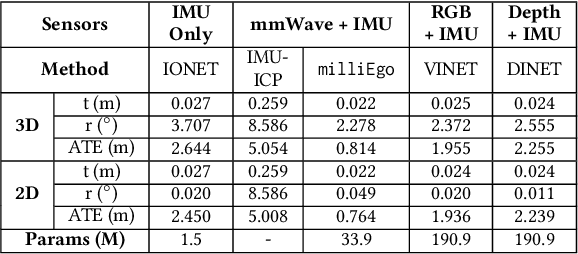
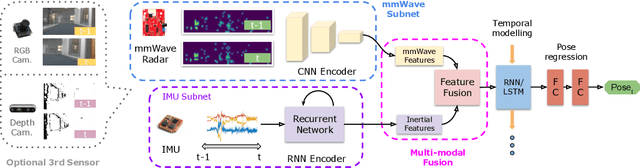
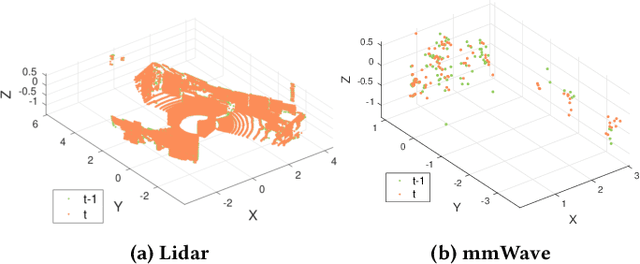
Robust and accurate trajectory estimation of mobile agents such as people and robots is a key requirement for providing spatial awareness to emerging capabilities such as augmented reality or autonomous interaction. Although currently dominated by vision based techniques e.g., visual-inertial odometry, these suffer from challenges with scene illumination or featureless surfaces. As an alternative, we propose \sysname, a novel deep-learning approach to robust egomotion estimation which exploits the capabilities of low-cost mmWave radar. Although mmWave radar has a fundamental advantage over monocular cameras of being metric i.e., providing absolute scale or depth, current single chip solutions have limited and sparse imaging resolution, making existing point-cloud registration techniques brittle. We propose a new architecture that is optimized for solving this underdetermined pose transformation problem. Secondly, to robustly fuse mmWave pose estimates with additional sensors, e.g. inertial or visual sensor we introduce a mixed attention approach to deep fusion. Through extensive experiments, we demonstrate how mmWave radar outperforms existing state-of-the-art odometry techniques. We also show that the neural architecture can be made highly efficient and suitable for real-time embedded applications.
PointLoc: Deep Pose Regressor for LiDAR Point Cloud Localization
Mar 05, 2020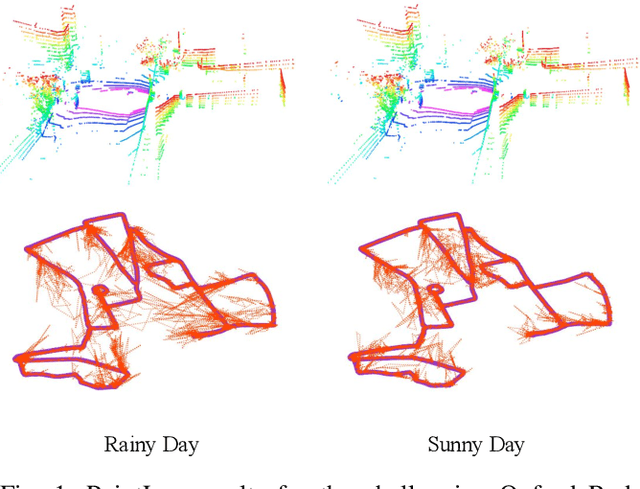
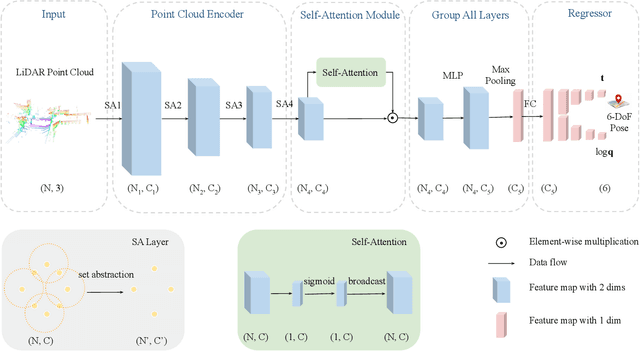
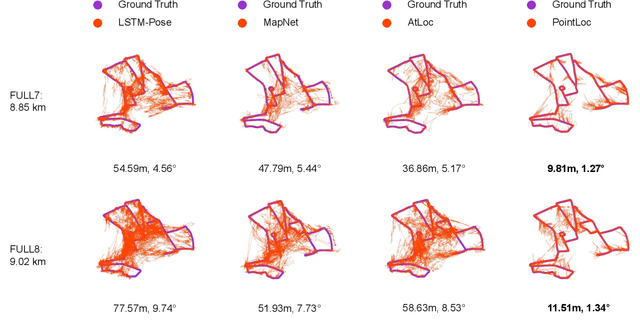
In this paper, we present a novel end-to-end learning-based LiDAR relocalization framework, termed PointLoc, which infers 6-DoF poses directly using only a single point cloud as input, without requiring a pre-built map. Compared to RGB image-based relocalization, LiDAR frames can provide rich and robust geometric information about a scene. However, LiDAR point clouds are sparse and unstructured making it difficult to apply traditional deep learning regression models for this task. We address this issue by proposing a novel PointNet-style architecture with self-attention to efficiently estimate 6-DoF poses from 360{\deg} LiDAR input frames. Extensive experiments on recently released challenging Oxford Radar RobotCar dataset and real-world robot experiments demonstrate that the proposed method can achieve accurate relocalization performance. We show that our approach improves the state-of-the-art MapNet by 69.59% in translation and 75.70% in rotation, and AtLoc by 66.86% in translation and 78.83% in rotation on the challenging outdoor large-scale Oxford Radar RobotCar dataset.
Deep Learning based Pedestrian Inertial Navigation: Methods, Dataset and On-Device Inference
Jan 13, 2020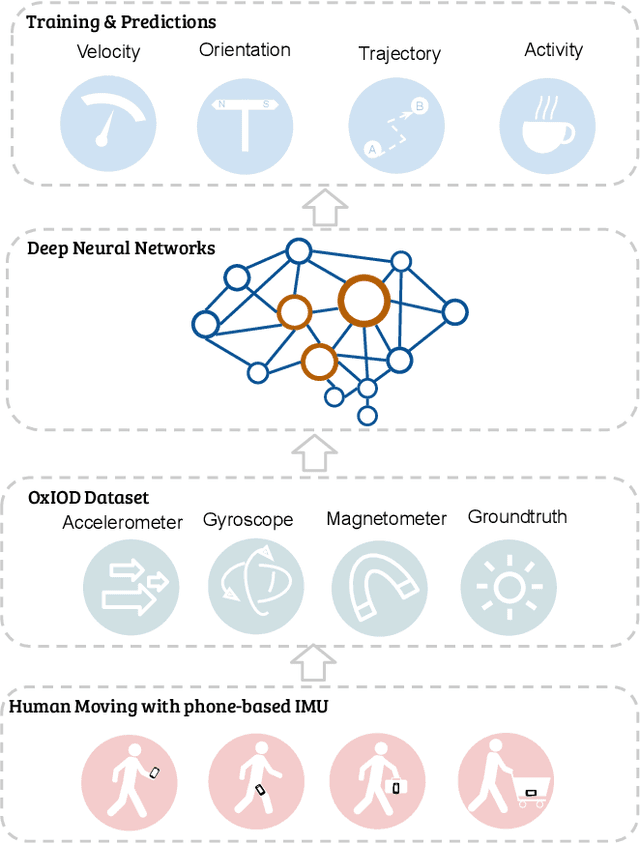
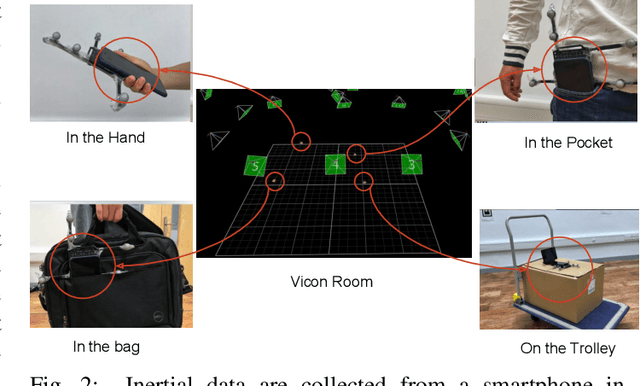
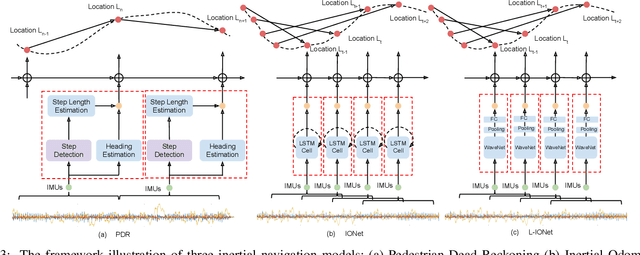
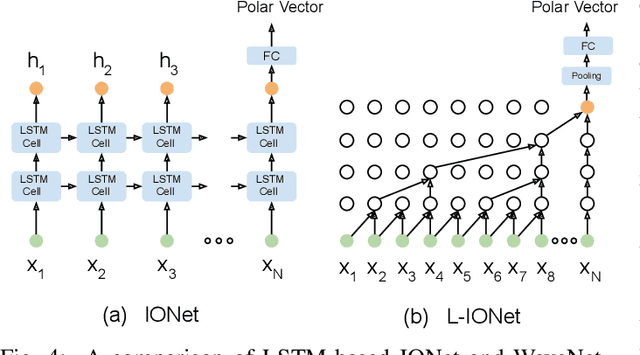
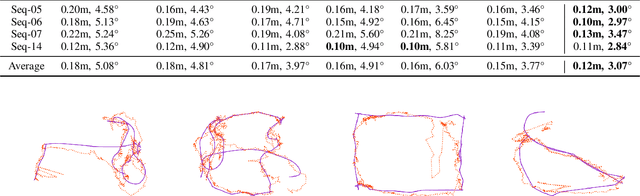
Modern inertial measurements units (IMUs) are small, cheap, energy efficient, and widely employed in smart devices and mobile robots. Exploiting inertial data for accurate and reliable pedestrian navigation supports is a key component for emerging Internet-of-Things applications and services. Recently, there has been a growing interest in applying deep neural networks (DNNs) to motion sensing and location estimation. However, the lack of sufficient labelled data for training and evaluating architecture benchmarks has limited the adoption of DNNs in IMU-based tasks. In this paper, we present and release the Oxford Inertial Odometry Dataset (OxIOD), a first-of-its-kind public dataset for deep learning based inertial navigation research, with fine-grained ground-truth on all sequences. Furthermore, to enable more efficient inference at the edge, we propose a novel lightweight framework to learn and reconstruct pedestrian trajectories from raw IMU data. Extensive experiments show the effectiveness of our dataset and methods in achieving accurate data-driven pedestrian inertial navigation on resource-constrained devices.