 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatch to Win: Analysing Sequences Lengths for Efficient Self-supervised Learning in Speech and Audio
Oct 03, 2022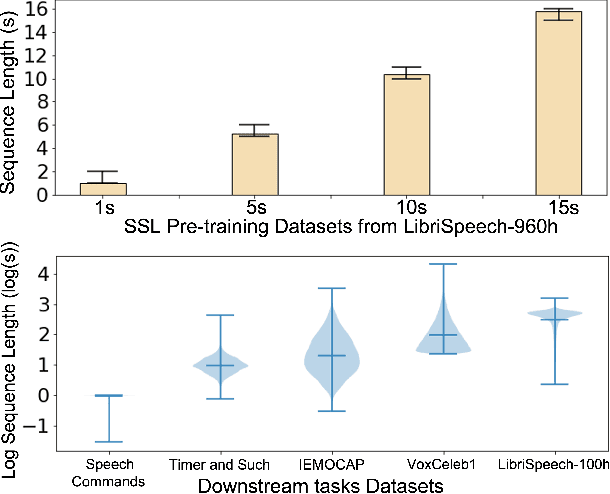

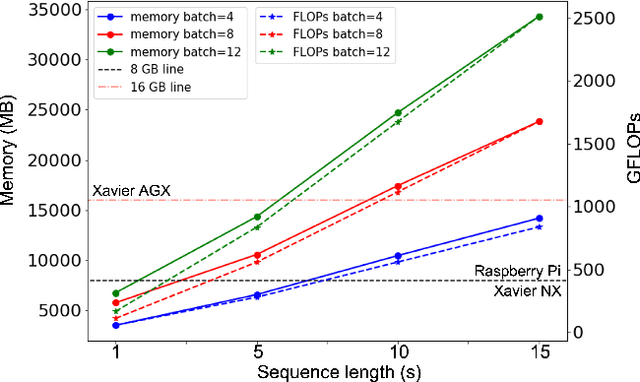
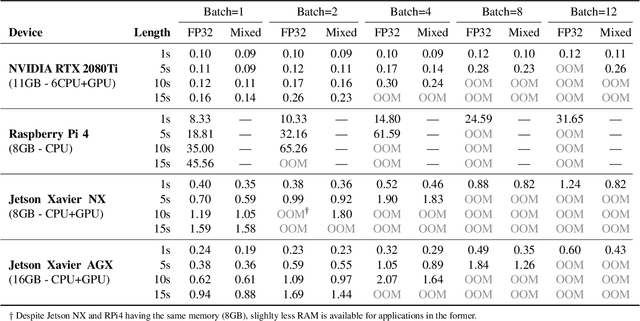
Self-supervised learning (SSL) has proven vital in speech and audio-related applications. The paradigm trains a general model on unlabeled data that can later be used to solve specific downstream tasks. This type of model is costly to train as it requires manipulating long input sequences that can only be handled by powerful centralised servers. Surprisingly, despite many attempts to increase training efficiency through model compression, the effects of truncating input sequence lengths to reduce computation have not been studied. In this paper, we provide the first empirical study of SSL pre-training for different specified sequence lengths and link this to various downstream tasks. We find that training on short sequences can dramatically reduce resource costs while retaining a satisfactory performance for all tasks. This simple one-line change would promote the migration of SSL training from data centres to user-end edge devices for more realistic and personalised applications.
End-to-End Speech Recognition from Federated Acoustic Models
Apr 29, 2021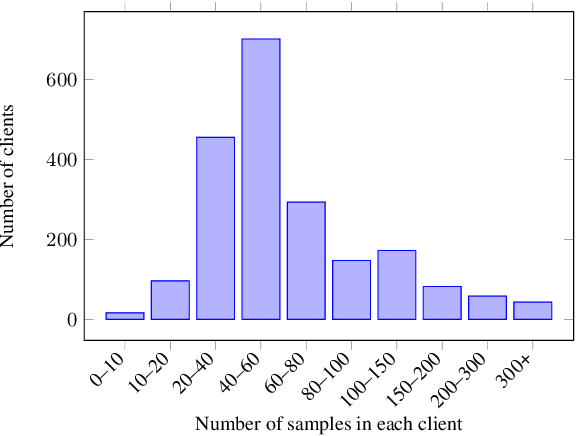

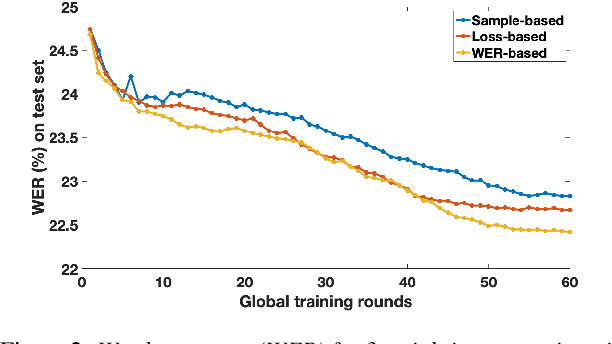
Training Automatic Speech Recognition (ASR) models under federated learning (FL) settings has recently attracted considerable attention. However, the FL scenarios often presented in the literature are artificial and fail to capture the complexity of real FL systems. In this paper, we construct a challenging and realistic ASR federated experimental setup consisting of clients with heterogeneous data distributions using the French Common Voice dataset, a large heterogeneous dataset containing over 10k speakers. We present the first empirical study on attention-based sequence-to-sequence E2E ASR model with three aggregation weighting strategies -- standard FedAvg, loss-based aggregation and a novel word error rate (WER)-based aggregation, are conducted in two realistic FL scenarios: cross-silo with 10-clients and cross-device with 2k-clients. In particular, the WER-based weighting method is proposed to better adapt FL to the context of ASR by integrating the error rate metric with the aggregation process. Our analysis on E2E ASR from heterogeneous and realistic federated acoustic models provides the foundations for future research and development of realistic FL-based ASR applications.
Graph-based Thermal-Inertial SLAM with Probabilistic Neural Networks
Apr 18, 2021
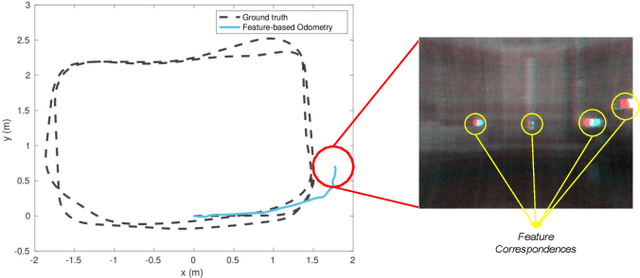

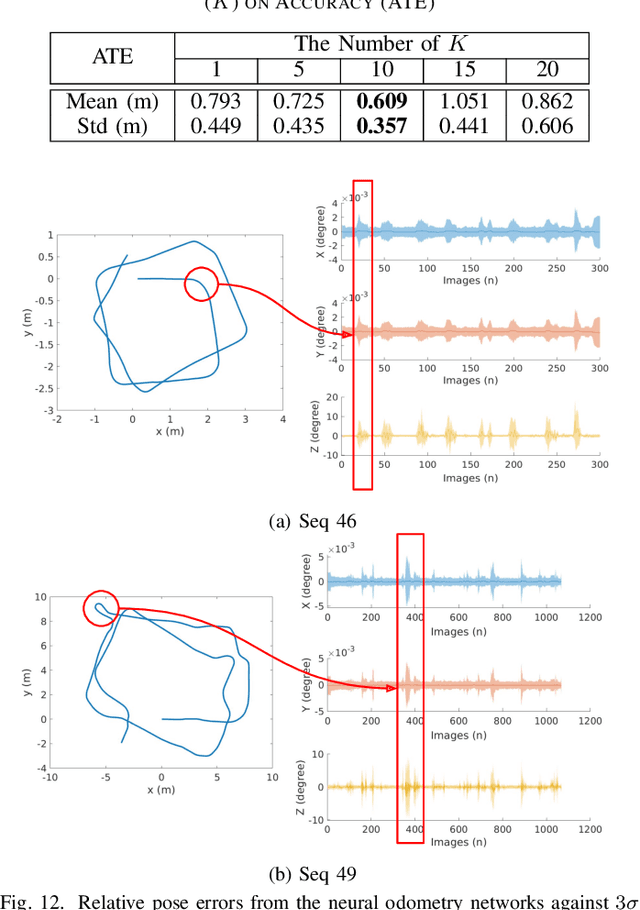
Simultaneous Localization and Mapping (SLAM) system typically employ vision-based sensors to observe the surrounding environment. However, the performance of such systems highly depends on the ambient illumination conditions. In scenarios with adverse visibility or in the presence of airborne particulates (e.g. smoke, dust, etc.), alternative modalities such as those based on thermal imaging and inertial sensors are more promising. In this paper, we propose the first complete thermal-inertial SLAM system which combines neural abstraction in the SLAM front end with robust pose graph optimization in the SLAM back end. We model the sensor abstraction in the front end by employing probabilistic deep learning parameterized by Mixture Density Networks (MDN). Our key strategies to successfully model this encoding from thermal imagery are the usage of normalized 14-bit radiometric data, the incorporation of hallucinated visual (RGB) features, and the inclusion of feature selection to estimate the MDN parameters. To enable a full SLAM system, we also design an efficient global image descriptor which is able to detect loop closures from thermal embedding vectors. We performed extensive experiments and analysis using three datasets, namely self-collected ground robot and handheld data taken in indoor environment, and one public dataset (SubT-tunnel) collected in underground tunnel. Finally, we demonstrate that an accurate thermal-inertial SLAM system can be realized in conditions of both benign and adverse visibility.
milliEgo: mmWave Aided Egomotion Estimation with Deep Sensor Fusion
Jun 03, 2020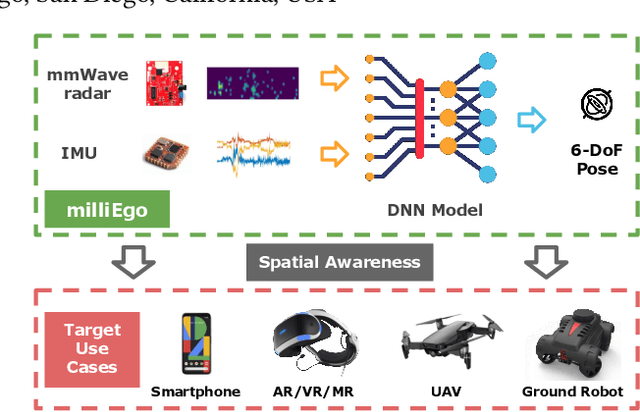
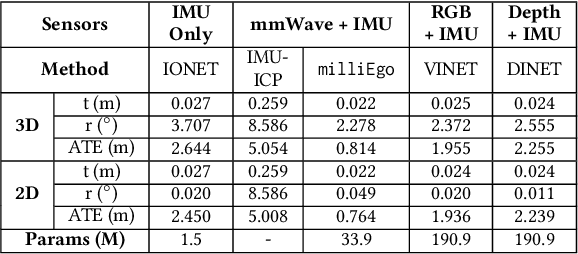
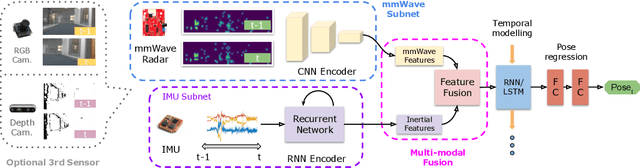
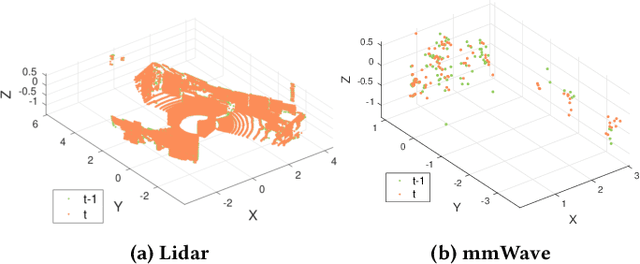
Robust and accurate trajectory estimation of mobile agents such as people and robots is a key requirement for providing spatial awareness to emerging capabilities such as augmented reality or autonomous interaction. Although currently dominated by vision based techniques e.g., visual-inertial odometry, these suffer from challenges with scene illumination or featureless surfaces. As an alternative, we propose \sysname, a novel deep-learning approach to robust egomotion estimation which exploits the capabilities of low-cost mmWave radar. Although mmWave radar has a fundamental advantage over monocular cameras of being metric i.e., providing absolute scale or depth, current single chip solutions have limited and sparse imaging resolution, making existing point-cloud registration techniques brittle. We propose a new architecture that is optimized for solving this underdetermined pose transformation problem. Secondly, to robustly fuse mmWave pose estimates with additional sensors, e.g. inertial or visual sensor we introduce a mixed attention approach to deep fusion. Through extensive experiments, we demonstrate how mmWave radar outperforms existing state-of-the-art odometry techniques. We also show that the neural architecture can be made highly efficient and suitable for real-time embedded applications.
DeepTIO: A Deep Thermal-Inertial Odometry with Visual Hallucination
Sep 16, 2019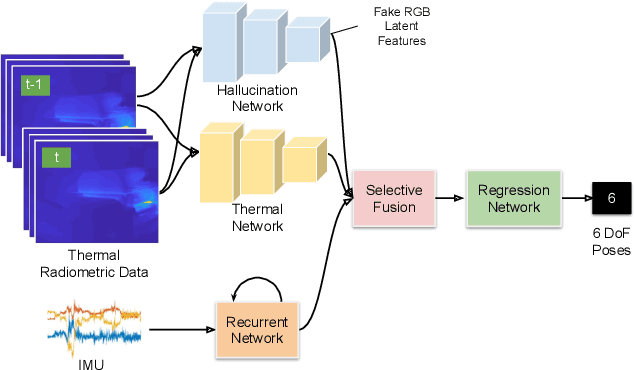
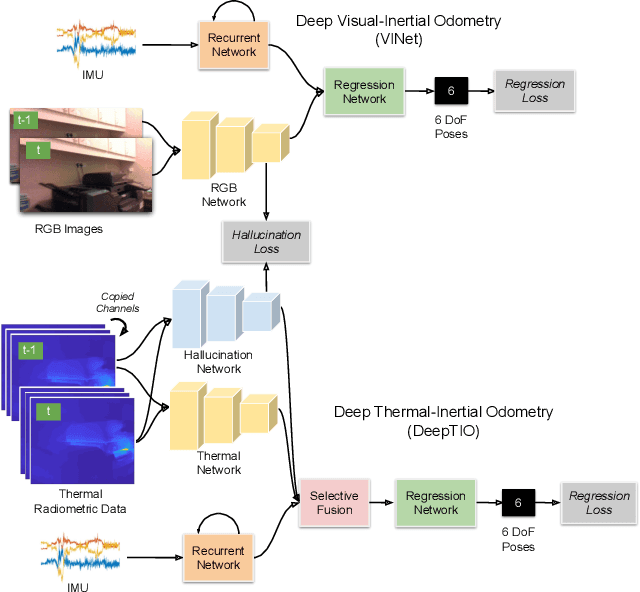
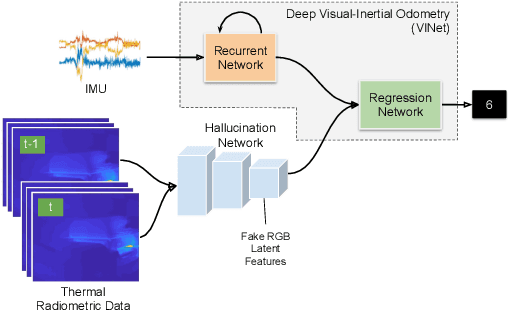
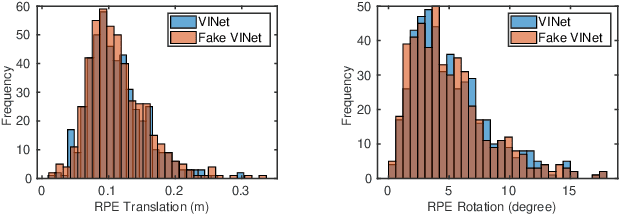
Visual odometry shows excellent performance in a wide range of environments. However, in visually-denied scenarios (e.g. heavy smoke or darkness), pose estimates degrade or even fail. Thermal imaging cameras are commonly used for perception and inspection when the environment has low visibility. However, their use in odometry estimation is hampered by the lack of robust visual features. In part, this is as a result of the sensor measuring the ambient temperature profile rather than scene appearance and geometry. To overcome these issues, we propose a Deep Neural Network model for thermal-inertial odometry (DeepTIO) by incorporating a visual hallucination network to provide the thermal network with complementary information. The hallucination network is taught to predict fake visual features from thermal images by using the robust Huber loss. We also employ selective fusion to attentively fuse the features from three different modalities, i.e thermal, hallucination, and inertial features. Extensive experiments are performed in our large scale hand-held data in benign and smoke-filled environments, showing the efficacy of the proposed model.
Distilling Knowledge From a Deep Pose Regressor Network
Aug 02, 2019
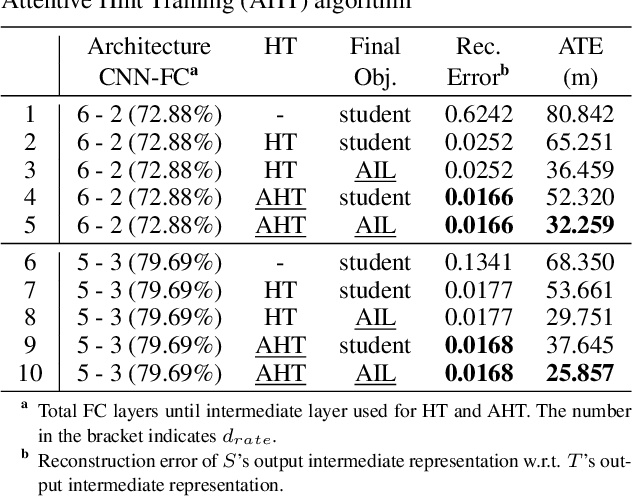


This paper presents a novel method to distill knowledge from a deep pose regressor network for efficient Visual Odometry (VO). Standard distillation relies on "dark knowledge" for successful knowledge transfer. As this knowledge is not available in pose regression and the teacher prediction is not always accurate, we propose to emphasize the knowledge transfer only when we trust the teacher. We achieve this by using teacher loss as a confidence score which places variable relative importance on the teacher prediction. We inject this confidence score to the main training task via Attentive Imitation Loss (AIL) and when learning the intermediate representation of the teacher through Attentive Hint Training (AHT) approach. To the best of our knowledge, this is the first work which successfully distill the knowledge from a deep pose regression network. Our evaluation on the KITTI and Malaga dataset shows that we can keep the student prediction close to the teacher with up to 92.95% parameter reduction and 2.12x faster in computation time.
Learning Monocular Visual Odometry through Geometry-Aware Curriculum Learning
Mar 25, 2019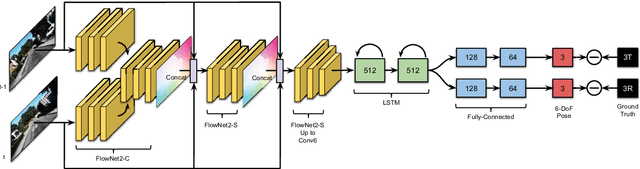
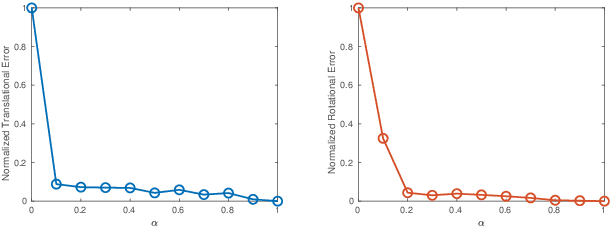

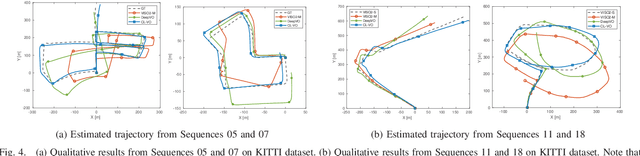
Inspired by the cognitive process of humans and animals, Curriculum Learning (CL) trains a model by gradually increasing the difficulty of the training data. In this paper, we study whether CL can be applied to complex geometry problems like estimating monocular Visual Odometry (VO). Unlike existing CL approaches, we present a novel CL strategy for learning the geometry of monocular VO by gradually making the learning objective more difficult during training. To this end, we propose a novel geometry-aware objective function by jointly optimizing relative and composite transformations over small windows via bounded pose regression loss. A cascade optical flow network followed by recurrent network with a differentiable windowed composition layer, termed CL-VO, is devised to learn the proposed objective. Evaluation on three real-world datasets shows superior performance of CL-VO over state-of-the-art feature-based and learning-based VO.
GANVO: Unsupervised Deep Monocular Visual Odometry and Depth Estimation with Generative Adversarial Networks
Sep 20, 2018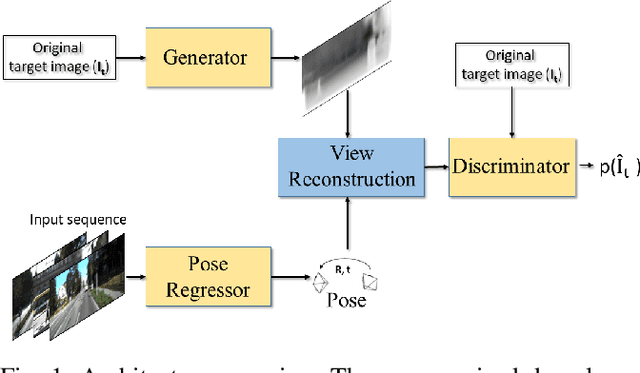

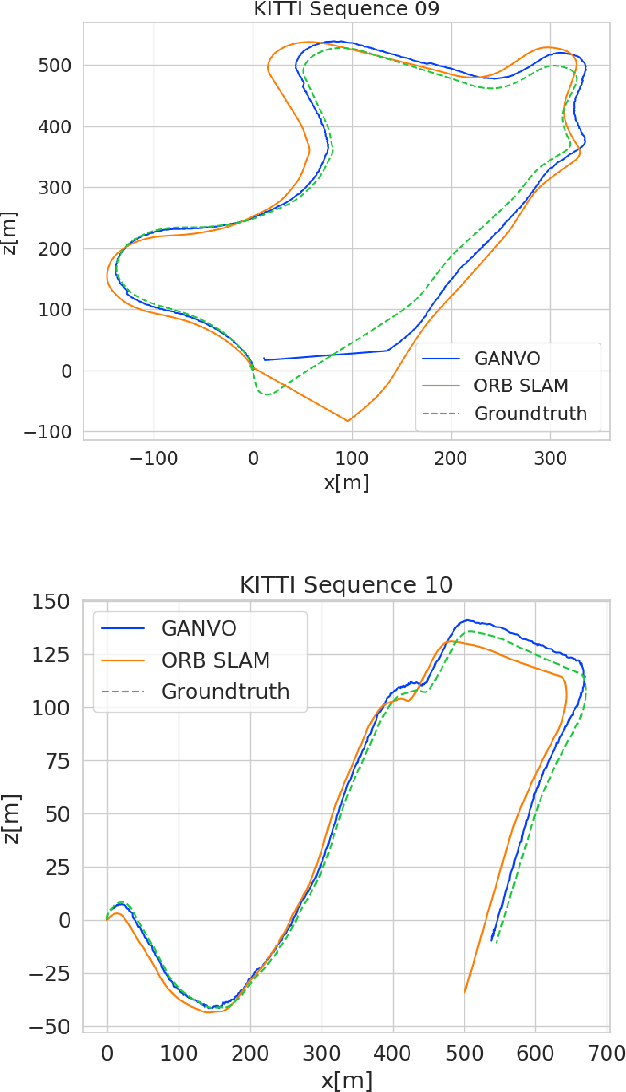

In the last decade, supervised deep learning approaches have been extensively employed in visual odometry (VO) applications, which is not feasible in environments where labelled data is not abundant. On the other hand, unsupervised deep learning approaches for localization and mapping in unknown environments from unlabelled data have received comparatively less attention in VO research. In this study, we propose a generative unsupervised learning framework that predicts 6-DoF pose camera motion and monocular depth map of the scene from unlabelled RGB image sequences, using deep convolutional Generative Adversarial Networks (GANs). We create a supervisory signal by warping view sequences and assigning the re-projection minimization to the objective loss function that is adopted in multi-view pose estimation and single-view depth generation network. Detailed quantitative and qualitative evaluations of the proposed framework on the KITTI and Cityscapes datasets show that the proposed method outperforms both existing traditional and unsupervised deep VO methods providing better results for both pose estimation and depth recovery.