 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Speech Recognition from Federated Acoustic Models
Paper and Code
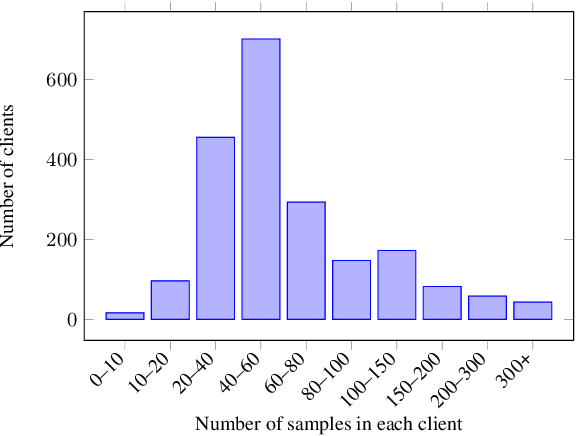

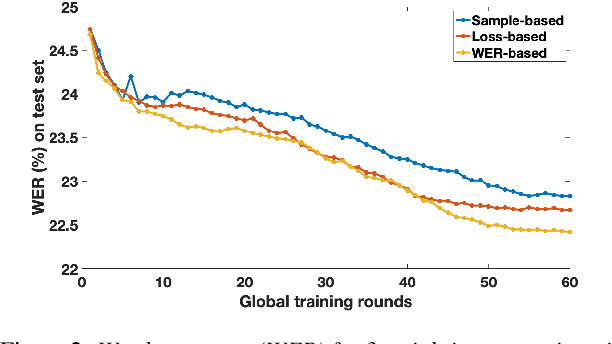
Training Automatic Speech Recognition (ASR) models under federated learning (FL) settings has recently attracted considerable attention. However, the FL scenarios often presented in the literature are artificial and fail to capture the complexity of real FL systems. In this paper, we construct a challenging and realistic ASR federated experimental setup consisting of clients with heterogeneous data distributions using the French Common Voice dataset, a large heterogeneous dataset containing over 10k speakers. We present the first empirical study on attention-based sequence-to-sequence E2E ASR model with three aggregation weighting strategies -- standard FedAvg, loss-based aggregation and a novel word error rate (WER)-based aggregation, are conducted in two realistic FL scenarios: cross-silo with 10-clients and cross-device with 2k-clients. In particular, the WER-based weighting method is proposed to better adapt FL to the context of ASR by integrating the error rate metric with the aggregation process. Our analysis on E2E ASR from heterogeneous and realistic federated acoustic models provides the foundations for future research and development of realistic FL-based ASR applications.