 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Speech-to-Text Translation with a SpeechLLM
May 14, 2026Normally, a system that translates speech into text consists of separate modules for speech recognition and text-to-text translation. Combining those tasks into a SpeechLLM promises to exploit paralinguistic information in the speech and to reduce cascaded errors. But existing SpeechLLM systems are slow since they do not work in a real streaming fashion: they wait for a complete utterance of audio before outputting a translation, or output tokens at fixed intervals, which is not suitable for real applications. This work proposes an LLM-based architecture for real streaming speech-to-text translation. The LLM learns not just to emit output tokens, but also to decide whether it has seen enough audio to do so. The system is trained using automatic alignments of the input speech and the output text. In experiments on different language pairs, the system achieves a translation quality close to the non-streaming baseline, but with a latency of only 1-2 seconds.
Multi-layer attentive probing improves transfer of audio representations for bioacoustics
May 11, 2026Probing heads map the representations learned from audio by a machine learning model to downstream task labels and are a key component in evaluating representation learning. Most bioacoustic benchmarks use a fixed, low-capacity probe, such as a linear layer on the final encoder layer. While this standardization enables model comparisons, it may bias results by overlooking the interaction between encoder features and probe design. In this work, we systematically study different probing strategies across two bioacoustic benchmarks, BEANs and BirdSet. We evaluate last- and multi-layer probing, across linear and attention probes. We show that larger probe heads that leverage time information have superior performance. Our results suggest that current benchmarks may misrepresent encoder quality when relying on a last-layer probing setup. Multi-layer probing improves downstream task performance across all tested models, while attention probing has superior performance to linear probing for transformer models.
A Study of Data Selection Strategies for Pre-training Self-Supervised Speech Models
Jan 28, 2026Self-supervised learning (SSL) has transformed speech processing, yet its reliance on massive pre-training datasets remains a bottleneck. While robustness is often attributed to scale and diversity, the role of the data distribution is less understood. We systematically examine how curated subsets of pre-training data influence Automatic Speech Recognition (ASR) performance. Surprisingly, optimizing for acoustic, speaker, or linguistic diversity yields no clear improvements over random sampling. Instead, we find that prioritizing the longest utterances achieves superior ASR results while using only half the original dataset, reducing pre-training time by 24% on a large corpora. These findings suggest that for pre-training speech SSL models, data length is a more critical factor than either data diversity or overall data quantity for performance and efficiency, offering a new perspective for data selection strategies in SSL speech processing.
Robust Unsupervised Adaptation of a Speech Recogniser Using Entropy Minimisation and Speaker Codes
Jun 12, 2025Speech recognisers usually perform optimally only in a specific environment and need to be adapted to work well in another. For adaptation to a new speaker, there is often too little data for fine-tuning to be robust, and that data is usually unlabelled. This paper proposes a combination of approaches to make adaptation to a single minute of data robust. First, instead of estimating the adaptation parameters with cross-entropy on a single error-prone hypothesis or "pseudo-label", this paper proposes a novel loss function, the conditional entropy over complete hypotheses. Using multiple hypotheses makes adaptation more robust to errors in the initial recognition. Second, a "speaker code" characterises a speaker in a vector short enough that it requires little data to estimate. On a far-field noise-augmented version of Common Voice, the proposed scheme yields a 20% relative improvement in word error rate on one minute of adaptation data, increasing on 10 minutes to 29%.
Evaluation of LLMs in Speech is Often Flawed: Test Set Contamination in Large Language Models for Speech Recognition
May 28, 2025Recent work suggests that large language models (LLMs) can improve performance of speech tasks compared to existing systems. To support their claims, results on LibriSpeech and Common Voice are often quoted. However, this work finds that a substantial amount of the LibriSpeech and Common Voice evaluation sets appear in public LLM pretraining corpora. This calls into question the reliability of findings drawn from these two datasets. To measure the impact of contamination, LLMs trained with or without contamination are compared, showing that a contaminated LLM is more likely to generate test sentences it has seen during training. Speech recognisers using contaminated LLMs shows only subtle differences in error rates, but assigns significantly higher probabilities to transcriptions seen during training. Results show that LLM outputs can be biased by tiny amounts of data contamination, highlighting the importance of evaluating LLM-based speech systems with held-out data.
Loquacious Set: 25,000 Hours of Transcribed and Diverse English Speech Recognition Data for Research and Commercial Use
May 27, 2025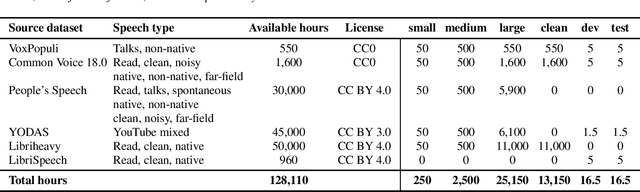
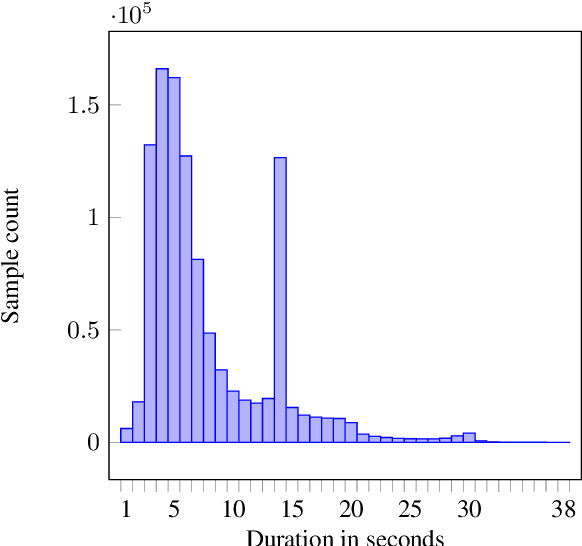
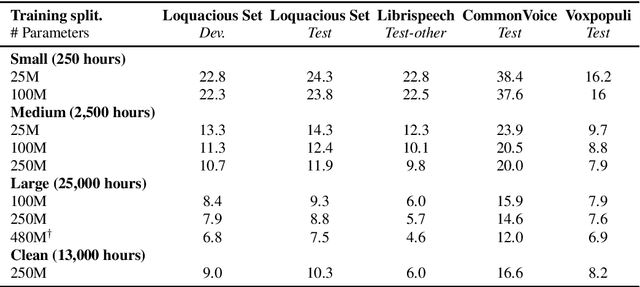
Automatic speech recognition (ASR) research is driven by the availability of common datasets between industrial researchers and academics, encouraging comparisons and evaluations. LibriSpeech, despite its long success as an ASR benchmark, is now limited by its size and focus on clean, read speech, leading to near-zero word error rates. More recent datasets, including MOSEL, YODAS, Gigaspeech, OWSM, Libriheavy or People's Speech suffer from major limitations including licenses that researchers in the industry cannot use, unreliable transcriptions, incorrect audio data, or the lack of evaluation sets. This work presents the Loquacious Set, a 25,000-hour curated collection of commercially usable English speech. Featuring hundreds of thousands of speakers with diverse accents and a wide range of speech types (read, spontaneous, talks, clean, noisy), the Loquacious Set is designed to work for academics and researchers in the industry to build ASR systems in real-world scenarios.
Benchmarking Rotary Position Embeddings for Automatic Speech Recognition
Jan 10, 2025Rotary Position Embedding (RoPE) encodes relative and absolute positional information in Transformer-based models through rotation matrices applied to input vectors within sequences. While RoPE has demonstrated superior performance compared to other positional embedding technologies in natural language processing tasks, its effectiveness in speech processing applications remains understudied. In this work, we conduct a comprehensive evaluation of RoPE across diverse automatic speech recognition (ASR) tasks. Our experimental results demonstrate that for ASR tasks, RoPE consistently achieves lower error rates compared to the currently widely used relative positional embedding. To facilitate further research, we release the implementation and all experimental recipes through the SpeechBrain toolkit.
Towards Early Prediction of Self-Supervised Speech Model Performance
Jan 10, 2025


In Self-Supervised Learning (SSL), pre-training and evaluation are resource intensive. In the speech domain, current indicators of the quality of SSL models during pre-training, such as the loss, do not correlate well with downstream performance. Consequently, it is often difficult to gauge the final downstream performance in a cost efficient manner during pre-training. In this work, we propose unsupervised efficient methods that give insights into the quality of the pre-training of SSL speech models, namely, measuring the cluster quality and rank of the embeddings of the SSL model. Results show that measures of cluster quality and rank correlate better with downstream performance than the pre-training loss with only one hour of unlabeled audio, reducing the need for GPU hours and labeled data in SSL model evaluation.
Linear Time Complexity Conformers with SummaryMixing for Streaming Speech Recognition
Sep 11, 2024


Automatic speech recognition (ASR) with an encoder equipped with self-attention, whether streaming or non-streaming, takes quadratic time in the length of the speech utterance. This slows down training and decoding, increase their cost, and limit the deployment of the ASR in constrained devices. SummaryMixing is a promising linear-time complexity alternative to self-attention for non-streaming speech recognition that, for the first time, preserves or outperforms the accuracy of self-attention models. Unfortunately, the original definition of SummaryMixing is not suited to streaming speech recognition. Hence, this work extends SummaryMixing to a Conformer Transducer that works in both a streaming and an offline mode. It shows that this new linear-time complexity speech encoder outperforms self-attention in both scenarios while requiring less compute and memory during training and decoding.
An Analysis of Linear Complexity Attention Substitutes with BEST-RQ
Sep 04, 2024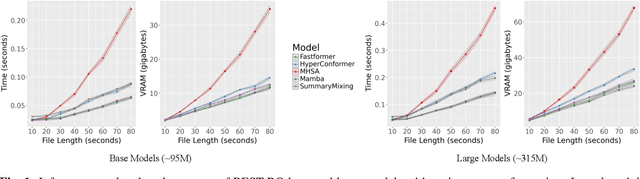
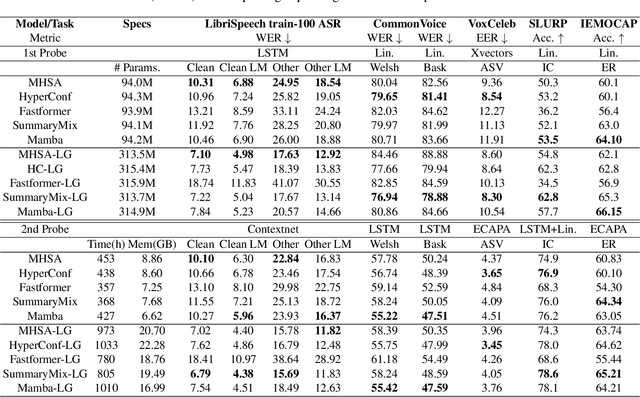
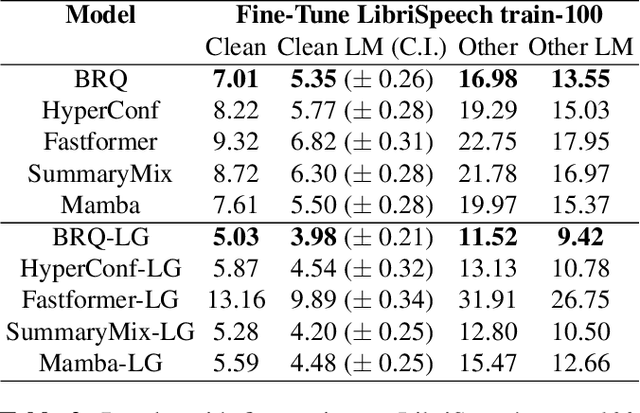
Self-Supervised Learning (SSL) has proven to be effective in various domains, including speech processing. However, SSL is computationally and memory expensive. This is in part due the quadratic complexity of multi-head self-attention (MHSA). Alternatives for MHSA have been proposed and used in the speech domain, but have yet to be investigated properly in an SSL setting. In this work, we study the effects of replacing MHSA with recent state-of-the-art alternatives that have linear complexity, namely, HyperMixing, Fastformer, SummaryMixing, and Mamba. We evaluate these methods by looking at the speed, the amount of VRAM consumed, and the performance on the SSL MP3S benchmark. Results show that these linear alternatives maintain competitive performance compared to MHSA while, on average, decreasing VRAM consumption by around 20% to 60% and increasing speed from 7% to 65% for input sequences ranging from 20 to 80 seconds.