 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchicalPrune: Position-Aware Compression for Large-Scale Diffusion Models
Aug 06, 2025State-of-the-art text-to-image diffusion models (DMs) achieve remarkable quality, yet their massive parameter scale (8-11B) poses significant challenges for inferences on resource-constrained devices. In this paper, we present HierarchicalPrune, a novel compression framework grounded in a key observation: DM blocks exhibit distinct functional hierarchies, where early blocks establish semantic structures while later blocks handle texture refinements. HierarchicalPrune synergistically combines three techniques: (1) Hierarchical Position Pruning, which identifies and removes less essential later blocks based on position hierarchy; (2) Positional Weight Preservation, which systematically protects early model portions that are essential for semantic structural integrity; and (3) Sensitivity-Guided Distillation, which adjusts knowledge-transfer intensity based on our discovery of block-wise sensitivity variations. As a result, our framework brings billion-scale diffusion models into a range more suitable for on-device inference, while preserving the quality of the output images. Specifically, when combined with INT4 weight quantisation, HierarchicalPrune achieves 77.5-80.4% memory footprint reduction (e.g., from 15.8 GB to 3.2 GB) and 27.9-38.0% latency reduction, measured on server and consumer grade GPUs, with the minimum drop of 2.6% in GenEval score and 7% in HPSv2 score compared to the original model. Last but not least, our comprehensive user study with 85 participants demonstrates that HierarchicalPrune maintains perceptual quality comparable to the original model while significantly outperforming prior works.
Robust Unsupervised Adaptation of a Speech Recogniser Using Entropy Minimisation and Speaker Codes
Jun 12, 2025Speech recognisers usually perform optimally only in a specific environment and need to be adapted to work well in another. For adaptation to a new speaker, there is often too little data for fine-tuning to be robust, and that data is usually unlabelled. This paper proposes a combination of approaches to make adaptation to a single minute of data robust. First, instead of estimating the adaptation parameters with cross-entropy on a single error-prone hypothesis or "pseudo-label", this paper proposes a novel loss function, the conditional entropy over complete hypotheses. Using multiple hypotheses makes adaptation more robust to errors in the initial recognition. Second, a "speaker code" characterises a speaker in a vector short enough that it requires little data to estimate. On a far-field noise-augmented version of Common Voice, the proposed scheme yields a 20% relative improvement in word error rate on one minute of adaptation data, increasing on 10 minutes to 29%.
Evaluation of LLMs in Speech is Often Flawed: Test Set Contamination in Large Language Models for Speech Recognition
May 28, 2025Recent work suggests that large language models (LLMs) can improve performance of speech tasks compared to existing systems. To support their claims, results on LibriSpeech and Common Voice are often quoted. However, this work finds that a substantial amount of the LibriSpeech and Common Voice evaluation sets appear in public LLM pretraining corpora. This calls into question the reliability of findings drawn from these two datasets. To measure the impact of contamination, LLMs trained with or without contamination are compared, showing that a contaminated LLM is more likely to generate test sentences it has seen during training. Speech recognisers using contaminated LLMs shows only subtle differences in error rates, but assigns significantly higher probabilities to transcriptions seen during training. Results show that LLM outputs can be biased by tiny amounts of data contamination, highlighting the importance of evaluating LLM-based speech systems with held-out data.
EDiT: Efficient Diffusion Transformers with Linear Compressed Attention
Mar 20, 2025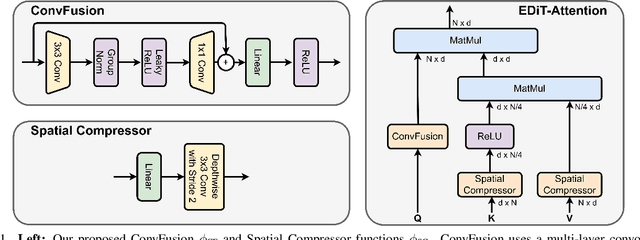
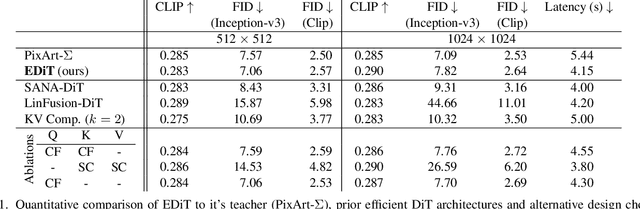
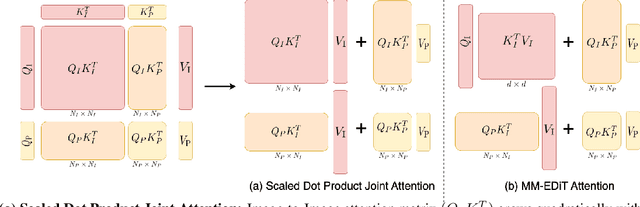
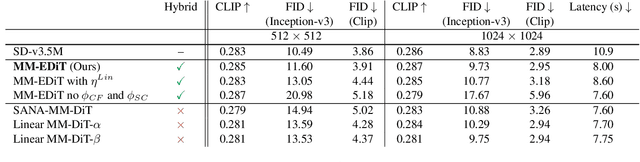
Diffusion Transformers (DiTs) have emerged as a leading architecture for text-to-image synthesis, producing high-quality and photorealistic images. However, the quadratic scaling properties of the attention in DiTs hinder image generation with higher resolution or on devices with limited resources. This work introduces an efficient diffusion transformer (EDiT) to alleviate these efficiency bottlenecks in conventional DiTs and Multimodal DiTs (MM-DiTs). First, we present a novel linear compressed attention method that uses a multi-layer convolutional network to modulate queries with local information while keys and values are spatially aggregated. Second, we formulate a hybrid attention scheme for multi-modal inputs that combines linear attention for image-to-image interactions and standard scaled dot-product attention for interactions involving prompts. Merging these two approaches leads to an expressive, linear-time Multimodal Efficient Diffusion Transformer (MM-EDiT). We demonstrate the effectiveness of the EDiT and MM-EDiT architectures by integrating them into PixArt-Sigma(conventional DiT) and Stable Diffusion 3.5-Medium (MM-DiT), achieving up to 2.2x speedup with comparable image quality after distillation.
Upcycling Text-to-Image Diffusion Models for Multi-Task Capabilities
Mar 14, 2025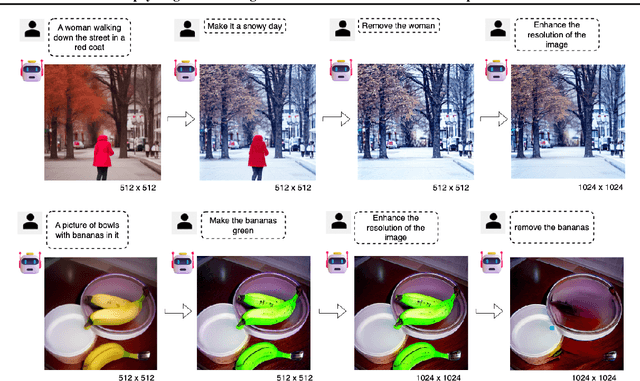
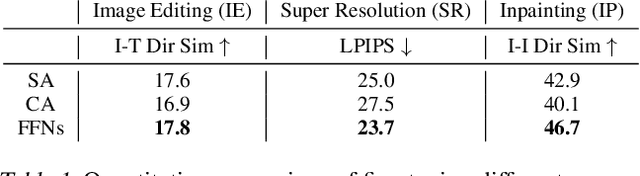
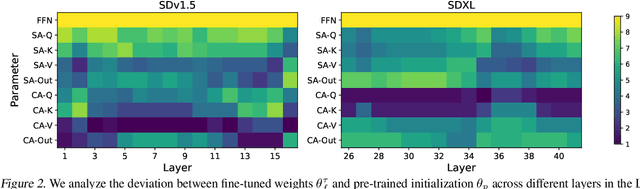
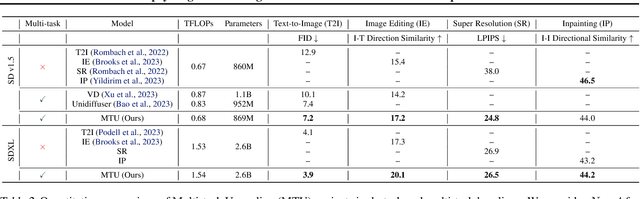
Text-to-image synthesis has witnessed remarkable advancements in recent years. Many attempts have been made to adopt text-to-image models to support multiple tasks. However, existing approaches typically require resource-intensive re-training or additional parameters to accommodate for the new tasks, which makes the model inefficient for on-device deployment. We propose Multi-Task Upcycling (MTU), a simple yet effective recipe that extends the capabilities of a pre-trained text-to-image diffusion model to support a variety of image-to-image generation tasks. MTU replaces Feed-Forward Network (FFN) layers in the diffusion model with smaller FFNs, referred to as experts, and combines them with a dynamic routing mechanism. To the best of our knowledge, MTU is the first multi-task diffusion modeling approach that seamlessly blends multi-tasking with on-device compatibility, by mitigating the issue of parameter inflation. We show that the performance of MTU is on par with the single-task fine-tuned diffusion models across several tasks including image editing, super-resolution, and inpainting, while maintaining similar latency and computational load (GFLOPs) as the single-task fine-tuned models.
Benchmarking Rotary Position Embeddings for Automatic Speech Recognition
Jan 10, 2025Rotary Position Embedding (RoPE) encodes relative and absolute positional information in Transformer-based models through rotation matrices applied to input vectors within sequences. While RoPE has demonstrated superior performance compared to other positional embedding technologies in natural language processing tasks, its effectiveness in speech processing applications remains understudied. In this work, we conduct a comprehensive evaluation of RoPE across diverse automatic speech recognition (ASR) tasks. Our experimental results demonstrate that for ASR tasks, RoPE consistently achieves lower error rates compared to the currently widely used relative positional embedding. To facilitate further research, we release the implementation and all experimental recipes through the SpeechBrain toolkit.
MobileQuant: Mobile-friendly Quantization for On-device Language Models
Aug 25, 2024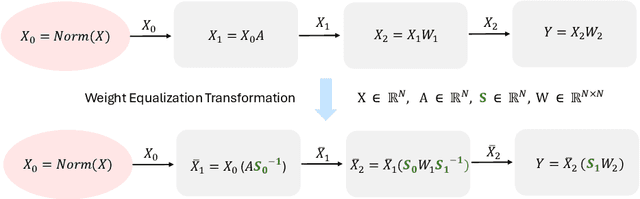
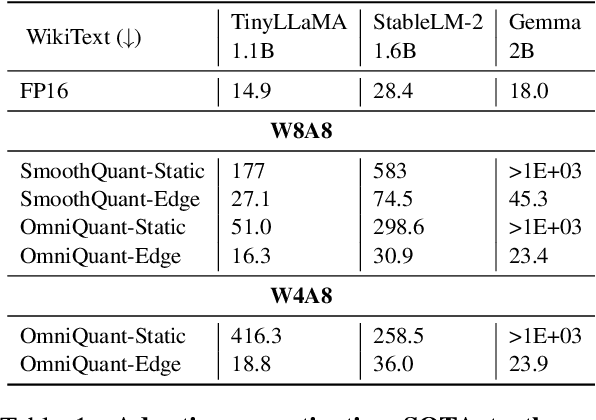

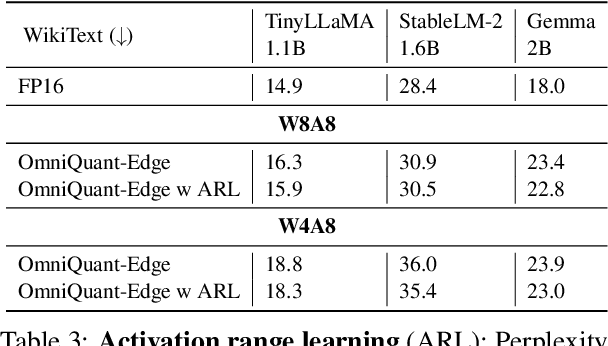
Large language models (LLMs) have revolutionized language processing, delivering outstanding results across multiple applications. However, deploying LLMs on edge devices poses several challenges with respect to memory, energy, and compute costs, limiting their widespread use in devices such as mobile phones. A promising solution is to reduce the number of bits used to represent weights and activations. While existing works have found partial success at quantizing LLMs to lower bitwidths, e.g. 4-bit weights, quantizing activations beyond 16 bits often leads to large computational overheads due to poor on-device quantization support, or a considerable accuracy drop. Yet, 8-bit activations are very attractive for on-device deployment as they would enable LLMs to fully exploit mobile-friendly hardware, e.g. Neural Processing Units (NPUs). In this work, we make a first attempt to facilitate the on-device deployment of LLMs using integer-only quantization. We first investigate the limitations of existing quantization methods for on-device deployment, with a special focus on activation quantization. We then address these limitations by introducing a simple post-training quantization method, named MobileQuant, that extends previous weight equivalent transformation works by jointly optimizing the weight transformation and activation range parameters in an end-to-end manner. MobileQuant demonstrates superior capabilities over existing methods by 1) achieving near-lossless quantization on a wide range of LLM benchmarks, 2) reducing latency and energy consumption by 20\%-50\% compared to current on-device quantization strategies, 3) requiring limited compute budget, 4) being compatible with mobile-friendly compute units, e.g. NPU.
Linear-Complexity Self-Supervised Learning for Speech Processing
Jul 18, 2024Self-supervised learning (SSL) models usually require weeks of pre-training with dozens of high-end GPUs. These models typically have a multi-headed self-attention (MHSA) context encoder. However, MHSA takes quadratic time and space in the input length, contributing to the high pre-training cost. Linear-complexity alternatives to MHSA have been proposed. For instance, in supervised training, the SummaryMixing model is the first to outperform MHSA across multiple speech processing tasks. However, these cheaper alternatives have not been explored for SSL yet. This paper studies a linear-complexity context encoder for SSL for the first time. With better or equivalent performance for the downstream tasks of the MP3S benchmark, SummaryMixing reduces the pre-training time and peak VRAM of wav2vec 2.0 model by 18% and by 23%, respectively, leading to the pre-training of a 155M wav2vec 2.0 model finished within one week with 4 Tesla A100 GPUs. Code is available at https://github.com/SamsungLabs/SummaryMixing.
Fast Inference Through The Reuse Of Attention Maps In Diffusion Models
Dec 13, 2023



Text-to-image diffusion models have demonstrated unprecedented abilities at flexible and realistic image synthesis. However, the iterative process required to produce a single image is costly and incurs a high latency, prompting researchers to further investigate its efficiency. Typically, improvements in latency have been achieved in two ways: (1) training smaller models through knowledge distillation (KD); and (2) adopting techniques from ODE-theory to facilitate larger step sizes. In contrast, we propose a training-free approach that does not alter the step-size of the sampler. Specifically, we find the repeated calculation of attention maps to be both costly and redundant; therefore, we propose a structured reuse of attention maps during sampling. Our initial reuse policy is motivated by rudimentary ODE-theory, which suggests that reuse is most suitable late in the sampling procedure. After noting a number of limitations in this theoretical approach, we empirically search for a better policy. Unlike methods that rely on KD, our reuse policies can easily be adapted to a variety of setups in a plug-and-play manner. Furthermore, when applied to Stable Diffusion-1.5, our reuse policies reduce latency with minimal repercussions on sample quality.
Sumformer: A Linear-Complexity Alternative to Self-Attention for Speech Recognition
Jul 12, 2023Modern speech recognition systems rely on self-attention. Unfortunately, token mixing with self-attention takes quadratic time in the length of the speech utterance, slowing down inference as well as training and increasing memory consumption. Cheaper alternatives to self-attention for ASR have been developed, but fail to consistently reach the same level of accuracy. In practice, however, the self-attention weights of trained speech recognizers take the form of a global average over time. This paper, therefore, proposes a linear-time alternative to self-attention for speech recognition. It summarises a whole utterance with the mean over vectors for all time steps. This single summary is then combined with time-specific information. We call this method ``Summary Mixing''. Introducing Summary Mixing in state-of-the-art ASR models makes it feasible to preserve or exceed previous speech recognition performance while lowering the training and inference times by up to 27% and reducing the memory budget by a factor of two.