 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDiT: Efficient Diffusion Transformers with Linear Compressed Attention
Paper and Code
Mar 20, 2025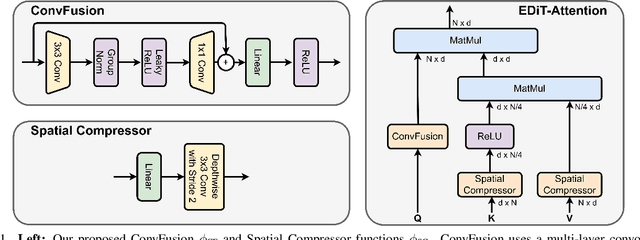
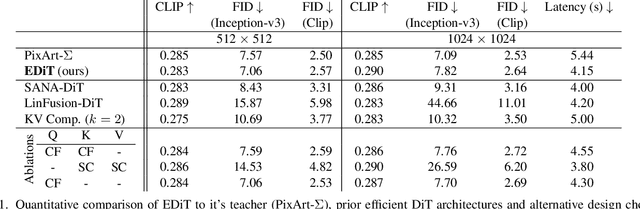
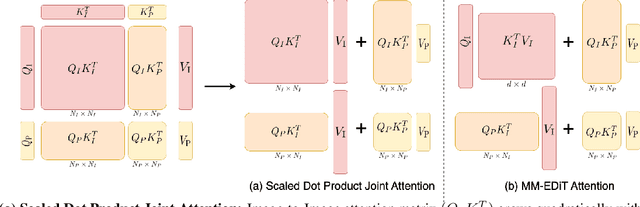
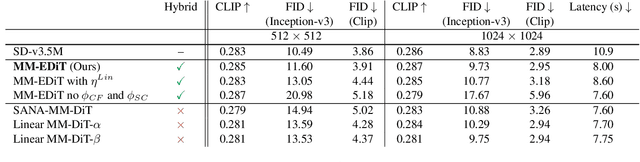
Diffusion Transformers (DiTs) have emerged as a leading architecture for text-to-image synthesis, producing high-quality and photorealistic images. However, the quadratic scaling properties of the attention in DiTs hinder image generation with higher resolution or on devices with limited resources. This work introduces an efficient diffusion transformer (EDiT) to alleviate these efficiency bottlenecks in conventional DiTs and Multimodal DiTs (MM-DiTs). First, we present a novel linear compressed attention method that uses a multi-layer convolutional network to modulate queries with local information while keys and values are spatially aggregated. Second, we formulate a hybrid attention scheme for multi-modal inputs that combines linear attention for image-to-image interactions and standard scaled dot-product attention for interactions involving prompts. Merging these two approaches leads to an expressive, linear-time Multimodal Efficient Diffusion Transformer (MM-EDiT). We demonstrate the effectiveness of the EDiT and MM-EDiT architectures by integrating them into PixArt-Sigma(conventional DiT) and Stable Diffusion 3.5-Medium (MM-DiT), achieving up to 2.2x speedup with comparable image quality after distillation.