 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Long-Range Interactions in Graph Neural Simulators via Hamiltonian Dynamics
Nov 11, 2025Learning to simulate complex physical systems from data has emerged as a promising way to overcome the limitations of traditional numerical solvers, which often require prohibitive computational costs for high-fidelity solutions. Recent Graph Neural Simulators (GNSs) accelerate simulations by learning dynamics on graph-structured data, yet often struggle to capture long-range interactions and suffer from error accumulation under autoregressive rollouts. To address these challenges, we propose Information-preserving Graph Neural Simulators (IGNS), a graph-based neural simulator built on the principles of Hamiltonian dynamics. This structure guarantees preservation of information across the graph, while extending to port-Hamiltonian systems allows the model to capture a broader class of dynamics, including non-conservative effects. IGNS further incorporates a warmup phase to initialize global context, geometric encoding to handle irregular meshes, and a multi-step training objective to reduce rollout error. To evaluate these properties systematically, we introduce new benchmarks that target long-range dependencies and challenging external forcing scenarios. Across all tasks, IGNS consistently outperforms state-of-the-art GNSs, achieving higher accuracy and stability under challenging and complex dynamical systems.
AMBER: Adaptive Mesh Generation by Iterative Mesh Resolution Prediction
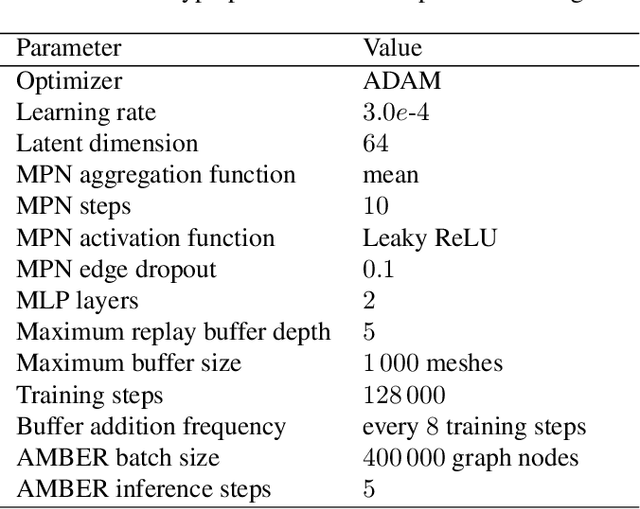
May 29, 2025The cost and accuracy of simulating complex physical systems using the Finite Element Method (FEM) scales with the resolution of the underlying mesh. Adaptive meshes improve computational efficiency by refining resolution in critical regions, but typically require task-specific heuristics or cumbersome manual design by a human expert. We propose Adaptive Meshing By Expert Reconstruction (AMBER), a supervised learning approach to mesh adaptation. Starting from a coarse mesh, AMBER iteratively predicts the sizing field, i.e., a function mapping from the geometry to the local element size of the target mesh, and uses this prediction to produce a new intermediate mesh using an out-of-the-box mesh generator. This process is enabled through a hierarchical graph neural network, and relies on data augmentation by automatically projecting expert labels onto AMBER-generated data during training. We evaluate AMBER on 2D and 3D datasets, including classical physics problems, mechanical components, and real-world industrial designs with human expert meshes. AMBER generalizes to unseen geometries and consistently outperforms multiple recent baselines, including ones using Graph and Convolutional Neural Networks, and Reinforcement Learning-based approaches.
EDiT: Efficient Diffusion Transformers with Linear Compressed Attention
Mar 20, 2025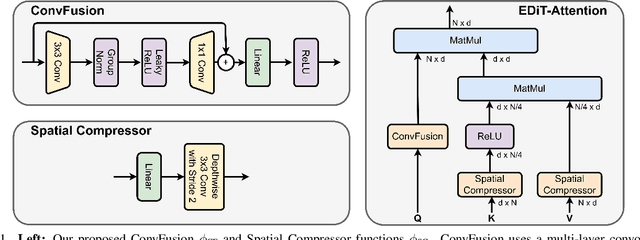
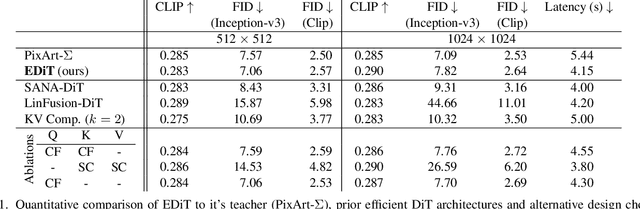
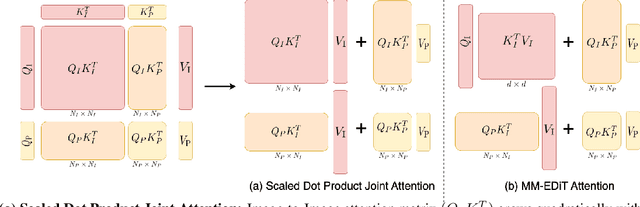
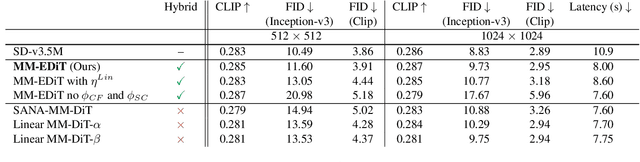
Diffusion Transformers (DiTs) have emerged as a leading architecture for text-to-image synthesis, producing high-quality and photorealistic images. However, the quadratic scaling properties of the attention in DiTs hinder image generation with higher resolution or on devices with limited resources. This work introduces an efficient diffusion transformer (EDiT) to alleviate these efficiency bottlenecks in conventional DiTs and Multimodal DiTs (MM-DiTs). First, we present a novel linear compressed attention method that uses a multi-layer convolutional network to modulate queries with local information while keys and values are spatially aggregated. Second, we formulate a hybrid attention scheme for multi-modal inputs that combines linear attention for image-to-image interactions and standard scaled dot-product attention for interactions involving prompts. Merging these two approaches leads to an expressive, linear-time Multimodal Efficient Diffusion Transformer (MM-EDiT). We demonstrate the effectiveness of the EDiT and MM-EDiT architectures by integrating them into PixArt-Sigma(conventional DiT) and Stable Diffusion 3.5-Medium (MM-DiT), achieving up to 2.2x speedup with comparable image quality after distillation.
Geometry-aware RL for Manipulation of Varying Shapes and Deformable Objects
Feb 12, 2025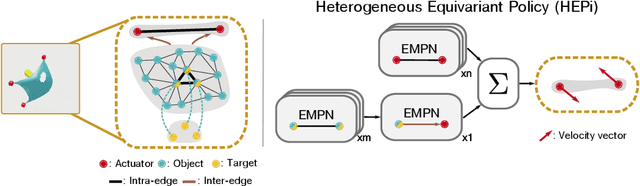

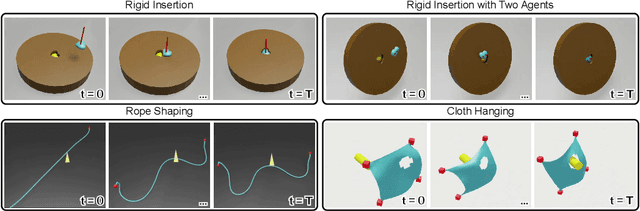
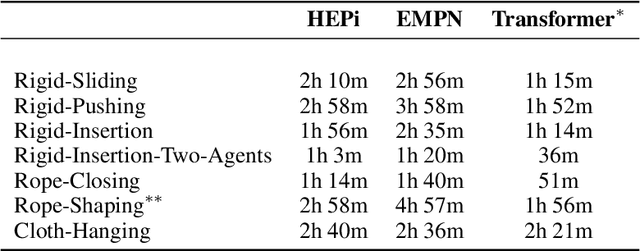
Manipulating objects with varying geometries and deformable objects is a major challenge in robotics. Tasks such as insertion with different objects or cloth hanging require precise control and effective modelling of complex dynamics. In this work, we frame this problem through the lens of a heterogeneous graph that comprises smaller sub-graphs, such as actuators and objects, accompanied by different edge types describing their interactions. This graph representation serves as a unified structure for both rigid and deformable objects tasks, and can be extended further to tasks comprising multiple actuators. To evaluate this setup, we present a novel and challenging reinforcement learning benchmark, including rigid insertion of diverse objects, as well as rope and cloth manipulation with multiple end-effectors. These tasks present a large search space, as both the initial and target configurations are uniformly sampled in 3D space. To address this issue, we propose a novel graph-based policy model, dubbed Heterogeneous Equivariant Policy (HEPi), utilizing $SE(3)$ equivariant message passing networks as the main backbone to exploit the geometric symmetry. In addition, by modeling explicit heterogeneity, HEPi can outperform Transformer-based and non-heterogeneous equivariant policies in terms of average returns, sample efficiency, and generalization to unseen objects.
Adaptive World Models: Learning Behaviors by Latent Imagination Under Non-Stationarity
Nov 02, 2024



Developing foundational world models is a key research direction for embodied intelligence, with the ability to adapt to non-stationary environments being a crucial criterion. In this work, we introduce a new formalism, Hidden Parameter-POMDP, designed for control with adaptive world models. We demonstrate that this approach enables learning robust behaviors across a variety of non-stationary RL benchmarks. Additionally, this formalism effectively learns task abstractions in an unsupervised manner, resulting in structured, task-aware latent spaces.
PointPatchRL -- Masked Reconstruction Improves Reinforcement Learning on Point Clouds
Oct 24, 2024



Perceiving the environment via cameras is crucial for Reinforcement Learning (RL) in robotics. While images are a convenient form of representation, they often complicate extracting important geometric details, especially with varying geometries or deformable objects. In contrast, point clouds naturally represent this geometry and easily integrate color and positional data from multiple camera views. However, while deep learning on point clouds has seen many recent successes, RL on point clouds is under-researched, with only the simplest encoder architecture considered in the literature. We introduce PointPatchRL (PPRL), a method for RL on point clouds that builds on the common paradigm of dividing point clouds into overlapping patches, tokenizing them, and processing the tokens with transformers. PPRL provides significant improvements compared with other point-cloud processing architectures previously used for RL. We then complement PPRL with masked reconstruction for representation learning and show that our method outperforms strong model-free and model-based baselines on image observations in complex manipulation tasks containing deformable objects and variations in target object geometry. Videos and code are available at https://alrhub.github.io/pprl-website
MuTT: A Multimodal Trajectory Transformer for Robot Skills
Jul 22, 2024



High-level robot skills represent an increasingly popular paradigm in robot programming. However, configuring the skills' parameters for a specific task remains a manual and time-consuming endeavor. Existing approaches for learning or optimizing these parameters often require numerous real-world executions or do not work in dynamic environments. To address these challenges, we propose MuTT, a novel encoder-decoder transformer architecture designed to predict environment-aware executions of robot skills by integrating vision, trajectory, and robot skill parameters. Notably, we pioneer the fusion of vision and trajectory, introducing a novel trajectory projection. Furthermore, we illustrate MuTT's efficacy as a predictor when combined with a model-based robot skill optimizer. This approach facilitates the optimization of robot skill parameters for the current environment, without the need for real-world executions during optimization. Designed for compatibility with any representation of robot skills, MuTT demonstrates its versatility across three comprehensive experiments, showcasing superior performance across two different skill representations.
KalMamba: Towards Efficient Probabilistic State Space Models for RL under Uncertainty
Jun 21, 2024



Probabilistic State Space Models (SSMs) are essential for Reinforcement Learning (RL) from high-dimensional, partial information as they provide concise representations for control. Yet, they lack the computational efficiency of their recent deterministic counterparts such as S4 or Mamba. We propose KalMamba, an efficient architecture to learn representations for RL that combines the strengths of probabilistic SSMs with the scalability of deterministic SSMs. KalMamba leverages Mamba to learn the dynamics parameters of a linear Gaussian SSM in a latent space. Inference in this latent space amounts to standard Kalman filtering and smoothing. We realize these operations using parallel associative scanning, similar to Mamba, to obtain a principled, highly efficient, and scalable probabilistic SSM. Our experiments show that KalMamba competes with state-of-the-art SSM approaches in RL while significantly improving computational efficiency, especially on longer interaction sequences.
Iterative Sizing Field Prediction for Adaptive Mesh Generation From Expert Demonstrations
Jun 20, 2024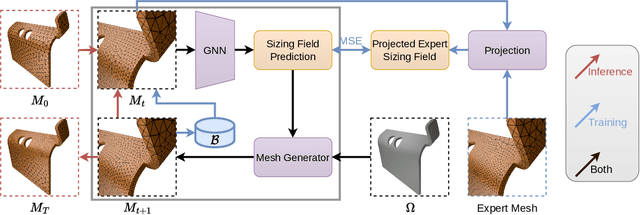
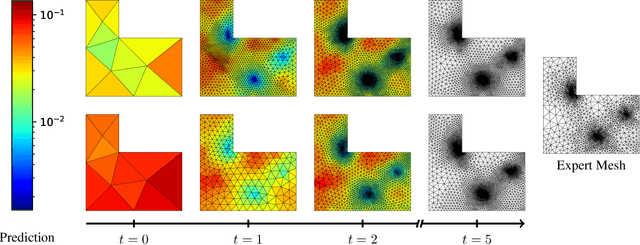
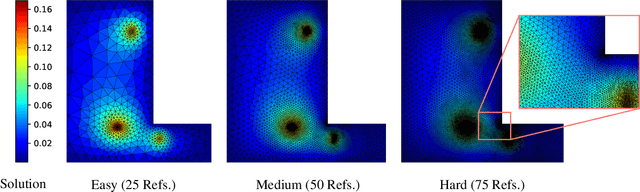
Many engineering systems require accurate simulations of complex physical systems. Yet, analytical solutions are only available for simple problems, necessitating numerical approximations such as the Finite Element Method (FEM). The cost and accuracy of the FEM scale with the resolution of the underlying computational mesh. To balance computational speed and accuracy meshes with adaptive resolution are used, allocating more resources to critical parts of the geometry. Currently, practitioners often resort to hand-crafted meshes, which require extensive expert knowledge and are thus costly to obtain. Our approach, Adaptive Meshing By Expert Reconstruction (AMBER), views mesh generation as an imitation learning problem. AMBER combines a graph neural network with an online data acquisition scheme to predict the projected sizing field of an expert mesh on a given intermediate mesh, creating a more accurate subsequent mesh. This iterative process ensures efficient and accurate imitation of expert mesh resolutions on arbitrary new geometries during inference. We experimentally validate AMBER on heuristic 2D meshes and 3D meshes provided by a human expert, closely matching the provided demonstrations and outperforming a single-step CNN baseline.
Vlearn: Off-Policy Learning with Efficient State-Value Function Estimation
Mar 07, 2024



Existing off-policy reinforcement learning algorithms typically necessitate an explicit state-action-value function representation, which becomes problematic in high-dimensional action spaces. These algorithms often encounter challenges where they struggle with the curse of dimensionality, as maintaining a state-action-value function in such spaces becomes data-inefficient. In this work, we propose a novel off-policy trust region optimization approach, called Vlearn, that eliminates the requirement for an explicit state-action-value function. Instead, we demonstrate how to efficiently leverage just a state-value function as the critic, thus overcoming several limitations of existing methods. By doing so, Vlearn addresses the computational challenges posed by high-dimensional action spaces. Furthermore, Vlearn introduces an efficient approach to address the challenges associated with pure state-value function learning in the off-policy setting. This approach not only simplifies the implementation of off-policy policy gradient algorithms but also leads to consistent and robust performance across various benchmark tasks. Specifically, by removing the need for a state-action-value function Vlearn simplifies the learning process and allows for more efficient exploration and exploitation in complex environments