 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive World Models: Learning Behaviors by Latent Imagination Under Non-Stationarity
Nov 02, 2024



Developing foundational world models is a key research direction for embodied intelligence, with the ability to adapt to non-stationary environments being a crucial criterion. In this work, we introduce a new formalism, Hidden Parameter-POMDP, designed for control with adaptive world models. We demonstrate that this approach enables learning robust behaviors across a variety of non-stationary RL benchmarks. Additionally, this formalism effectively learns task abstractions in an unsupervised manner, resulting in structured, task-aware latent spaces.
Learning World Models With Hierarchical Temporal Abstractions: A Probabilistic Perspective
Apr 26, 2024Machines that can replicate human intelligence with type 2 reasoning capabilities should be able to reason at multiple levels of spatio-temporal abstractions and scales using internal world models. Devising formalisms to develop such internal world models, which accurately reflect the causal hierarchies inherent in the dynamics of the real world, is a critical research challenge in the domains of artificial intelligence and machine learning. This thesis identifies several limitations with the prevalent use of state space models (SSMs) as internal world models and propose two new probabilistic formalisms namely Hidden-Parameter SSMs and Multi-Time Scale SSMs to address these drawbacks. The structure of graphical models in both formalisms facilitates scalable exact probabilistic inference using belief propagation, as well as end-to-end learning via backpropagation through time. This approach permits the development of scalable, adaptive hierarchical world models capable of representing nonstationary dynamics across multiple temporal abstractions and scales. Moreover, these probabilistic formalisms integrate the concept of uncertainty in world states, thus improving the system's capacity to emulate the stochastic nature of the real world and quantify the confidence in its predictions. The thesis also discuss how these formalisms are in line with related neuroscience literature on Bayesian brain hypothesis and predicitive processing. Our experiments on various real and simulated robots demonstrate that our formalisms can match and in many cases exceed the performance of contemporary transformer variants in making long-range future predictions. We conclude the thesis by reflecting on the limitations of our current models and suggesting directions for future research.
Multi Time Scale World Models
Oct 27, 2023



Intelligent agents use internal world models to reason and make predictions about different courses of their actions at many scales. Devising learning paradigms and architectures that allow machines to learn world models that operate at multiple levels of temporal abstractions while dealing with complex uncertainty predictions is a major technical hurdle. In this work, we propose a probabilistic formalism to learn multi-time scale world models which we call the Multi Time Scale State Space (MTS3) model. Our model uses a computationally efficient inference scheme on multiple time scales for highly accurate long-horizon predictions and uncertainty estimates over several seconds into the future. Our experiments, which focus on action conditional long horizon future predictions, show that MTS3 outperforms recent methods on several system identification benchmarks including complex simulated and real-world dynamical systems.
Hidden Parameter Recurrent State Space Models For Changing Dynamics Scenarios
Jun 29, 2022

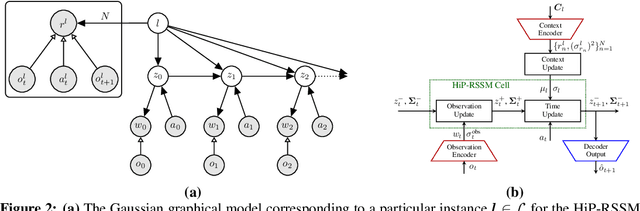
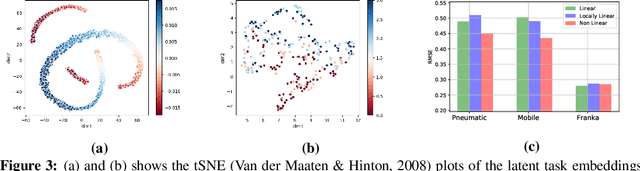
Recurrent State-space models (RSSMs) are highly expressive models for learning patterns in time series data and system identification. However, these models assume that the dynamics are fixed and unchanging, which is rarely the case in real-world scenarios. Many control applications often exhibit tasks with similar but not identical dynamics which can be modeled as a latent variable. We introduce the Hidden Parameter Recurrent State Space Models (HiP-RSSMs), a framework that parametrizes a family of related dynamical systems with a low-dimensional set of latent factors. We present a simple and effective way of learning and performing inference over this Gaussian graphical model that avoids approximations like variational inference. We show that HiP-RSSMs outperforms RSSMs and competing multi-task models on several challenging robotic benchmarks both on real-world systems and simulations.
End-to-End Learning of Hybrid Inverse Dynamics Models for Precise and Compliant Impedance Control
May 27, 2022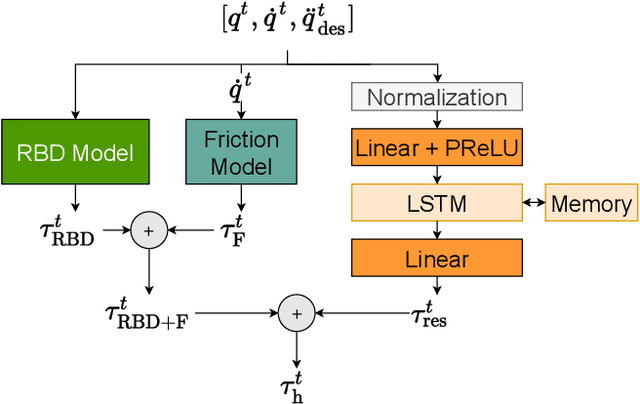
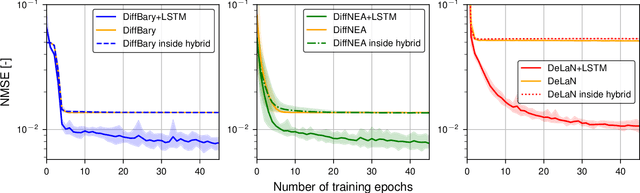
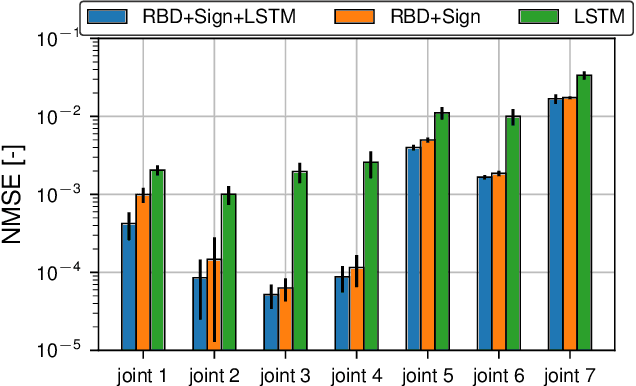
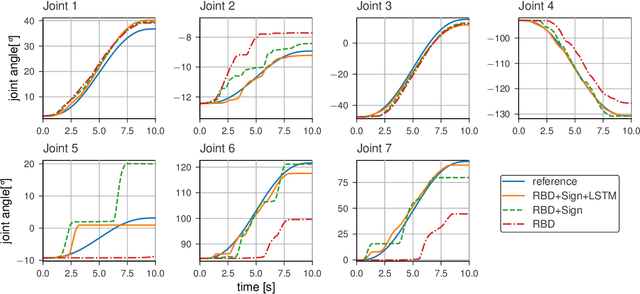
It is well-known that inverse dynamics models can improve tracking performance in robot control. These models need to precisely capture the robot dynamics, which consist of well-understood components, e.g., rigid body dynamics, and effects that remain challenging to capture, e.g., stick-slip friction and mechanical flexibilities. Such effects exhibit hysteresis and partial observability, rendering them, particularly challenging to model. Hence, hybrid models, which combine a physical prior with data-driven approaches are especially well-suited in this setting. We present a novel hybrid model formulation that enables us to identify fully physically consistent inertial parameters of a rigid body dynamics model which is paired with a recurrent neural network architecture, allowing us to capture unmodeled partially observable effects using the network memory. We compare our approach against state-of-the-art inverse dynamics models on a 7 degree of freedom manipulator. Using data sets obtained through an optimal experiment design approach, we study the accuracy of offline torque prediction and generalization capabilities of joint learning methods. In control experiments on the real system, we evaluate the model as a feed-forward term for impedance control and show the feedback gains can be drastically reduced to achieve a given tracking accuracy.
Action-Conditional Recurrent Kalman Networks For Forward and Inverse Dynamics Learning
Nov 05, 2020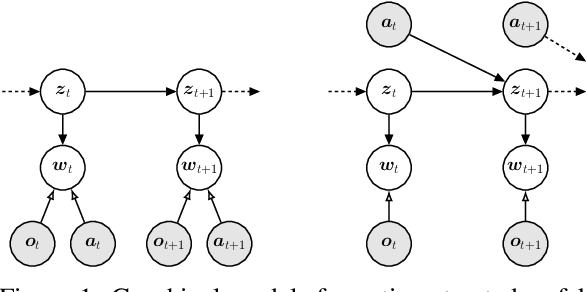

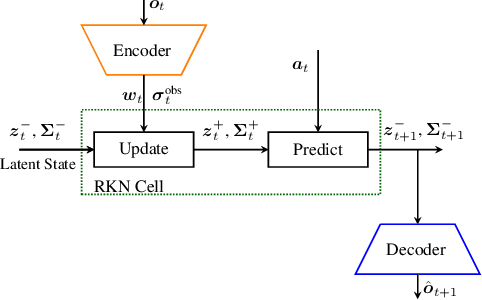

Estimating accurate forward and inverse dynamics models is a crucial component of model-based control for sophisticated robots such as robots driven by hydraulics, artificial muscles, or robots dealing with different contact situations. Analytic models to such processes are often unavailable or inaccurate due to complex hysteresis effects, unmodelled friction and stiction phenomena,and unknown effects during contact situations. A promising approach is to obtain spatio-temporal models in a data-driven way using recurrent neural networks, as they can overcome those issues. However, such models often do not meet accuracy demands sufficiently, degenerate in performance for the required high sampling frequencies and cannot provide uncertainty estimates. We adopt a recent probabilistic recurrent neural network architecture, called Re-current Kalman Networks (RKNs), to model learning by conditioning its transition dynamics on the control actions. RKNs outperform standard recurrent networks such as LSTMs on many state estimation tasks. Inspired by Kalman filters, the RKN provides an elegant way to achieve action conditioning within its recurrent cell by leveraging additive interactions between the current latent state and the action variables. We present two architectures, one for forward model learning and one for inverse model learning. Both architectures significantly outperform exist-ing model learning frameworks as well as analytical models in terms of prediction performance on a variety of real robot dynamics models.
Adversarial Fooling Beyond "Flipping the Label"
Apr 27, 2020
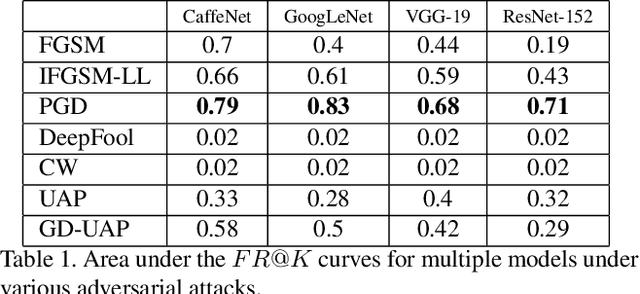


Recent advancements in CNNs have shown remarkable achievements in various CV/AI applications. Though CNNs show near human or better than human performance in many critical tasks, they are quite vulnerable to adversarial attacks. These attacks are potentially dangerous in real-life deployments. Though there have been many adversarial attacks proposed in recent years, there is no proper way of quantifying the effectiveness of these attacks. As of today, mere fooling rate is used for measuring the susceptibility of the models, or the effectiveness of adversarial attacks. Fooling rate just considers label flipping and does not consider the cost of such flipping, for instance, in some deployments, flipping between two species of dogs may not be as severe as confusing a dog category with that of a vehicle. Therefore, the metric to quantify the vulnerability of the models should capture the severity of the flipping as well. In this work we first bring out the drawbacks of the existing evaluation and propose novel metrics to capture various aspects of the fooling. Further, for the first time, we present a comprehensive analysis of several important adversarial attacks over a set of distinct CNN architectures. We believe that the presented analysis brings valuable insights about the current adversarial attacks and the CNN models.
Zero-Shot Knowledge Distillation in Deep Networks
May 20, 2019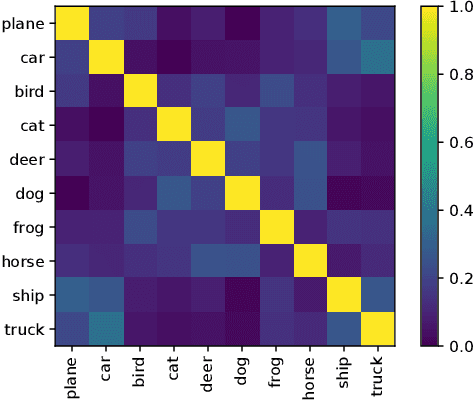


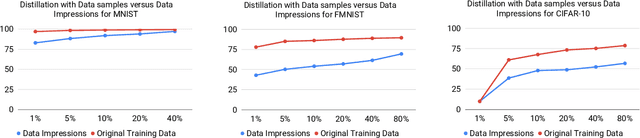
Knowledge distillation deals with the problem of training a smaller model (Student) from a high capacity source model (Teacher) so as to retain most of its performance. Existing approaches use either the training data or meta-data extracted from it in order to train the Student. However, accessing the dataset on which the Teacher has been trained may not always be feasible if the dataset is very large or it poses privacy or safety concerns (e.g., bio-metric or medical data). Hence, in this paper, we propose a novel data-free method to train the Student from the Teacher. Without even using any meta-data, we synthesize the Data Impressions from the complex Teacher model and utilize these as surrogates for the original training data samples to transfer its learning to Student via knowledge distillation. We, therefore, dub our method "Zero-Shot Knowledge Distillation" and demonstrate that our framework results in competitive generalization performance as achieved by distillation using the actual training data samples on multiple benchmark datasets.
Learning Sparse Adversarial Dictionaries For Multi-Class Audio Classification
Dec 02, 2017

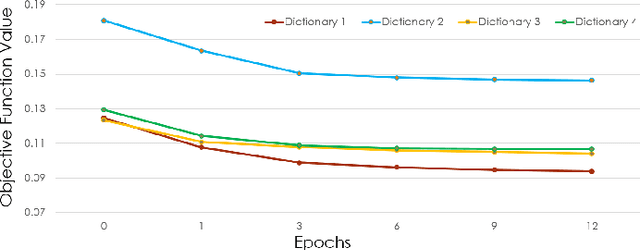

Audio events are quite often overlapping in nature, and more prone to noise than visual signals. There has been increasing evidence for the superior performance of representations learned using sparse dictionaries for applications like audio denoising and speech enhancement. This paper concentrates on modifying the traditional reconstructive dictionary learning algorithms, by incorporating a discriminative term into the objective function in order to learn class-specific adversarial dictionaries that are good at representing samples of their own class at the same time poor at representing samples belonging to any other class. We quantitatively demonstrate the effectiveness of our learned dictionaries as a stand-alone solution for both binary as well as multi-class audio classification problems.