 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Fooling Beyond "Flipping the Label"
Paper and Code
Apr 27, 2020
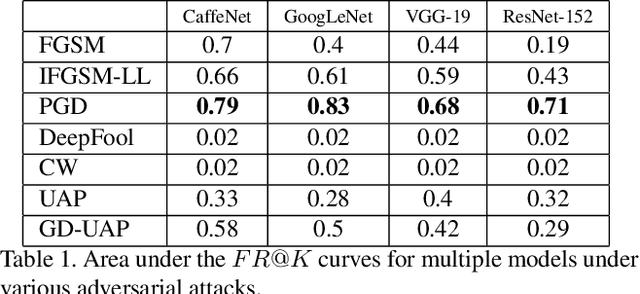


Recent advancements in CNNs have shown remarkable achievements in various CV/AI applications. Though CNNs show near human or better than human performance in many critical tasks, they are quite vulnerable to adversarial attacks. These attacks are potentially dangerous in real-life deployments. Though there have been many adversarial attacks proposed in recent years, there is no proper way of quantifying the effectiveness of these attacks. As of today, mere fooling rate is used for measuring the susceptibility of the models, or the effectiveness of adversarial attacks. Fooling rate just considers label flipping and does not consider the cost of such flipping, for instance, in some deployments, flipping between two species of dogs may not be as severe as confusing a dog category with that of a vehicle. Therefore, the metric to quantify the vulnerability of the models should capture the severity of the flipping as well. In this work we first bring out the drawbacks of the existing evaluation and propose novel metrics to capture various aspects of the fooling. Further, for the first time, we present a comprehensive analysis of several important adversarial attacks over a set of distinct CNN architectures. We believe that the presented analysis brings valuable insights about the current adversarial attacks and the CNN models.