 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAR: Sample Efficient Action Chunking Reinforcement Learning
Mar 02, 2026Action chunking can improve exploration and value estimation in long horizon reinforcement learning, but makes learning substantially harder since the critic must evaluate action sequences rather than single actions, greatly increasing approximation and data efficiency challenges. As a result, existing action chunking methods, primarily designed for the offline and offline-to-online settings, have not achieved strong performance in purely online reinforcement learning. We introduce SEAR, an off policy online reinforcement learning algorithm for action chunking. It exploits the temporal structure of action chunks and operates with a receding horizon, effectively combining the benefits of small and large chunk sizes. SEAR outperforms state of the art online reinforcement learning methods on Metaworld, training with chunk sizes up to 20.
Bridge Matching Sampler: Scalable Sampling via Generalized Fixed-Point Diffusion Matching
Feb 28, 2026Sampling from unnormalized densities using diffusion models has emerged as a powerful paradigm. However, while recent approaches that use least-squares `matching' objectives have improved scalability, they often necessitate significant trade-offs, such as restricting prior distributions or relying on unstable optimization schemes. By generalizing these methods as special forms of fixed-point iterations rooted in Nelson's relation, we develop a new method that addresses these limitations, called Bridge Matching Sampler (BMS). Our approach enables learning a stochastic transport map between arbitrary prior and target distributions with a single, scalable, and stable objective. Furthermore, we introduce a damped variant of this iteration that incorporates a regularization term to mitigate mode collapse and further stabilize training. Empirically, we demonstrate that our method enables sampling at unprecedented scales while preserving mode diversity, achieving state-of-the-art results on complex synthetic densities and high-dimensional molecular benchmarks.
Can Neural Networks Provide Latent Embeddings for Telemetry-Aware Greedy Routing?
Feb 13, 2026Telemetry-Aware routing promises to increase efficacy and responsiveness to traffic surges in computer networks. Recent research leverages Machine Learning to deal with the complex dependency between network state and routing, but sacrifices explainability of routing decisions due to the black-box nature of the proposed neural routing modules. We propose \emph{Placer}, a novel algorithm using Message Passing Networks to transform network states into latent node embeddings. These embeddings facilitate quick greedy next-hop routing without directly solving the all-pairs shortest paths problem, and let us visualize how certain network events shape routing decisions.
Robot-DIFT: Distilling Diffusion Features for Geometrically Consistent Visuomotor Control
Feb 12, 2026We hypothesize that a key bottleneck in generalizable robot manipulation is not solely data scale or policy capacity, but a structural mismatch between current visual backbones and the physical requirements of closed-loop control. While state-of-the-art vision encoders (including those used in VLAs) optimize for semantic invariance to stabilize classification, manipulation typically demands geometric sensitivity the ability to map millimeter-level pose shifts to predictable feature changes. Their discriminative objective creates a "blind spot" for fine-grained control, whereas generative diffusion models inherently encode geometric dependencies within their latent manifolds, encouraging the preservation of dense multi-scale spatial structure. However, directly deploying stochastic diffusion features for control is hindered by stochastic instability, inference latency, and representation drift during fine-tuning. To bridge this gap, we propose Robot-DIFT, a framework that decouples the source of geometric information from the process of inference via Manifold Distillation. By distilling a frozen diffusion teacher into a deterministic Spatial-Semantic Feature Pyramid Network (S2-FPN), we retain the rich geometric priors of the generative model while ensuring temporal stability, real-time execution, and robustness against drift. Pretrained on the large-scale DROID dataset, Robot-DIFT demonstrates superior geometric consistency and control performance compared to leading discriminative baselines, supporting the view that how a model learns to see dictates how well it can learn to act.
Graph Recognition via Subgraph Prediction
Jan 21, 2026Despite tremendous improvements in tasks such as image classification, object detection, and segmentation, the recognition of visual relationships, commonly modeled as the extraction of a graph from an image, remains a challenging task. We believe that this mainly stems from the fact that there is no canonical way to approach the visual graph recognition task. Most existing solutions are specific to a problem and cannot be transferred between different contexts out-of-the box, even though the conceptual problem remains the same. With broad applicability and simplicity in mind, in this paper we develop a method, \textbf{Gra}ph Recognition via \textbf{S}ubgraph \textbf{P}rediction (\textbf{GraSP}), for recognizing graphs in images. We show across several synthetic benchmarks and one real-world application that our method works with a set of diverse types of graphs and their drawings, and can be transferred between tasks without task-specific modifications, paving the way to a more unified framework for visual graph recognition.
Improving Long-Range Interactions in Graph Neural Simulators via Hamiltonian Dynamics
Nov 11, 2025Learning to simulate complex physical systems from data has emerged as a promising way to overcome the limitations of traditional numerical solvers, which often require prohibitive computational costs for high-fidelity solutions. Recent Graph Neural Simulators (GNSs) accelerate simulations by learning dynamics on graph-structured data, yet often struggle to capture long-range interactions and suffer from error accumulation under autoregressive rollouts. To address these challenges, we propose Information-preserving Graph Neural Simulators (IGNS), a graph-based neural simulator built on the principles of Hamiltonian dynamics. This structure guarantees preservation of information across the graph, while extending to port-Hamiltonian systems allows the model to capture a broader class of dynamics, including non-conservative effects. IGNS further incorporates a warmup phase to initialize global context, geometric encoding to handle irregular meshes, and a multi-step training objective to reduce rollout error. To evaluate these properties systematically, we introduce new benchmarks that target long-range dependencies and challenging external forcing scenarios. Across all tasks, IGNS consistently outperforms state-of-the-art GNSs, achieving higher accuracy and stability under challenging and complex dynamical systems.
Context-aware Learned Mesh-based Simulation via Trajectory-Level Meta-Learning
Nov 07, 2025Simulating object deformations is a critical challenge across many scientific domains, including robotics, manufacturing, and structural mechanics. Learned Graph Network Simulators (GNSs) offer a promising alternative to traditional mesh-based physics simulators. Their speed and inherent differentiability make them particularly well suited for applications that require fast and accurate simulations, such as robotic manipulation or manufacturing optimization. However, existing learned simulators typically rely on single-step observations, which limits their ability to exploit temporal context. Without this information, these models fail to infer, e.g., material properties. Further, they rely on auto-regressive rollouts, which quickly accumulate error for long trajectories. We instead frame mesh-based simulation as a trajectory-level meta-learning problem. Using Conditional Neural Processes, our method enables rapid adaptation to new simulation scenarios from limited initial data while capturing their latent simulation properties. We utilize movement primitives to directly predict fast, stable and accurate simulations from a single model call. The resulting approach, Movement-primitive Meta-MeshGraphNet (M3GN), provides higher simulation accuracy at a fraction of the runtime cost compared to state-of-the-art GNSs across several tasks.
Towards a Multi-Embodied Grasping Agent
Oct 31, 2025Multi-embodiment grasping focuses on developing approaches that exhibit generalist behavior across diverse gripper designs. Existing methods often learn the kinematic structure of the robot implicitly and face challenges due to the difficulty of sourcing the required large-scale data. In this work, we present a data-efficient, flow-based, equivariant grasp synthesis architecture that can handle different gripper types with variable degrees of freedom and successfully exploit the underlying kinematic model, deducing all necessary information solely from the gripper and scene geometry. Unlike previous equivariant grasping methods, we translated all modules from the ground up to JAX and provide a model with batching capabilities over scenes, grippers, and grasps, resulting in smoother learning, improved performance and faster inference time. Our dataset encompasses grippers ranging from humanoid hands to parallel yaw grippers and includes 25,000 scenes and 20 million grasps.
PointMapPolicy: Structured Point Cloud Processing for Multi-Modal Imitation Learning
Oct 23, 2025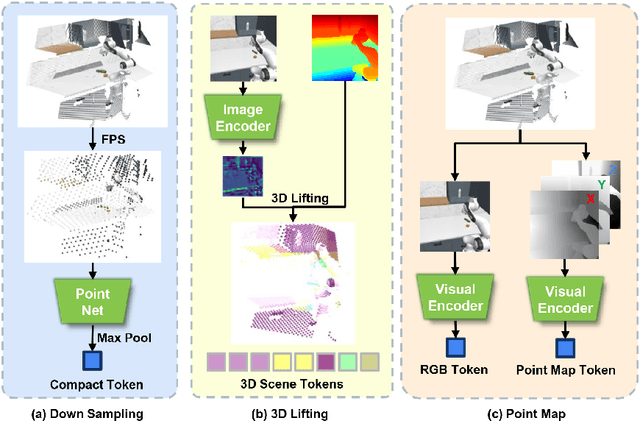
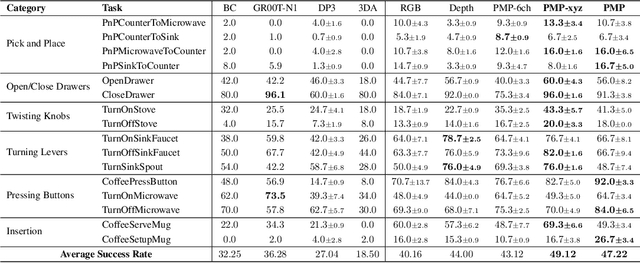
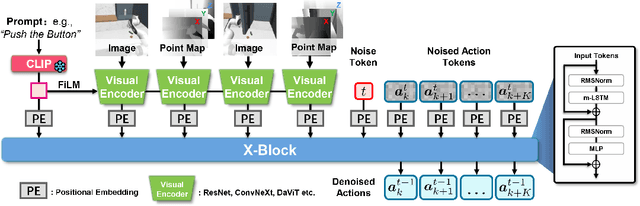
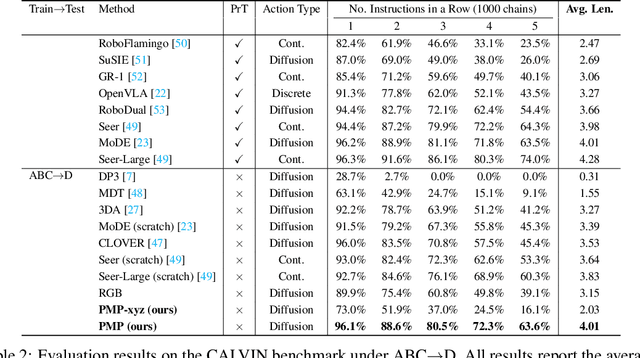
Robotic manipulation systems benefit from complementary sensing modalities, where each provides unique environmental information. Point clouds capture detailed geometric structure, while RGB images provide rich semantic context. Current point cloud methods struggle to capture fine-grained detail, especially for complex tasks, which RGB methods lack geometric awareness, which hinders their precision and generalization. We introduce PointMapPolicy, a novel approach that conditions diffusion policies on structured grids of points without downsampling. The resulting data type makes it easier to extract shape and spatial relationships from observations, and can be transformed between reference frames. Yet due to their structure in a regular grid, we enable the use of established computer vision techniques directly to 3D data. Using xLSTM as a backbone, our model efficiently fuses the point maps with RGB data for enhanced multi-modal perception. Through extensive experiments on the RoboCasa and CALVIN benchmarks and real robot evaluations, we demonstrate that our method achieves state-of-the-art performance across diverse manipulation tasks. The overview and demos are available on our project page: https://point-map.github.io/Point-Map/
Trust Region Constrained Measure Transport in Path Space for Stochastic Optimal Control and Inference
Aug 17, 2025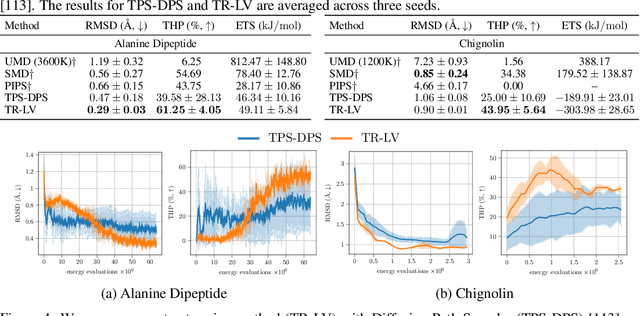
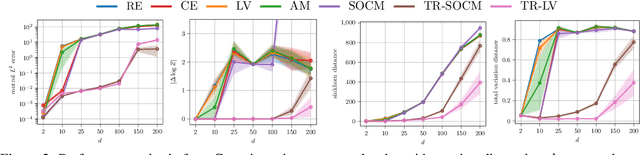
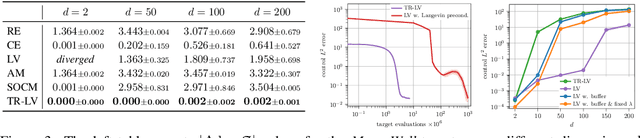
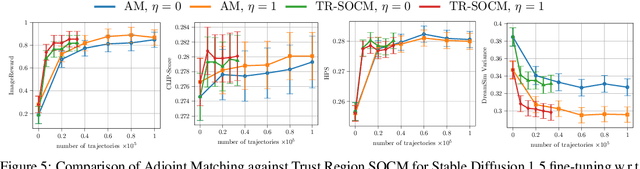
Solving stochastic optimal control problems with quadratic control costs can be viewed as approximating a target path space measure, e.g. via gradient-based optimization. In practice, however, this optimization is challenging in particular if the target measure differs substantially from the prior. In this work, we therefore approach the problem by iteratively solving constrained problems incorporating trust regions that aim for approaching the target measure gradually in a systematic way. It turns out that this trust region based strategy can be understood as a geometric annealing from the prior to the target measure, where, however, the incorporated trust regions lead to a principled and educated way of choosing the time steps in the annealing path. We demonstrate in multiple optimal control applications that our novel method can improve performance significantly, including tasks in diffusion-based sampling, transition path sampling, and fine-tuning of diffusion models.