 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointMapPolicy: Structured Point Cloud Processing for Multi-Modal Imitation Learning
Oct 23, 2025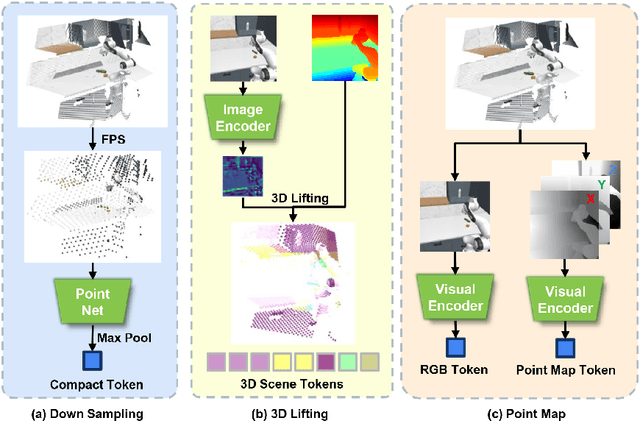
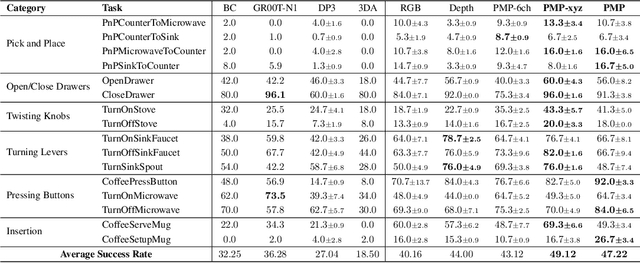
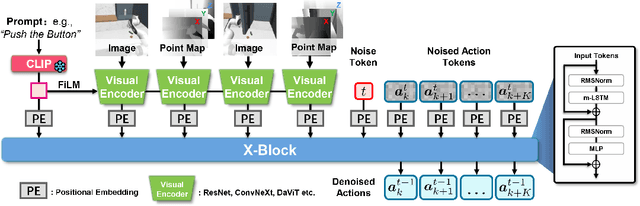
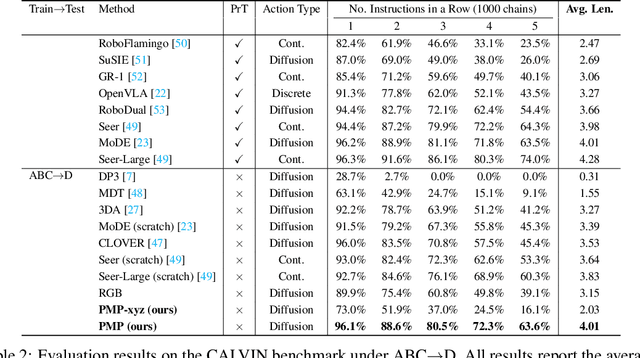
Robotic manipulation systems benefit from complementary sensing modalities, where each provides unique environmental information. Point clouds capture detailed geometric structure, while RGB images provide rich semantic context. Current point cloud methods struggle to capture fine-grained detail, especially for complex tasks, which RGB methods lack geometric awareness, which hinders their precision and generalization. We introduce PointMapPolicy, a novel approach that conditions diffusion policies on structured grids of points without downsampling. The resulting data type makes it easier to extract shape and spatial relationships from observations, and can be transformed between reference frames. Yet due to their structure in a regular grid, we enable the use of established computer vision techniques directly to 3D data. Using xLSTM as a backbone, our model efficiently fuses the point maps with RGB data for enhanced multi-modal perception. Through extensive experiments on the RoboCasa and CALVIN benchmarks and real robot evaluations, we demonstrate that our method achieves state-of-the-art performance across diverse manipulation tasks. The overview and demos are available on our project page: https://point-map.github.io/Point-Map/
BEAST: Efficient Tokenization of B-Splines Encoded Action Sequences for Imitation Learning
Jun 06, 2025We present the B-spline Encoded Action Sequence Tokenizer (BEAST), a novel action tokenizer that encodes action sequences into compact discrete or continuous tokens using B-splines. In contrast to existing action tokenizers based on vector quantization or byte pair encoding, BEAST requires no separate tokenizer training and consistently produces tokens of uniform length, enabling fast action sequence generation via parallel decoding. Leveraging our B-spline formulation, BEAST inherently ensures generating smooth trajectories without discontinuities between adjacent segments. We extensively evaluate BEAST by integrating it with three distinct model architectures: a Variational Autoencoder (VAE) with continuous tokens, a decoder-only Transformer with discrete tokens, and Florence-2, a pretrained Vision-Language Model with an encoder-decoder architecture, demonstrating BEAST's compatibility and scalability with large pretrained models. We evaluate BEAST across three established benchmarks consisting of 166 simulated tasks and on three distinct robot settings with a total of 8 real-world tasks. Experimental results demonstrate that BEAST (i) significantly reduces both training and inference computational costs, and (ii) consistently generates smooth, high-frequency control signals suitable for continuous control tasks while (iii) reliably achieves competitive task success rates compared to state-of-the-art methods.
Beyond Visuals: Investigating Force Feedback in Extended Reality for Robot Data Collection
Mar 26, 2025This work explores how force feedback affects various aspects of robot data collection within the Extended Reality (XR) setting. Force feedback has been proved to enhance the user experience in Extended Reality (XR) by providing contact-rich information. However, its impact on robot data collection has not received much attention in the robotics community. This paper addresses this shortcoming by conducting an extensive user study on the effects of force feedback during data collection in XR. We extended two XR-based robot control interfaces, Kinesthetic Teaching and Motion Controllers, with haptic feedback features. The user study is conducted using manipulation tasks ranging from simple pick-place to complex peg assemble, requiring precise operations. The evaluations show that force feedback enhances task performance and user experience, particularly in tasks requiring high-precision manipulation. These improvements vary depending on the robot control interface and task complexity. This paper provides new insights into how different factors influence the impact of force feedback.
IRIS: An Immersive Robot Interaction System
Feb 05, 2025



This paper introduces IRIS, an immersive Robot Interaction System leveraging Extended Reality (XR), designed for robot data collection and interaction across multiple simulators, benchmarks, and real-world scenarios. While existing XR-based data collection systems provide efficient and intuitive solutions for large-scale data collection, they are often challenging to reproduce and reuse. This limitation arises because current systems are highly tailored to simulator-specific use cases and environments. IRIS is a novel, easily extendable framework that already supports multiple simulators, benchmarks, and even headsets. Furthermore, IRIS is able to include additional information from real-world sensors, such as point clouds captured through depth cameras. A unified scene specification is generated directly from simulators or real-world sensors and transmitted to XR headsets, creating identical scenes in XR. This specification allows IRIS to support any of the objects, assets, and robots provided by the simulators. In addition, IRIS introduces shared spatial anchors and a robust communication protocol that links simulations between multiple XR headsets. This feature enables multiple XR headsets to share a synchronized scene, facilitating collaborative and multi-user data collection. IRIS can be deployed on any device that supports the Unity Framework, encompassing the vast majority of commercially available headsets. In this work, IRIS was deployed and tested on the Meta Quest 3 and the HoloLens 2. IRIS showcased its versatility across a wide range of real-world and simulated scenarios, using current popular robot simulators such as MuJoCo, IsaacSim, CoppeliaSim, and Genesis. In addition, a user study evaluates IRIS on a data collection task for the LIBERO benchmark. The study shows that IRIS significantly outperforms the baseline in both objective and subjective metrics.
TOP-ERL: Transformer-based Off-Policy Episodic Reinforcement Learning
Oct 12, 2024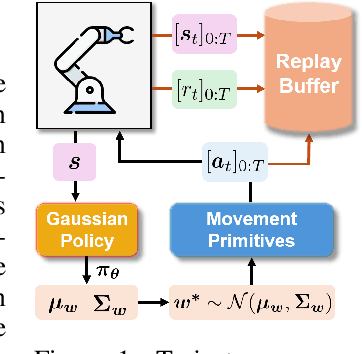
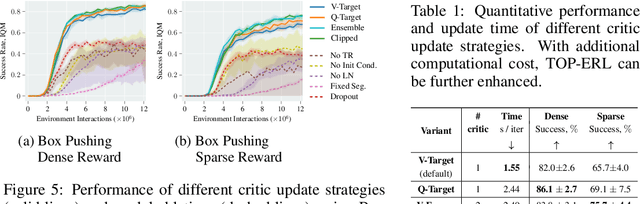
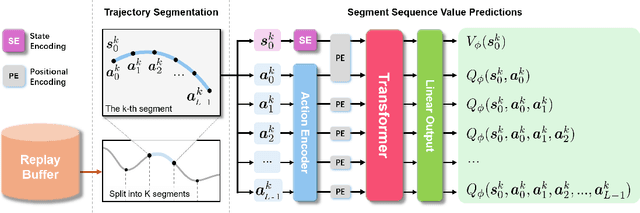

This work introduces Transformer-based Off-Policy Episodic Reinforcement Learning (TOP-ERL), a novel algorithm that enables off-policy updates in the ERL framework. In ERL, policies predict entire action trajectories over multiple time steps instead of single actions at every time step. These trajectories are typically parameterized by trajectory generators such as Movement Primitives (MP), allowing for smooth and efficient exploration over long horizons while capturing high-level temporal correlations. However, ERL methods are often constrained to on-policy frameworks due to the difficulty of evaluating state-action values for entire action sequences, limiting their sample efficiency and preventing the use of more efficient off-policy architectures. TOP-ERL addresses this shortcoming by segmenting long action sequences and estimating the state-action values for each segment using a transformer-based critic architecture alongside an n-step return estimation. These contributions result in efficient and stable training that is reflected in the empirical results conducted on sophisticated robot learning environments. TOP-ERL significantly outperforms state-of-the-art RL methods. Thorough ablation studies additionally show the impact of key design choices on the model performance.
Towards Diverse Behaviors: A Benchmark for Imitation Learning with Human Demonstrations
Feb 22, 2024
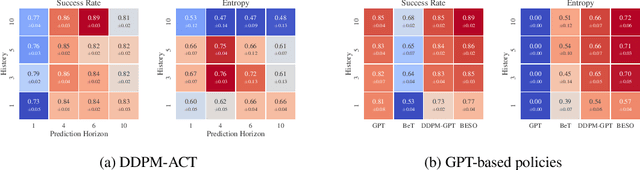

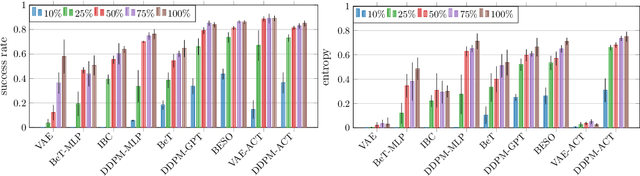
Imitation learning with human data has demonstrated remarkable success in teaching robots in a wide range of skills. However, the inherent diversity in human behavior leads to the emergence of multi-modal data distributions, thereby presenting a formidable challenge for existing imitation learning algorithms. Quantifying a model's capacity to capture and replicate this diversity effectively is still an open problem. In this work, we introduce simulation benchmark environments and the corresponding Datasets with Diverse human Demonstrations for Imitation Learning (D3IL), designed explicitly to evaluate a model's ability to learn multi-modal behavior. Our environments are designed to involve multiple sub-tasks that need to be solved, consider manipulation of multiple objects which increases the diversity of the behavior and can only be solved by policies that rely on closed loop sensory feedback. Other available datasets are missing at least one of these challenging properties. To address the challenge of diversity quantification, we introduce tractable metrics that provide valuable insights into a model's ability to acquire and reproduce diverse behaviors. These metrics offer a practical means to assess the robustness and versatility of imitation learning algorithms. Furthermore, we conduct a thorough evaluation of state-of-the-art methods on the proposed task suite. This evaluation serves as a benchmark for assessing their capability to learn diverse behaviors. Our findings shed light on the effectiveness of these methods in tackling the intricate problem of capturing and generalizing multi-modal human behaviors, offering a valuable reference for the design of future imitation learning algorithms.