 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREASAN: Learning Reactive Safe Navigation for Legged Robots
Dec 10, 2025

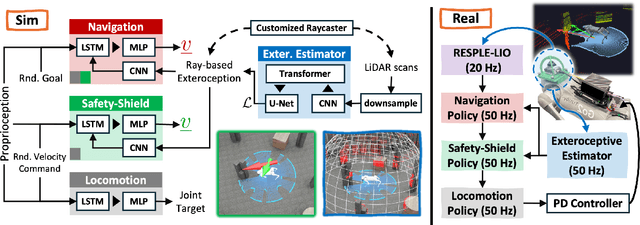
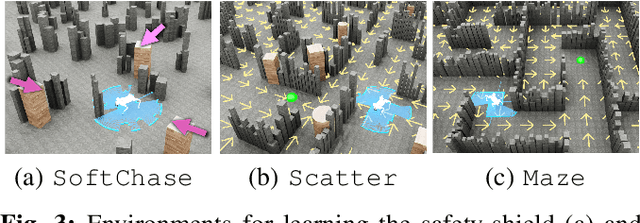
We present a novel modularized end-to-end framework for legged reactive navigation in complex dynamic environments using a single light detection and ranging (LiDAR) sensor. The system comprises four simulation-trained modules: three reinforcement-learning (RL) policies for locomotion, safety shielding, and navigation, and a transformer-based exteroceptive estimator that processes raw point-cloud inputs. This modular decomposition of complex legged motor-control tasks enables lightweight neural networks with simple architectures, trained using standard RL practices with targeted reward shaping and curriculum design, without reliance on heuristics or sophisticated policy-switching mechanisms. We conduct comprehensive ablations to validate our design choices and demonstrate improved robustness compared to existing approaches in challenging navigation tasks. The resulting reactive safe navigation (REASAN) system achieves fully onboard and real-time reactive navigation across both single- and multi-robot settings in complex environments. We release our training and deployment code at https://github.com/ASIG-X/REASAN.
IRIS: An Immersive Robot Interaction System
Feb 05, 2025



This paper introduces IRIS, an immersive Robot Interaction System leveraging Extended Reality (XR), designed for robot data collection and interaction across multiple simulators, benchmarks, and real-world scenarios. While existing XR-based data collection systems provide efficient and intuitive solutions for large-scale data collection, they are often challenging to reproduce and reuse. This limitation arises because current systems are highly tailored to simulator-specific use cases and environments. IRIS is a novel, easily extendable framework that already supports multiple simulators, benchmarks, and even headsets. Furthermore, IRIS is able to include additional information from real-world sensors, such as point clouds captured through depth cameras. A unified scene specification is generated directly from simulators or real-world sensors and transmitted to XR headsets, creating identical scenes in XR. This specification allows IRIS to support any of the objects, assets, and robots provided by the simulators. In addition, IRIS introduces shared spatial anchors and a robust communication protocol that links simulations between multiple XR headsets. This feature enables multiple XR headsets to share a synchronized scene, facilitating collaborative and multi-user data collection. IRIS can be deployed on any device that supports the Unity Framework, encompassing the vast majority of commercially available headsets. In this work, IRIS was deployed and tested on the Meta Quest 3 and the HoloLens 2. IRIS showcased its versatility across a wide range of real-world and simulated scenarios, using current popular robot simulators such as MuJoCo, IsaacSim, CoppeliaSim, and Genesis. In addition, a user study evaluates IRIS on a data collection task for the LIBERO benchmark. The study shows that IRIS significantly outperforms the baseline in both objective and subjective metrics.
Solving Zero-Shot 3D Visual Grounding as Constraint Satisfaction Problems
Nov 21, 20243D visual grounding (3DVG) aims to locate objects in a 3D scene with natural language descriptions. Supervised methods have achieved decent accuracy, but have a closed vocabulary and limited language understanding ability. Zero-shot methods mostly utilize large language models (LLMs) to handle natural language descriptions, yet suffer from slow inference speed. To address these problems, in this work, we propose a zero-shot method that reformulates the 3DVG task as a Constraint Satisfaction Problem (CSP), where the variables and constraints represent objects and their spatial relations, respectively. This allows a global reasoning of all relevant objects, producing grounding results of both the target and anchor objects. Moreover, we demonstrate the flexibility of our framework by handling negation- and counting-based queries with only minor extra coding efforts. Our system, Constraint Satisfaction Visual Grounding (CSVG), has been extensively evaluated on the public datasets ScanRefer and Nr3D datasets using only open-source LLMs. Results show the effectiveness of CSVG and superior grounding accuracy over current state-of-the-art zero-shot 3DVG methods with improvements of $+7.0\%$ (Acc@0.5 score) and $+11.2\%$ on the ScanRefer and Nr3D datasets, respectively. The code of our system is publicly available at https://github.com/sunsleaf/CSVG.