 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Group Relative Policy Optimization: Its Policy Gradient is a U-Statistic
Mar 03, 2026Group relative policy optimization (GRPO), a core methodological component of DeepSeekMath and DeepSeek-R1, has emerged as a cornerstone for scaling reasoning capabilities of large language models. Despite its widespread adoption and the proliferation of follow-up works, the theoretical properties of GRPO remain less studied. This paper provides a unified framework to understand GRPO through the lens of classical U-statistics. We demonstrate that the GRPO policy gradient is inherently a U-statistic, allowing us to characterize its mean squared error (MSE), derive the finite-sample error bound and asymptotic distribution of the suboptimality gap for its learned policy. Our findings reveal that GRPO is asymptotically equivalent to an oracle policy gradient algorithm -- one with access to a value function that quantifies the goodness of its learning policy at each training iteration -- and achieves asymptotically optimal performance within a broad class of policy gradient algorithms. Furthermore, we establish a universal scaling law that offers principled guidance for selecting the optimal group size. Empirical experiments further validate our theoretical findings, demonstrating that the optimal group size is universal, and verify the oracle property of GRPO.
A Difference-in-Difference Approach to Detecting AI-Generated Images
Feb 27, 2026Diffusion models are able to produce AI-generated images that are almost indistinguishable from real ones. This raises concerns about their potential misuse and poses substantial challenges for detecting them. Many existing detectors rely on reconstruction error -- the difference between the input image and its reconstructed version -- as the basis for distinguishing real from fake images. However, these detectors become less effective as modern AI-generated images become increasingly similar to real ones. To address this challenge, we propose a novel difference-in-difference method. Instead of directly using the reconstruction error (a first-order difference), we compute the difference in reconstruction error -- a second-order difference -- for variance reduction and improving detection accuracy. Extensive experiments demonstrate that our method achieves strong generalization performance, enabling reliable detection of AI-generated images in the era of generative AI.
Learn-to-Distance: Distance Learning for Detecting LLM-Generated Text
Jan 29, 2026Modern large language models (LLMs) such as GPT, Claude, and Gemini have transformed the way we learn, work, and communicate. Yet, their ability to produce highly human-like text raises serious concerns about misinformation and academic integrity, making it an urgent need for reliable algorithms to detect LLM-generated content. In this paper, we start by presenting a geometric approach to demystify rewrite-based detection algorithms, revealing their underlying rationale and demonstrating their generalization ability. Building on this insight, we introduce a novel rewrite-based detection algorithm that adaptively learns the distance between the original and rewritten text. Theoretically, we demonstrate that employing an adaptively learned distance function is more effective for detection than using a fixed distance. Empirically, we conduct extensive experiments with over 100 settings, and find that our approach demonstrates superior performance over baseline algorithms in the majority of scenarios. In particular, it achieves relative improvements from 57.8\% to 80.6\% over the strongest baseline across different target LLMs (e.g., GPT, Claude, and Gemini).
AgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
Detecting LLM-Generated Text with Performance Guarantees
Jan 10, 2026Large language models (LLMs) such as GPT, Claude, Gemini, and Grok have been deeply integrated into our daily life. They now support a wide range of tasks -- from dialogue and email drafting to assisting with teaching and coding, serving as search engines, and much more. However, their ability to produce highly human-like text raises serious concerns, including the spread of fake news, the generation of misleading governmental reports, and academic misconduct. To address this practical problem, we train a classifier to determine whether a piece of text is authored by an LLM or a human. Our detector is deployed on an online CPU-based platform https://huggingface.co/spaces/stats-powered-ai/StatDetectLLM, and contains three novelties over existing detectors: (i) it does not rely on auxiliary information, such as watermarks or knowledge of the specific LLM used to generate the text; (ii) it more effectively distinguishes between human- and LLM-authored text; and (iii) it enables statistical inference, which is largely absent in the current literature. Empirically, our classifier achieves higher classification accuracy compared to existing detectors, while maintaining type-I error control, high statistical power, and computational efficiency.
PointMapPolicy: Structured Point Cloud Processing for Multi-Modal Imitation Learning
Oct 23, 2025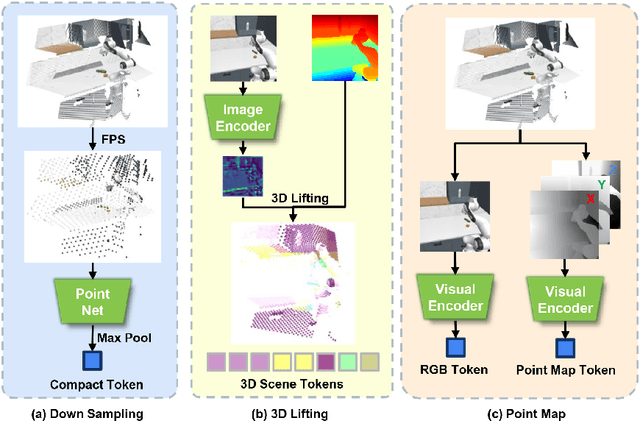
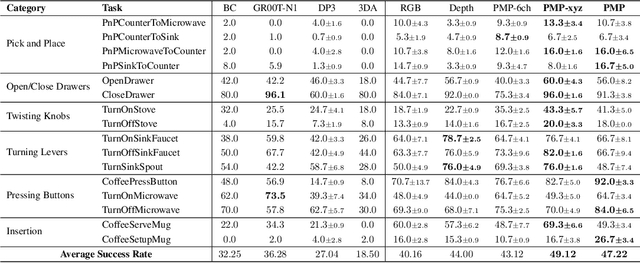
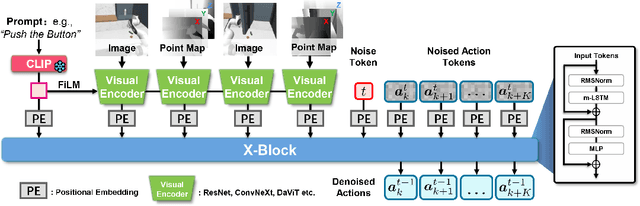
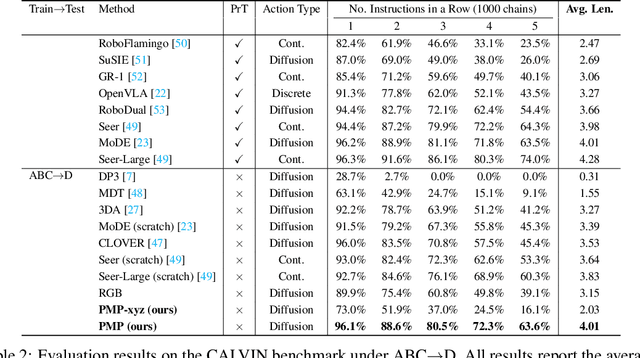
Robotic manipulation systems benefit from complementary sensing modalities, where each provides unique environmental information. Point clouds capture detailed geometric structure, while RGB images provide rich semantic context. Current point cloud methods struggle to capture fine-grained detail, especially for complex tasks, which RGB methods lack geometric awareness, which hinders their precision and generalization. We introduce PointMapPolicy, a novel approach that conditions diffusion policies on structured grids of points without downsampling. The resulting data type makes it easier to extract shape and spatial relationships from observations, and can be transformed between reference frames. Yet due to their structure in a regular grid, we enable the use of established computer vision techniques directly to 3D data. Using xLSTM as a backbone, our model efficiently fuses the point maps with RGB data for enhanced multi-modal perception. Through extensive experiments on the RoboCasa and CALVIN benchmarks and real robot evaluations, we demonstrate that our method achieves state-of-the-art performance across diverse manipulation tasks. The overview and demos are available on our project page: https://point-map.github.io/Point-Map/
FLOWER: Democratizing Generalist Robot Policies with Efficient Vision-Language-Action Flow Policies
Sep 05, 2025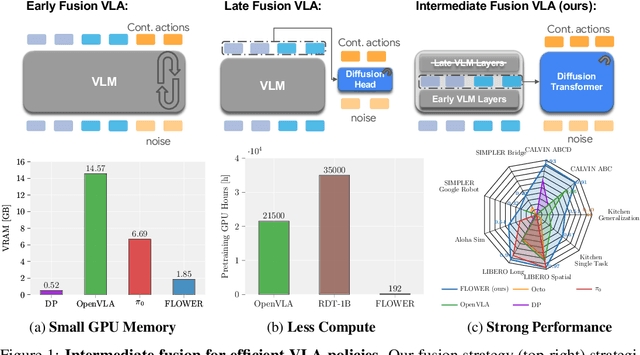

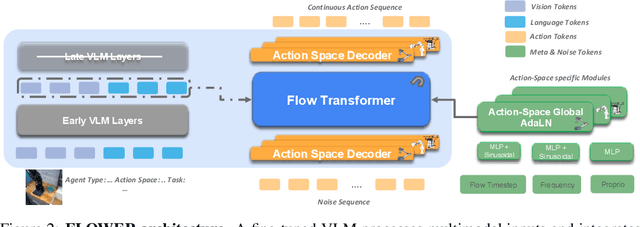
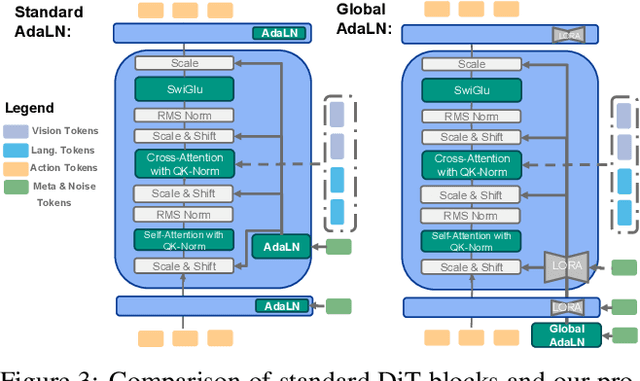
Developing efficient Vision-Language-Action (VLA) policies is crucial for practical robotics deployment, yet current approaches face prohibitive computational costs and resource requirements. Existing diffusion-based VLA policies require multi-billion-parameter models and massive datasets to achieve strong performance. We tackle this efficiency challenge with two contributions: intermediate-modality fusion, which reallocates capacity to the diffusion head by pruning up to $50\%$ of LLM layers, and action-specific Global-AdaLN conditioning, which cuts parameters by $20\%$ through modular adaptation. We integrate these advances into a novel 950 M-parameter VLA called FLOWER. Pretrained in just 200 H100 GPU hours, FLOWER delivers competitive performance with bigger VLAs across $190$ tasks spanning ten simulation and real-world benchmarks and demonstrates robustness across diverse robotic embodiments. In addition, FLOWER achieves a new SoTA of 4.53 on the CALVIN ABC benchmark. Demos, code and pretrained weights are available at https://intuitive-robots.github.io/flower_vla/.
BEAST: Efficient Tokenization of B-Splines Encoded Action Sequences for Imitation Learning
Jun 06, 2025We present the B-spline Encoded Action Sequence Tokenizer (BEAST), a novel action tokenizer that encodes action sequences into compact discrete or continuous tokens using B-splines. In contrast to existing action tokenizers based on vector quantization or byte pair encoding, BEAST requires no separate tokenizer training and consistently produces tokens of uniform length, enabling fast action sequence generation via parallel decoding. Leveraging our B-spline formulation, BEAST inherently ensures generating smooth trajectories without discontinuities between adjacent segments. We extensively evaluate BEAST by integrating it with three distinct model architectures: a Variational Autoencoder (VAE) with continuous tokens, a decoder-only Transformer with discrete tokens, and Florence-2, a pretrained Vision-Language Model with an encoder-decoder architecture, demonstrating BEAST's compatibility and scalability with large pretrained models. We evaluate BEAST across three established benchmarks consisting of 166 simulated tasks and on three distinct robot settings with a total of 8 real-world tasks. Experimental results demonstrate that BEAST (i) significantly reduces both training and inference computational costs, and (ii) consistently generates smooth, high-frequency control signals suitable for continuous control tasks while (iii) reliably achieves competitive task success rates compared to state-of-the-art methods.
Demystifying the Paradox of Importance Sampling with an Estimated History-Dependent Behavior Policy in Off-Policy Evaluation
May 28, 2025This paper studies off-policy evaluation (OPE) in reinforcement learning with a focus on behavior policy estimation for importance sampling. Prior work has shown empirically that estimating a history-dependent behavior policy can lead to lower mean squared error (MSE) even when the true behavior policy is Markovian. However, the question of why the use of history should lower MSE remains open. In this paper, we theoretically demystify this paradox by deriving a bias-variance decomposition of the MSE of ordinary importance sampling (IS) estimators, demonstrating that history-dependent behavior policy estimation decreases their asymptotic variances while increasing their finite-sample biases. Additionally, as the estimated behavior policy conditions on a longer history, we show a consistent decrease in variance. We extend these findings to a range of other OPE estimators, including the sequential IS estimator, the doubly robust estimator and the marginalized IS estimator, with the behavior policy estimated either parametrically or non-parametrically.
MonoMobility: Zero-Shot 3D Mobility Analysis from Monocular Videos
May 17, 2025Accurately analyzing the motion parts and their motion attributes in dynamic environments is crucial for advancing key areas such as embodied intelligence. Addressing the limitations of existing methods that rely on dense multi-view images or detailed part-level annotations, we propose an innovative framework that can analyze 3D mobility from monocular videos in a zero-shot manner. This framework can precisely parse motion parts and motion attributes only using a monocular video, completely eliminating the need for annotated training data. Specifically, our method first constructs the scene geometry and roughly analyzes the motion parts and their initial motion attributes combining depth estimation, optical flow analysis and point cloud registration method, then employs 2D Gaussian splatting for scene representation. Building on this, we introduce an end-to-end dynamic scene optimization algorithm specifically designed for articulated objects, refining the initial analysis results to ensure the system can handle 'rotation', 'translation', and even complex movements ('rotation+translation'), demonstrating high flexibility and versatility. To validate the robustness and wide applicability of our method, we created a comprehensive dataset comprising both simulated and real-world scenarios. Experimental results show that our framework can effectively analyze articulated object motions in an annotation-free manner, showcasing its significant potential in future embodied intelligence applications.