 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with Learned Subgoals Selected by Temporal Information
Oct 26, 2024



Path planning in a changing environment is a challenging task in robotics, as moving objects impose time-dependent constraints. Recent planning methods primarily focus on the spatial aspects, lacking the capability to directly incorporate time constraints. In this paper, we propose a method that leverages a generative model to decompose a complex planning problem into small manageable ones by incrementally generating subgoals given the current planning context. Then, we take into account the temporal information and use learned time estimators based on different statistic distributions to examine and select the generated subgoal candidates. Experiments show that planning from the current robot state to the selected subgoal can satisfy the given time-dependent constraints while being goal-oriented.
HIRO: Heuristics Informed Robot Online Path Planning Using Pre-computed Deterministic Roadmaps
Oct 26, 2024



With the goal of efficiently computing collision-free robot motion trajectories in dynamically changing environments, we present results of a novel method for Heuristics Informed Robot Online Path Planning (HIRO). Dividing robot environments into static and dynamic elements, we use the static part for initializing a deterministic roadmap, which provides a lower bound of the final path cost as informed heuristics for fast path-finding. These heuristics guide a search tree to explore the roadmap during runtime. The search tree examines the edges using a fuzzy collision checking concerning the dynamic environment. Finally, the heuristics tree exploits knowledge fed back from the fuzzy collision checking module and updates the lower bound for the path cost. As we demonstrate in real-world experiments, the closed-loop formed by these three components significantly accelerates the planning procedure. An additional backtracking step ensures the feasibility of the resulting paths. Experiments in simulation and the real world show that HIRO can find collision-free paths considerably faster than baseline methods with and without prior knowledge of the environment.
dGrasp: NeRF-Informed Implicit Grasp Policies with Supervised Optimization Slopes
Jun 14, 2024



We present dGrasp, an implicit grasp policy with an enhanced optimization landscape. This landscape is defined by a NeRF-informed grasp value function. The neural network representing this function is trained on grasp demonstrations. During training, we use an auxiliary loss to guide not only the weight updates of this network but also the update how the slope of the optimization landscape changes. This loss is computed on the demonstrated grasp trajectory and the gradients of the landscape. With second order optimization, we incorporate valuable information from the trajectory as well as facilitate the optimization process of the implicit policy. Experiments demonstrate that employing this auxiliary loss improves policies' performance in simulation as well as their zero-shot transfer to the real-world.
6-DoF Grasp Pose Evaluation and Optimization via Transfer Learning from NeRFs
Jan 15, 2024



We address the problem of robotic grasping of known and unknown objects using implicit behavior cloning. We train a grasp evaluation model from a small number of demonstrations that outputs higher values for grasp candidates that are more likely to succeed in grasping. This evaluation model serves as an objective function, that we maximize to identify successful grasps. Key to our approach is the utilization of learned implicit representations of visual and geometric features derived from a pre-trained NeRF. Though trained exclusively in a simulated environment with simplified objects and 4-DoF top-down grasps, our evaluation model and optimization procedure demonstrate generalization to 6-DoF grasps and novel objects both in simulation and in real-world settings, without the need for additional data. Supplementary material is available at: https://gergely-soti.github.io/grasp
Gradient based Grasp Pose Optimization on a NeRF that Approximates Grasp Success
Sep 14, 2023



Current robotic grasping methods often rely on estimating the pose of the target object, explicitly predicting grasp poses, or implicitly estimating grasp success probabilities. In this work, we propose a novel approach that directly maps gripper poses to their corresponding grasp success values, without considering objectness. Specifically, we leverage a Neural Radiance Field (NeRF) architecture to learn a scene representation and use it to train a grasp success estimator that maps each pose in the robot's task space to a grasp success value. We employ this learned estimator to tune its inputs, i.e., grasp poses, by gradient-based optimization to obtain successful grasp poses. Contrary to other NeRF-based methods which enhance existing grasp pose estimation approaches by relying on NeRF's rendering capabilities or directly estimate grasp poses in a discretized space using NeRF's scene representation capabilities, our approach uniquely sidesteps both the need for rendering and the limitation of discretization. We demonstrate the effectiveness of our approach on four simulated 3DoF (Degree of Freedom) robotic grasping tasks and show that it can generalize to novel objects. Our best model achieves an average translation error of 3mm from valid grasp poses. This work opens the door for future research to apply our approach to higher DoF grasps and real-world scenarios.
Train What You Know -- Precise Pick-and-Place with Transporter Networks
Feb 17, 2023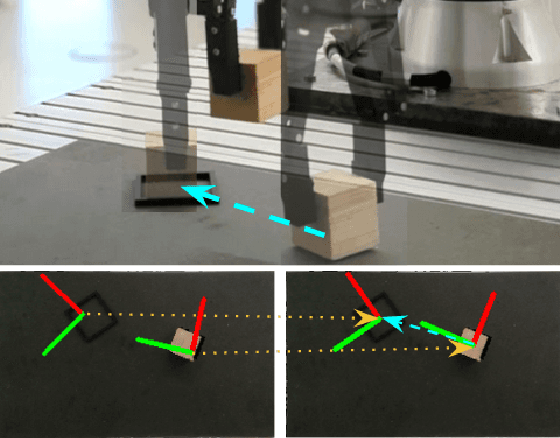
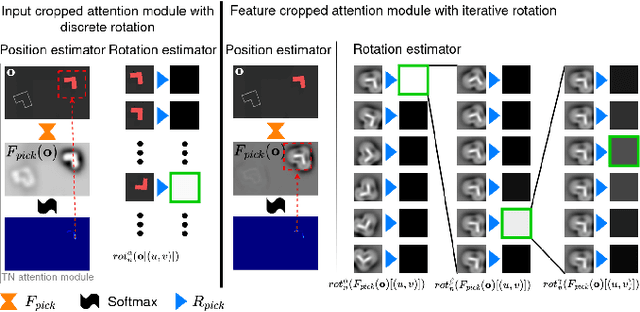
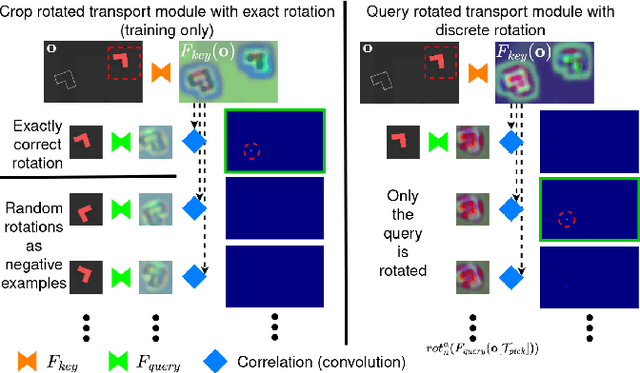
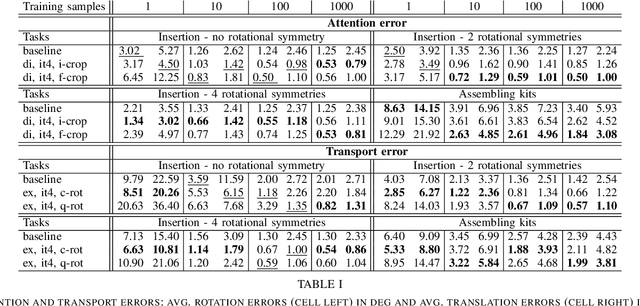
Precise pick-and-place is essential in robotic applications. To this end, we define a novel exact training method and an iterative inference method that improve pick-and-place precision with Transporter Networks. We conduct a large scale experiment on 8 simulated tasks. A systematic analysis shows, that the proposed modifications have a significant positive effect on model performance. Considering picking and placing independently, our methods achieve up to 60% lower rotation and translation errors than baselines. For the whole pick-and-place process we observe 50% lower rotation errors for most tasks with slight improvements in terms of translation errors. Furthermore, we propose architectural changes that retain model performance and reduce computational costs and time. We validate our methods with an interactive teaching procedure on real hardware. Supplementary material will be made available at: https://gergely-soti.github.io/p