 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Reinforcement Learning of Robot Trajectories in the Presence of Moving Obstacles
Nov 08, 2024In this paper, we present an approach for learning collision-free robot trajectories in the presence of moving obstacles. As a first step, we train a backup policy to generate evasive movements from arbitrary initial robot states using model-free reinforcement learning. When learning policies for other tasks, the backup policy can be used to estimate the potential risk of a collision and to offer an alternative action if the estimated risk is considered too high. No matter which action is selected, our action space ensures that the kinematic limits of the robot joints are not violated. We analyze and evaluate two different methods for estimating the risk of a collision. A physics simulation performed in the background is computationally expensive but provides the best results in deterministic environments. If a data-based risk estimator is used instead, the computational effort is significantly reduced, but an additional source of error is introduced. For evaluation, we successfully learn a reaching task and a basketball task while keeping the risk of collisions low. The results demonstrate the effectiveness of our approach for deterministic and stochastic environments, including a human-robot scenario and a ball environment, where no state can be considered permanently safe. By conducting experiments with a real robot, we show that our approach can generate safe trajectories in real time.
HIRO: Heuristics Informed Robot Online Path Planning Using Pre-computed Deterministic Roadmaps
Oct 26, 2024



With the goal of efficiently computing collision-free robot motion trajectories in dynamically changing environments, we present results of a novel method for Heuristics Informed Robot Online Path Planning (HIRO). Dividing robot environments into static and dynamic elements, we use the static part for initializing a deterministic roadmap, which provides a lower bound of the final path cost as informed heuristics for fast path-finding. These heuristics guide a search tree to explore the roadmap during runtime. The search tree examines the edges using a fuzzy collision checking concerning the dynamic environment. Finally, the heuristics tree exploits knowledge fed back from the fuzzy collision checking module and updates the lower bound for the path cost. As we demonstrate in real-world experiments, the closed-loop formed by these three components significantly accelerates the planning procedure. An additional backtracking step ensures the feasibility of the resulting paths. Experiments in simulation and the real world show that HIRO can find collision-free paths considerably faster than baseline methods with and without prior knowledge of the environment.
Planning with Learned Subgoals Selected by Temporal Information
Oct 26, 2024



Path planning in a changing environment is a challenging task in robotics, as moving objects impose time-dependent constraints. Recent planning methods primarily focus on the spatial aspects, lacking the capability to directly incorporate time constraints. In this paper, we propose a method that leverages a generative model to decompose a complex planning problem into small manageable ones by incrementally generating subgoals given the current planning context. Then, we take into account the temporal information and use learned time estimators based on different statistic distributions to examine and select the generated subgoal candidates. Experiments show that planning from the current robot state to the selected subgoal can satisfy the given time-dependent constraints while being goal-oriented.
Jerk-limited Traversal of One-dimensional Paths and its Application to Multi-dimensional Path Tracking
Jul 18, 2024In this paper, we present an iterative method to quickly traverse multi-dimensional paths considering jerk constraints. As a first step, we analyze the traversal of each individual path dimension. We derive a range of feasible target accelerations for each intermediate waypoint of a one-dimensional path using a binary search algorithm. Computing a trajectory from waypoint to waypoint leads to the fastest progress on the path when selecting the highest feasible target acceleration. Similarly, it is possible to calculate a trajectory that leads to minimum progress along the path. This insight allows us to control the traversal of a one-dimensional path in such a way that a reference path length of a multi-dimensional path is approximately tracked over time. In order to improve the tracking accuracy, we propose an iterative scheme to adjust the temporal course of the selected reference path length. More precisely, the temporal region causing the largest position deviation is identified and updated at each iteration. In our evaluation, we thoroughly analyze the performance of our method using seven-dimensional reference paths with different path characteristics. We show that our method manages to quickly traverse the reference paths and compare the required traversing time and the resulting path accuracy with other state-of-the-art approaches.
Reinforcement Learning for Safety Testing: Lessons from A Mobile Robot Case Study
Nov 06, 2023



Safety-critical robot systems need thorough testing to expose design flaws and software bugs which could endanger humans. Testing in simulation is becoming increasingly popular, as it can be applied early in the development process and does not endanger any real-world operators. However, not all safety-critical flaws become immediately observable in simulation. Some may only become observable under certain critical conditions. If these conditions are not covered, safety flaws may remain undetected. Creating critical tests is therefore crucial. In recent years, there has been a trend towards using Reinforcement Learning (RL) for this purpose. Guided by domain-specific reward functions, RL algorithms are used to learn critical test strategies. This paper presents a case study in which the collision avoidance behavior of a mobile robot is subjected to RL-based testing. The study confirms prior research which shows that RL can be an effective testing tool. However, the study also highlights certain challenges associated with RL-based testing, namely (i) a possible lack of diversity in test conditions and (ii) the phenomenon of reward hacking where the RL agent behaves in undesired ways due to a misalignment of reward and test specification. The challenges are illustrated with data and examples from the experiments, and possible mitigation strategies are discussed.
Uncertainty-aware Risk Assessment of Robotic Systems via Importance Sampling
Aug 27, 2023



In this paper, we introduce a probabilistic approach to risk assessment of robot systems by focusing on the impact of uncertainties. While various approaches to identifying systematic hazards (e.g., bugs, design flaws, etc.) can be found in current literature, little attention has been devoted to evaluating risks in robot systems in a probabilistic manner. Existing methods rely on discrete notions for dangerous events and assume that the consequences of these can be described by simple logical operations. In this work, we consider measurement uncertainties as one main contributor to the evolvement of risks. Specifically, we study the impact of temporal and spatial uncertainties on the occurrence probability of dangerous failures, thereby deriving an approach for an uncertainty-aware risk assessment. Secondly, we introduce a method to improve the statistical significance of our results: While the rare occurrence of hazardous events makes it challenging to draw conclusions with reliable accuracy, we show that importance sampling -- a technique that successively generates samples in regions with sparse probability densities -- allows for overcoming this issue. We demonstrate the validity of our novel uncertainty-aware risk assessment method in three simulation scenarios from the domain of human-robot collaboration. Finally, we show how the results can be used to evaluate arbitrary safety limits of robot systems.
Safety Evaluation of Robot Systems via Uncertainty Quantification
Feb 21, 2023

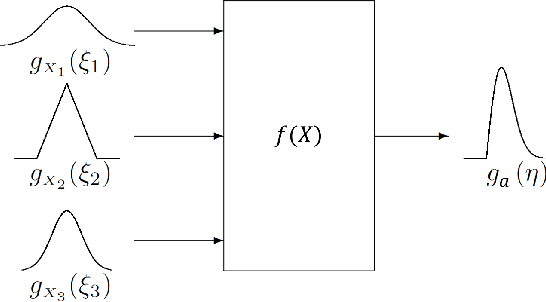

In this paper, we present an approach for quantifying the propagated uncertainty of robot systems in an online and data-driven manner. Especially in Human-Robot Collaboration, keeping track of the safety compliance during run time is essential: Misclassifying dangerous situations as safe might result in severe accidents. According to official regulations (eg, ISO standards), safety in industrial robot applications depends on critical parameters, such as the distance and relative velocity between humans and robots. However, safety can only be assured given a measure for the reliability of these parameters. While different risk detection and mitigation approaches exist in literature, a measure that can be used to evaluate safety limits online, and succinctly implies whether a situation is safe or dangerous, is missing to date. Motivated by this, we introduce a generalizable method for calculating the propagated measurement uncertainty of arbitrary parameters, that captures the accumulated uncertainty originating from sensory devices and environmental disturbances of the system. To show that our approach delivers correct results, we perform validation experiments in simulation. In addition, we employ our method in two real-world settings and demonstrate how quantifying the propagated uncertainty of critical parameters facilitates assessing safety online in Human-Robot Collaboration.
Hazard Analysis of Collaborative Automation Systems: A Two-layer Approach based on Supervisory Control and Simulation
Sep 26, 2022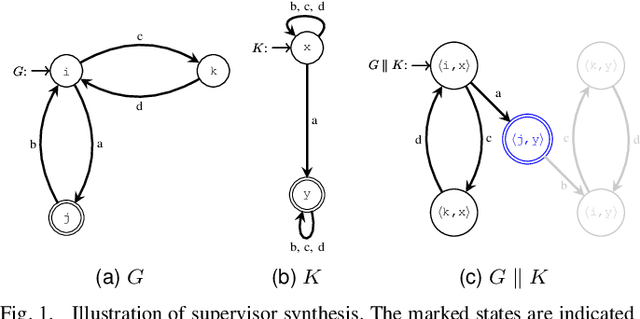
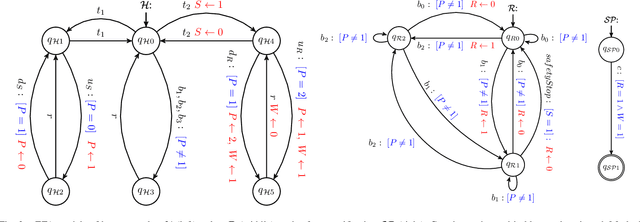
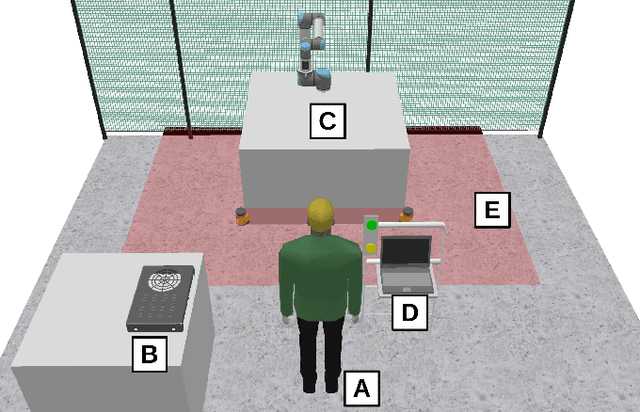
Safety critical systems are typically subjected to hazard analysis before commissioning to identify and analyse potentially hazardous system states that may arise during operation. Currently, hazard analysis is mainly based on human reasoning, past experiences, and simple tools such as checklists and spreadsheets. Increasing system complexity makes such approaches decreasingly suitable. Furthermore, testing-based hazard analysis is often not suitable due to high costs or dangers of physical faults. A remedy for this are model-based hazard analysis methods, which either rely on formal models or on simulation models, each with their own benefits and drawbacks. This paper proposes a two-layer approach that combines the benefits of exhaustive analysis using formal methods with detailed analysis using simulation. Unsafe behaviours that lead to unsafe states are first synthesised from a formal model of the system using Supervisory Control Theory. The result is then input to the simulation where detailed analyses using domain-specific risk metrics are performed. Though the presented approach is generally applicable, this paper demonstrates the benefits of the approach on an industrial human-robot collaboration system.
SpeedFolding: Learning Efficient Bimanual Folding of Garments
Aug 22, 2022

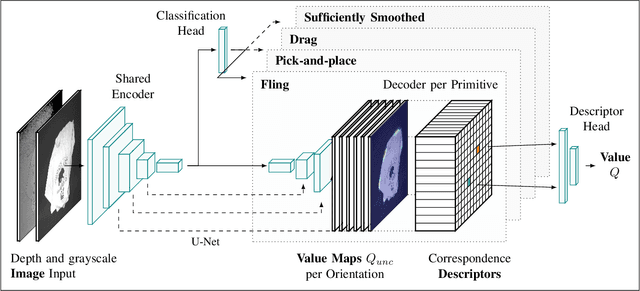
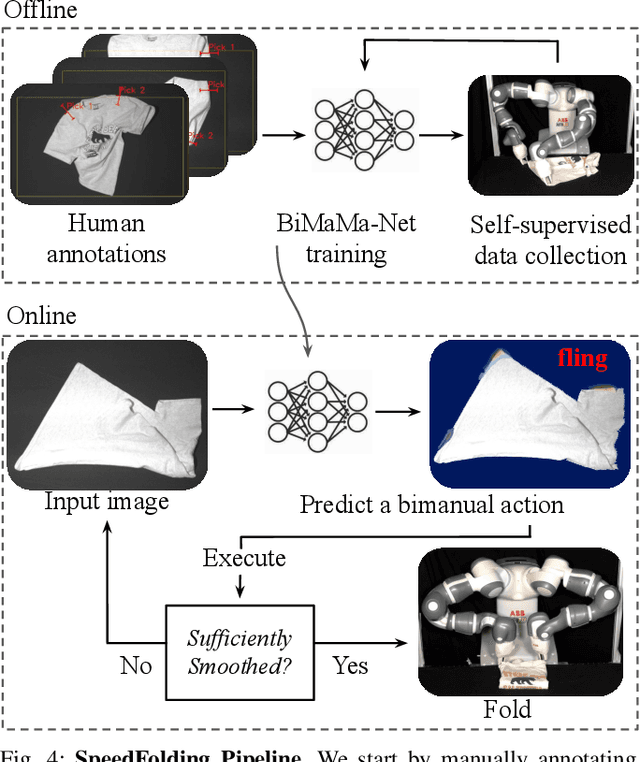
Folding garments reliably and efficiently is a long standing challenge in robotic manipulation due to the complex dynamics and high dimensional configuration space of garments. An intuitive approach is to initially manipulate the garment to a canonical smooth configuration before folding. In this work, we develop SpeedFolding, a reliable and efficient bimanual system, which given user-defined instructions as folding lines, manipulates an initially crumpled garment to (1) a smoothed and (2) a folded configuration. Our primary contribution is a novel neural network architecture that is able to predict pairs of gripper poses to parameterize a diverse set of bimanual action primitives. After learning from 4300 human-annotated and self-supervised actions, the robot is able to fold garments from a random initial configuration in under 120s on average with a success rate of 93%. Real-world experiments show that the system is able to generalize to unseen garments of different color, shape, and stiffness. While prior work achieved 3-6 Folds Per Hour (FPH), SpeedFolding achieves 30-40 FPH.
Learning Time-optimized Path Tracking with or without Sensory Feedback
Mar 03, 2022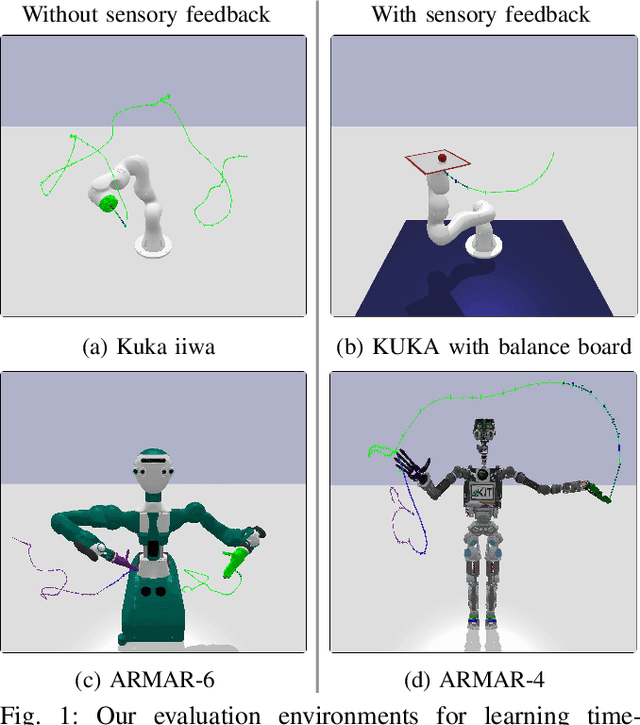

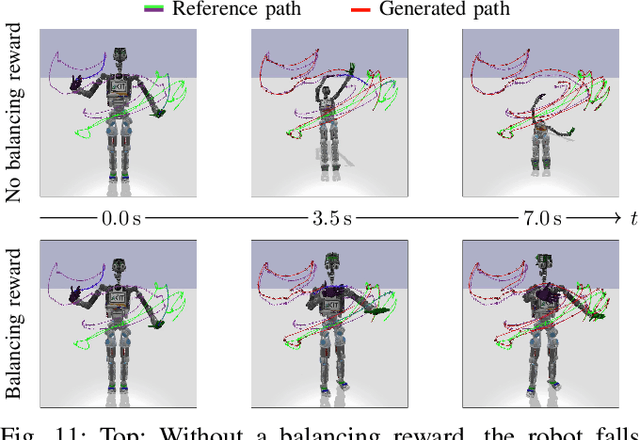
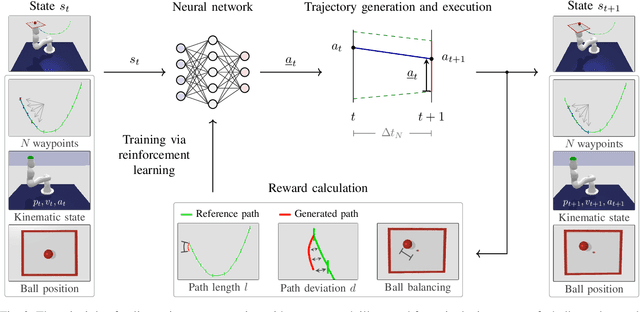
In this paper, we present a learning-based approach that allows a robot to quickly follow a reference path defined in joint space without exceeding limits on the position, velocity, acceleration and jerk of each robot joint. Contrary to offline methods for time-optimal path parameterization, the reference path can be changed during motion execution. In addition, our approach can utilize sensory feedback, for instance, to follow a reference path with a bipedal robot without losing balance. With our method, the robot is controlled by a neural network that is trained via reinforcement learning using data generated by a physics simulator. From a mathematical perspective, the problem of tracking a reference path in a time-optimized manner is formalized as a Markov decision process. Each state includes a fixed number of waypoints specifying the next part of the reference path. The action space is designed in such a way that all resulting motions comply with the specified kinematic joint limits. The reward function finally reflects the trade-off between the execution time, the deviation from the desired reference path and optional additional objectives like balancing. We evaluate our approach with and without additional objectives and show that time-optimized path tracking can be successfully learned for both industrial and humanoid robots. In addition, we demonstrate that networks trained in simulation can be successfully transferred to a real Kuka robot.