 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOMP: Bin-Optimized Motion Planning
Oct 31, 2024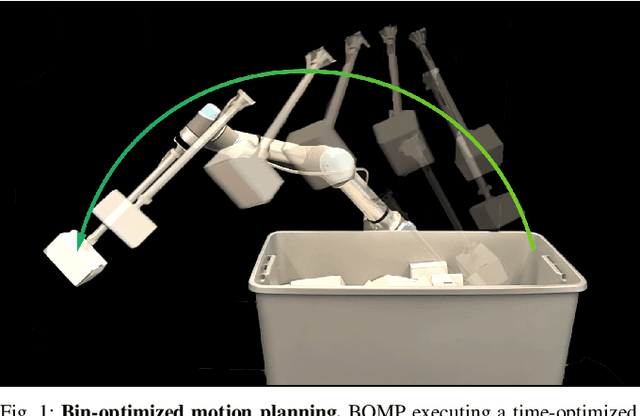
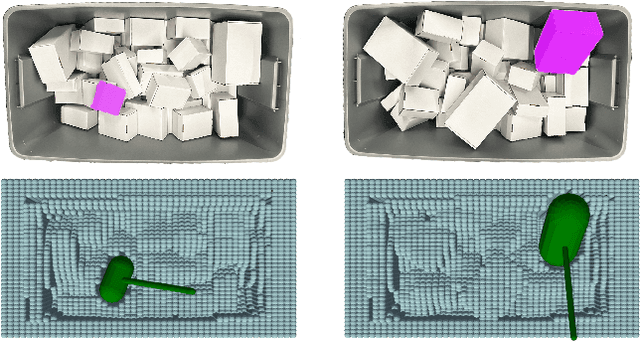
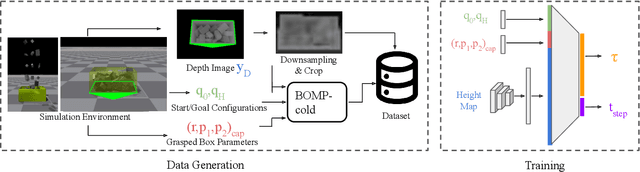
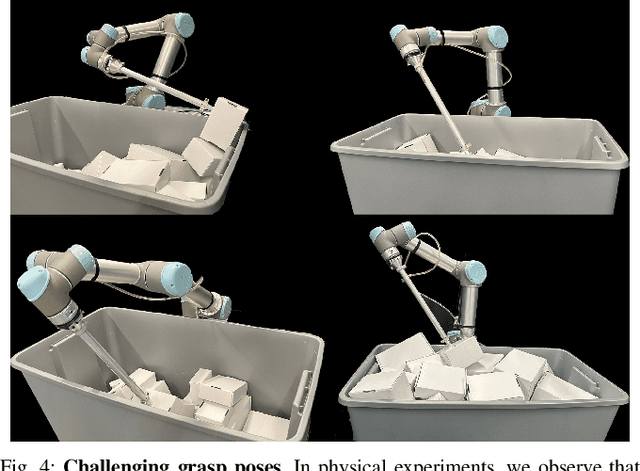
In logistics, the ability to quickly compute and execute pick-and-place motions from bins is critical to increasing productivity. We present Bin-Optimized Motion Planning (BOMP), a motion planning framework that plans arm motions for a six-axis industrial robot with a long-nosed suction tool to remove boxes from deep bins. BOMP considers robot arm kinematics, actuation limits, the dimensions of a grasped box, and a varying height map of a bin environment to rapidly generate time-optimized, jerk-limited, and collision-free trajectories. The optimization is warm-started using a deep neural network trained offline in simulation with 25,000 scenes and corresponding trajectories. Experiments with 96 simulated and 15 physical environments suggest that BOMP generates collision-free trajectories that are up to 58 % faster than baseline sampling-based planners and up to 36 % faster than an industry-standard Up-Over-Down algorithm, which has an extremely low 15 % success rate in this context. BOMP also generates jerk-limited trajectories while baselines do not. Website: https://sites.google.com/berkeley.edu/bomp.
Self-Supervised Learning for Interactive Perception of Surgical Thread for Autonomous Suture Tail-Shortening
Jul 13, 2023



Accurate 3D sensing of suturing thread is a challenging problem in automated surgical suturing because of the high state-space complexity, thinness and deformability of the thread, and possibility of occlusion by the grippers and tissue. In this work we present a method for tracking surgical thread in 3D which is robust to occlusions and complex thread configurations, and apply it to autonomously perform the surgical suture "tail-shortening" task: pulling thread through tissue until a desired "tail" length remains exposed. The method utilizes a learned 2D surgical thread detection network to segment suturing thread in RGB images. It then identifies the thread path in 2D and reconstructs the thread in 3D as a NURBS spline by triangulating the detections from two stereo cameras. Once a 3D thread model is initialized, the method tracks the thread across subsequent frames. Experiments suggest the method achieves a 1.33 pixel average reprojection error on challenging single-frame 3D thread reconstructions, and an 0.84 pixel average reprojection error on two tracking sequences. On the tail-shortening task, it accomplishes a 90% success rate across 20 trials. Supplemental materials are available at https://sites.google.com/berkeley.edu/autolab-surgical-thread/ .
Automating Vascular Shunt Insertion with the dVRK Surgical Robot
Nov 04, 2022Vascular shunt insertion is a fundamental surgical procedure used to temporarily restore blood flow to tissues. It is often performed in the field after major trauma. We formulate a problem of automated vascular shunt insertion and propose a pipeline to perform Automated Vascular Shunt Insertion (AVSI) using a da Vinci Research Kit. The pipeline uses a learned visual model to estimate the locus of the vessel rim, plans a grasp on the rim, and moves to grasp at that point. The first robot gripper then pulls the rim to stretch open the vessel with a dilation motion. The second robot gripper then proceeds to insert a shunt into the vessel phantom (a model of the blood vessel) with a chamfer tilt followed by a screw motion. Results suggest that AVSI achieves a high success rate even with tight tolerances and varying vessel orientations up to 30{\deg}. Supplementary material, dataset, videos, and visualizations can be found at https://sites.google.com/berkeley.edu/autolab-avsi.
SGTM 2.0: Autonomously Untangling Long Cables using Interactive Perception
Sep 27, 2022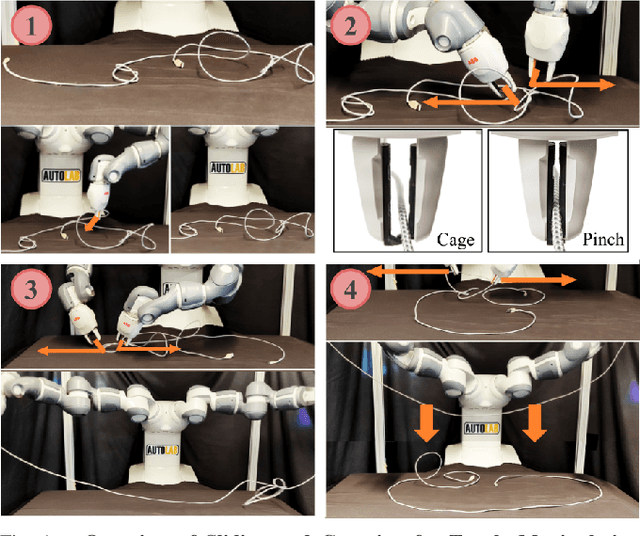

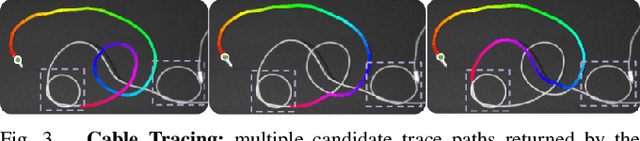
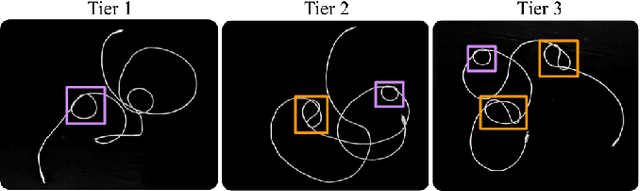
Cables are commonplace in homes, hospitals, and industrial warehouses and are prone to tangling. This paper extends prior work on autonomously untangling long cables by introducing novel uncertainty quantification metrics and actions that interact with the cable to reduce perception uncertainty. We present Sliding and Grasping for Tangle Manipulation 2.0 (SGTM 2.0), a system that autonomously untangles cables approximately 3 meters in length with a bilateral robot using estimates of uncertainty at each step to inform actions. By interactively reducing uncertainty, Sliding and Grasping for Tangle Manipulation 2.0 (SGTM 2.0) reduces the number of state-resetting moves it must take, significantly speeding up run-time. Experiments suggest that SGTM 2.0 can achieve 83% untangling success on cables with 1 or 2 overhand and figure-8 knots, and 70% termination detection success across these configurations, outperforming SGTM 1.0 by 43% in untangling accuracy and 200% in full rollout speed. Supplementary material, visualizations, and videos can be found at sites.google.com/view/sgtm2.
SpeedFolding: Learning Efficient Bimanual Folding of Garments
Aug 22, 2022

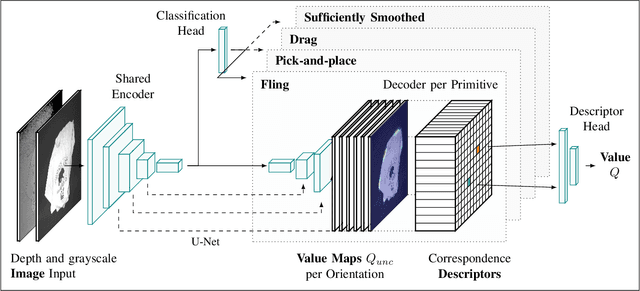
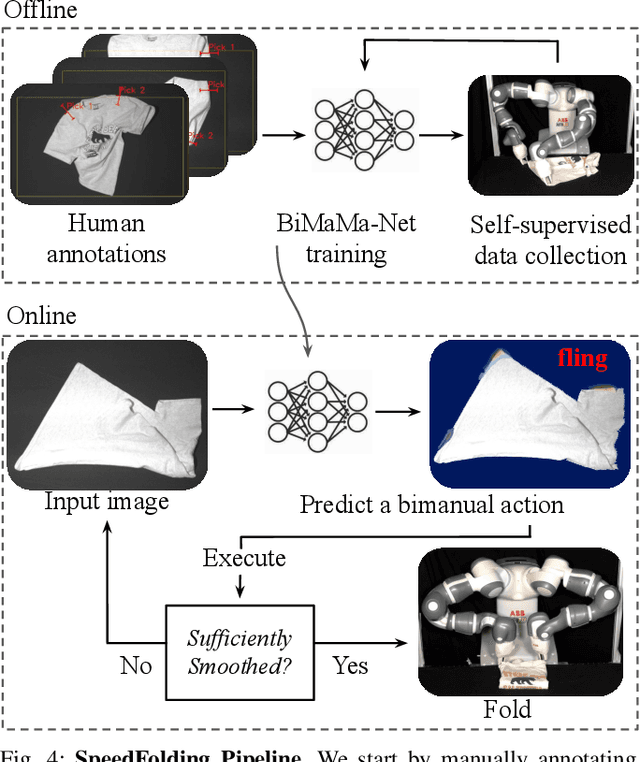
Folding garments reliably and efficiently is a long standing challenge in robotic manipulation due to the complex dynamics and high dimensional configuration space of garments. An intuitive approach is to initially manipulate the garment to a canonical smooth configuration before folding. In this work, we develop SpeedFolding, a reliable and efficient bimanual system, which given user-defined instructions as folding lines, manipulates an initially crumpled garment to (1) a smoothed and (2) a folded configuration. Our primary contribution is a novel neural network architecture that is able to predict pairs of gripper poses to parameterize a diverse set of bimanual action primitives. After learning from 4300 human-annotated and self-supervised actions, the robot is able to fold garments from a random initial configuration in under 120s on average with a success rate of 93%. Real-world experiments show that the system is able to generalize to unseen garments of different color, shape, and stiffness. While prior work achieved 3-6 Folds Per Hour (FPH), SpeedFolding achieves 30-40 FPH.
GOMP-ST: Grasp Optimized Motion Planning for Suction Transport
Mar 16, 2022
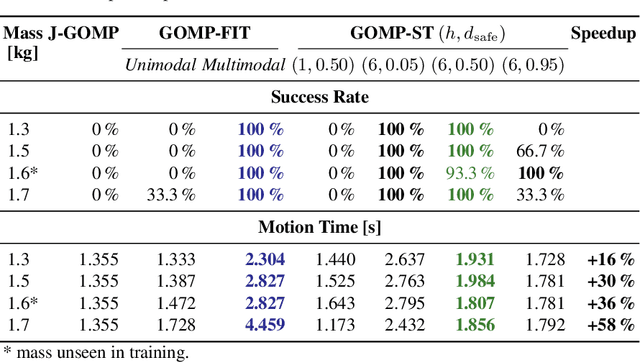
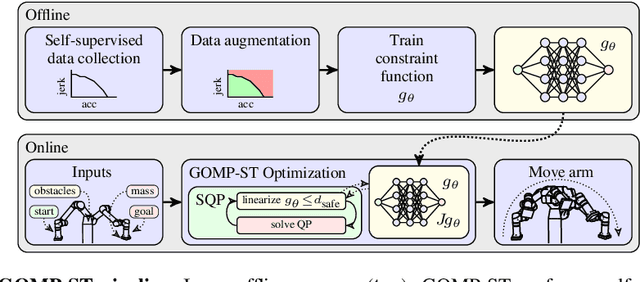

Suction cup grasping is very common in industry, but moving too quickly can cause suction cups to detach, causing drops or damage. Maintaining a suction grasp throughout a high-speed motion requires balancing suction forces against inertial forces while the suction cups deform under strain. In this paper, we consider Grasp Optimized Motion Planning for Suction Transport (GOMP-ST), an algorithm that combines deep learning with optimization to decrease transport time while avoiding suction cup failure. GOMP-ST first repeatedly moves a physical robot, vacuum gripper, and a sample object, while measuring pressure with a solid-state sensor to learn critical failure conditions. Then, these are integrated as constraints on the accelerations at the end-effector into a time-optimizing motion planner. The resulting plans incorporate real-world effects such as suction cup deformation that are difficult to model analytically. In GOMP-ST, the learned constraint, modeled with a neural network, is linearized using Autograd and integrated into a sequential quadratic program optimization. In 420 experiments with a physical UR5 transporting objects ranging from 1.3 to 1.7 kg, we compare GOMP-ST to baseline optimizing motion planners. Results suggest that GOMP-ST can avoid suction cup failure while decreasing transport times from 16% to 58%. For code, video, and datasets, see https://sites.google.com/view/gomp-st.
AlphaGarden: Learning to Autonomously Tend a Polyculture Garden
Nov 11, 2021
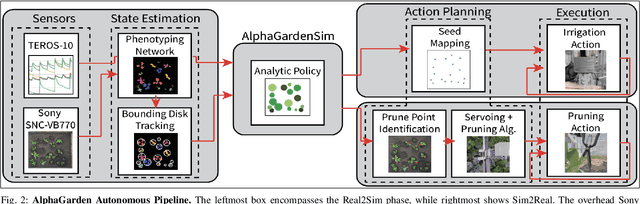

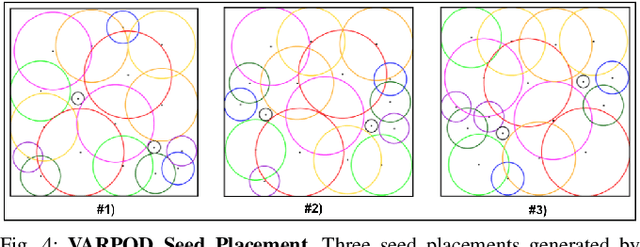
This paper presents AlphaGarden: an autonomous polyculture garden that prunes and irrigates living plants in a 1.5m x 3.0m physical testbed. AlphaGarden uses an overhead camera and sensors to track the plant distribution and soil moisture. We model individual plant growth and interplant dynamics to train a policy that chooses actions to maximize leaf coverage and diversity. For autonomous pruning, AlphaGarden uses two custom-designed pruning tools and a trained neural network to detect prune points. We present results for four 60-day garden cycles. Results suggest AlphaGarden can autonomously achieve 0.96 normalized diversity with pruning shears while maintaining an average canopy coverage of 0.86 during the peak of the cycle. Code, datasets, and supplemental material can be found at https://github.com/BerkeleyAutomation/AlphaGarden.
GOMP-FIT: Grasp-Optimized Motion Planning for Fast Inertial Transport
Oct 28, 2021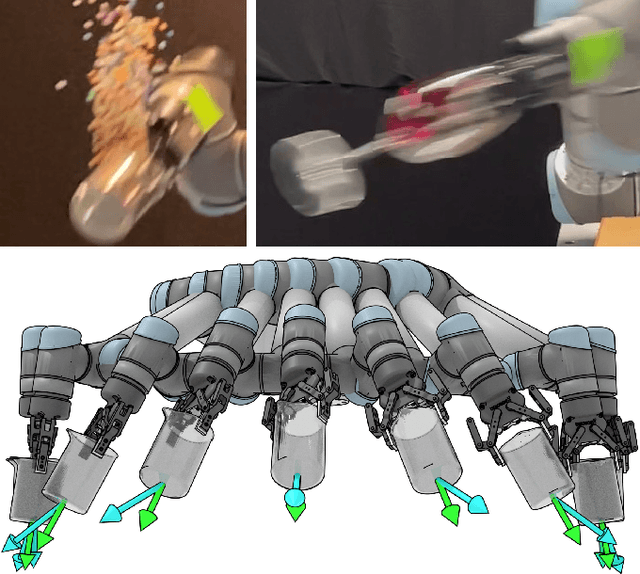


High-speed motions in pick-and-place operations are critical to making robots cost-effective in many automation scenarios, from warehouses and manufacturing to hospitals and homes. However, motions can be too fast -- such as when the object being transported has an open-top, is fragile, or both. One way to avoid spills or damage, is to move the arm slowly. We propose Grasp-Optimized Motion Planning for Fast Inertial Transport (GOMP-FIT), a time-optimizing motion planner based on our prior work, that includes constraints based on accelerations at the robot end-effector. With GOMP-FIT, a robot can perform high-speed motions that avoid obstacles and use inertial forces to its advantage. In experiments transporting open-top containers with varying tilt tolerances, whereas GOMP computes sub-second motions that spill up to 90% of the contents during transport, GOMP-FIT generates motions that spill 0% of contents while being slowed by as little as 0% when there are few obstacles, 30% when there are high obstacles and 45-degree tolerances, and 50% when there 15-degree tolerances and few obstacles.
Dex-NeRF: Using a Neural Radiance Field to Grasp Transparent Objects
Oct 27, 2021



The ability to grasp and manipulate transparent objects is a major challenge for robots. Existing depth cameras have difficulty detecting, localizing, and inferring the geometry of such objects. We propose using neural radiance fields (NeRF) to detect, localize, and infer the geometry of transparent objects with sufficient accuracy to find and grasp them securely. We leverage NeRF's view-independent learned density, place lights to increase specular reflections, and perform a transparency-aware depth-rendering that we feed into the Dex-Net grasp planner. We show how additional lights create specular reflections that improve the quality of the depth map, and test a setup for a robot workcell equipped with an array of cameras to perform transparent object manipulation. We also create synthetic and real datasets of transparent objects in real-world settings, including singulated objects, cluttered tables, and the top rack of a dishwasher. In each setting we show that NeRF and Dex-Net are able to reliably compute robust grasps on transparent objects, achieving 90% and 100% grasp success rates in physical experiments on an ABB YuMi, on objects where baseline methods fail.
6-DoF Grasp Planning using Fast 3D Reconstruction and Grasp Quality CNN
Sep 18, 2020
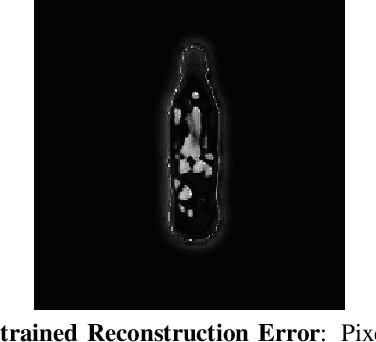
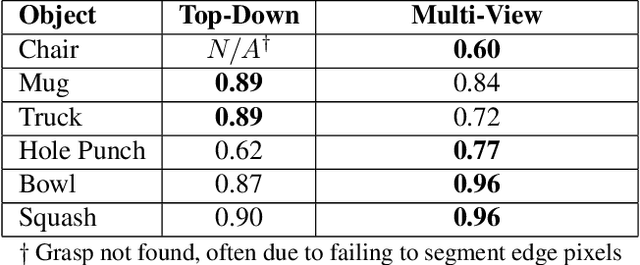
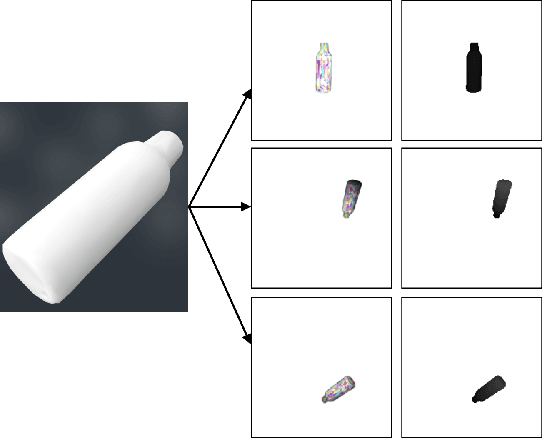
Recent consumer demand for home robots has accelerated performance of robotic grasping. However, a key component of the perception pipeline, the depth camera, is still expensive and inaccessible to most consumers. In addition, grasp planning has significantly improved recently, by leveraging large datasets and cloud robotics, and by limiting the state and action space to top-down grasps with 4 degrees of freedom (DoF). By leveraging multi-view geometry of the object using inexpensive equipment such as off-the-shelf RGB cameras and state-of-the-art algorithms such as Learn Stereo Machine (LSM\cite{kar2017learning}), the robot is able to generate more robust grasps from different angles with 6-DoF. In this paper, we present a modification of LSM to graspable objects, evaluate the grasps, and develop a 6-DoF grasp planner based on Grasp-Quality CNN (GQ-CNN\cite{mahler2017dex}) that exploits multiple camera views to plan a robust grasp, even in the absence of a possible top-down grasp.