 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Forget -- Hierarchical Episodic Memory for Lifelong Robot Deployment
Apr 13, 2026Robots must verbalize their past experiences when users ask "Where did you put my keys?" or "Why did the task fail?" Yet maintaining life-long episodic memory (EM) from continuous multimodal perception quickly exceeds storage limits and makes real-time query impractical, calling for selective forgetting that adapts to users' notions of relevance. We present H$^2$-EMV, a framework enabling humanoids to learn what to remember through user interaction. Our approach incrementally constructs hierarchical EM, selectively forgets using language-model-based relevance estimation conditioned on learned natural-language rules, and updates these rules given user feedback about forgotten details. Evaluations on simulated household tasks and 20.5-hour-long real-world recordings from ARMAR-7 demonstrate that H$^2$-EMV maintains question-answering accuracy while reducing memory size by 45% and query-time compute by 35%. Critically, performance improves over time - accuracy increases 70% in second-round queries by adapting to user-specific priorities - demonstrating that learned forgetting enables scalable, personalized EM for long-term human-robot collaboration.
ManipulationNet: An Infrastructure for Benchmarking Real-World Robot Manipulation with Physical Skill Challenges and Embodied Multimodal Reasoning
Mar 04, 2026Dexterous manipulation enables robots to purposefully alter the physical world, transforming them from passive observers into active agents in unstructured environments. This capability is the cornerstone of physical artificial intelligence. Despite decades of advances in hardware, perception, control, and learning, progress toward general manipulation systems remains fragmented due to the absence of widely adopted standard benchmarks. The central challenge lies in reconciling the variability of the real world with the reproducibility and authenticity required for rigorous scientific evaluation. To address this, we introduce ManipulationNet, a global infrastructure that hosts real-world benchmark tasks for robotic manipulation. ManipulationNet delivers reproducible task setups through standardized hardware kits, and enables distributed performance evaluation via a unified software client that delivers real-time task instructions and collects benchmarking results. As a persistent and scalable infrastructure, ManipulationNet organizes benchmark tasks into two complementary tracks: 1) the Physical Skills Track, which evaluates low-level physical interaction skills, and 2) the Embodied Reasoning Track, which tests high-level reasoning and multimodal grounding abilities. This design fosters the systematic growth of an interconnected network of real-world abilities and skills, paving the path toward general robotic manipulation. By enabling comparable manipulation research in the real world at scale, this infrastructure establishes a sustainable foundation for measuring long-term scientific progress and identifying capabilities ready for real-world deployment.
Intuitive Programming, Adaptive Task Planning, and Dynamic Role Allocation in Human-Robot Collaboration
Nov 11, 2025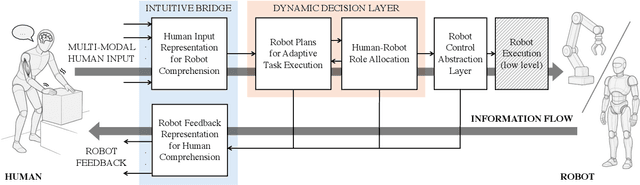
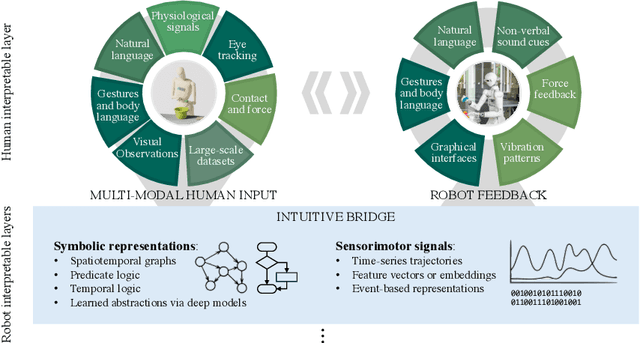
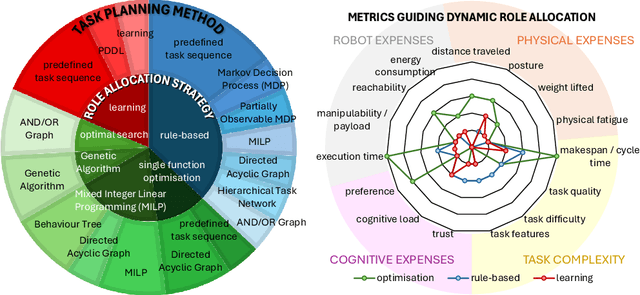
Remarkable capabilities have been achieved by robotics and AI, mastering complex tasks and environments. Yet, humans often remain passive observers, fascinated but uncertain how to engage. Robots, in turn, cannot reach their full potential in human-populated environments without effectively modeling human states and intentions and adapting their behavior. To achieve a synergistic human-robot collaboration (HRC), a continuous information flow should be established: humans must intuitively communicate instructions, share expertise, and express needs. In parallel, robots must clearly convey their internal state and forthcoming actions to keep users informed, comfortable, and in control. This review identifies and connects key components enabling intuitive information exchange and skill transfer between humans and robots. We examine the full interaction pipeline: from the human-to-robot communication bridge translating multimodal inputs into robot-understandable representations, through adaptive planning and role allocation, to the control layer and feedback mechanisms to close the loop. Finally, we highlight trends and promising directions toward more adaptive, accessible HRC.
* Published in the Annual Review of Control, Robotics, and Autonomous Systems, Volume 9; copyright 2026 the author(s), CC BY 4.0, https://www.annualreviews.org
Contact Wasserstein Geodesics for Non-Conservative Schrödinger Bridges
Nov 11, 2025The Schrödinger Bridge provides a principled framework for modeling stochastic processes between distributions; however, existing methods are limited by energy-conservation assumptions, which constrains the bridge's shape preventing it from model varying-energy phenomena. To overcome this, we introduce the non-conservative generalized Schrödinger bridge (NCGSB), a novel, energy-varying reformulation based on contact Hamiltonian mechanics. By allowing energy to change over time, the NCGSB provides a broader class of real-world stochastic processes, capturing richer and more faithful intermediate dynamics. By parameterizing the Wasserstein manifold, we lift the bridge problem to a tractable geodesic computation in a finite-dimensional space. Unlike computationally expensive iterative solutions, our contact Wasserstein geodesic (CWG) is naturally implemented via a ResNet architecture and relies on a non-iterative solver with near-linear complexity. Furthermore, CWG supports guided generation by modulating a task-specific distance metric. We validate our framework on tasks including manifold navigation, molecular dynamics predictions, and image generation, demonstrating its practical benefits and versatility.
Adaptive Domain Modeling with Language Models: A Multi-Agent Approach to Task Planning
Jun 24, 2025We introduce TAPAS (Task-based Adaptation and Planning using AgentS), a multi-agent framework that integrates Large Language Models (LLMs) with symbolic planning to solve complex tasks without the need for manually defined environment models. TAPAS employs specialized LLM-based agents that collaboratively generate and adapt domain models, initial states, and goal specifications as needed using structured tool-calling mechanisms. Through this tool-based interaction, downstream agents can request modifications from upstream agents, enabling adaptation to novel attributes and constraints without manual domain redefinition. A ReAct (Reason+Act)-style execution agent, coupled with natural language plan translation, bridges the gap between dynamically generated plans and real-world robot capabilities. TAPAS demonstrates strong performance in benchmark planning domains and in the VirtualHome simulated real-world environment.
Safe Reinforcement Learning of Robot Trajectories in the Presence of Moving Obstacles
Nov 08, 2024In this paper, we present an approach for learning collision-free robot trajectories in the presence of moving obstacles. As a first step, we train a backup policy to generate evasive movements from arbitrary initial robot states using model-free reinforcement learning. When learning policies for other tasks, the backup policy can be used to estimate the potential risk of a collision and to offer an alternative action if the estimated risk is considered too high. No matter which action is selected, our action space ensures that the kinematic limits of the robot joints are not violated. We analyze and evaluate two different methods for estimating the risk of a collision. A physics simulation performed in the background is computationally expensive but provides the best results in deterministic environments. If a data-based risk estimator is used instead, the computational effort is significantly reduced, but an additional source of error is introduced. For evaluation, we successfully learn a reaching task and a basketball task while keeping the risk of collisions low. The results demonstrate the effectiveness of our approach for deterministic and stochastic environments, including a human-robot scenario and a ball environment, where no state can be considered permanently safe. By conducting experiments with a real robot, we show that our approach can generate safe trajectories in real time.
On Probabilistic Pullback Metrics on Latent Hyperbolic Manifolds
Oct 28, 2024Gaussian Process Latent Variable Models (GPLVMs) have proven effective in capturing complex, high-dimensional data through lower-dimensional representations. Recent advances show that using Riemannian manifolds as latent spaces provides more flexibility to learn higher quality embeddings. This paper focuses on the hyperbolic manifold, a particularly suitable choice for modeling hierarchical relationships. While previous approaches relied on hyperbolic geodesics for interpolating the latent space, this often results in paths crossing low-data regions, leading to highly uncertain predictions. Instead, we propose augmenting the hyperbolic metric with a pullback metric to account for distortions introduced by the GPLVM's nonlinear mapping. Through various experiments, we demonstrate that geodesics on the pullback metric not only respect the geometry of the hyperbolic latent space but also align with the underlying data distribution, significantly reducing uncertainty in predictions.
A Riemannian Framework for Learning Reduced-order Lagrangian Dynamics
Oct 24, 2024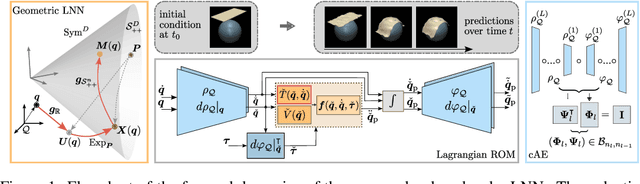
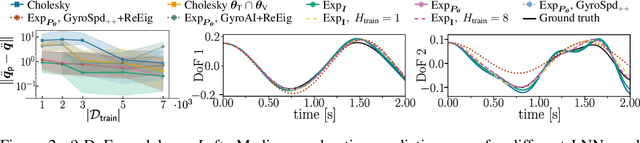
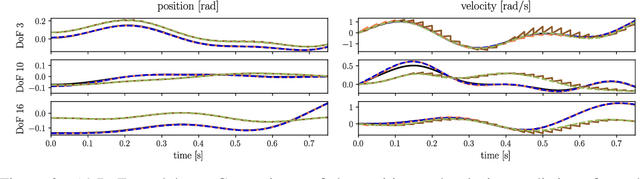
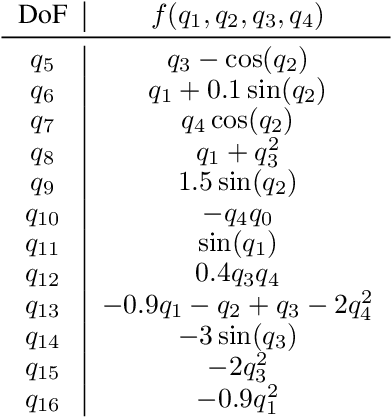
By incorporating physical consistency as inductive bias, deep neural networks display increased generalization capabilities and data efficiency in learning nonlinear dynamic models. However, the complexity of these models generally increases with the system dimensionality, requiring larger datasets, more complex deep networks, and significant computational effort. We propose a novel geometric network architecture to learn physically-consistent reduced-order dynamic parameters that accurately describe the original high-dimensional system behavior. This is achieved by building on recent advances in model-order reduction and by adopting a Riemannian perspective to jointly learn a structure-preserving latent space and the associated low-dimensional dynamics. Our approach enables accurate long-term predictions of the high-dimensional dynamics of rigid and deformable systems with increased data efficiency by inferring interpretable and physically plausible reduced Lagrangian models.
Learning Spatial Bimanual Action Models Based on Affordance Regions and Human Demonstrations
Oct 11, 2024In this paper, we present a novel approach for learning bimanual manipulation actions from human demonstration by extracting spatial constraints between affordance regions, termed affordance constraints, of the objects involved. Affordance regions are defined as object parts that provide interaction possibilities to an agent. For example, the bottom of a bottle affords the object to be placed on a surface, while its spout affords the contained liquid to be poured. We propose a novel approach to learn changes of affordance constraints in human demonstration to construct spatial bimanual action models representing object interactions. To exploit the information encoded in these spatial bimanual action models, we formulate an optimization problem to determine optimal object configurations across multiple execution keypoints while taking into account the initial scene, the learned affordance constraints, and the robot's kinematics. We evaluate the approach in simulation with two example tasks (pouring drinks and rolling dough) and compare three different definitions of affordance constraints: (i) component-wise distances between affordance regions in Cartesian space, (ii) component-wise distances between affordance regions in cylindrical space, and (iii) degrees of satisfaction of manually defined symbolic spatial affordance constraints.
Episodic Memory Verbalization using Hierarchical Representations of Life-Long Robot Experience
Sep 26, 2024Verbalization of robot experience, i.e., summarization of and question answering about a robot's past, is a crucial ability for improving human-robot interaction. Previous works applied rule-based systems or fine-tuned deep models to verbalize short (several-minute-long) streams of episodic data, limiting generalization and transferability. In our work, we apply large pretrained models to tackle this task with zero or few examples, and specifically focus on verbalizing life-long experiences. For this, we derive a tree-like data structure from episodic memory (EM), with lower levels representing raw perception and proprioception data, and higher levels abstracting events to natural language concepts. Given such a hierarchical representation built from the experience stream, we apply a large language model as an agent to interactively search the EM given a user's query, dynamically expanding (initially collapsed) tree nodes to find the relevant information. The approach keeps computational costs low even when scaling to months of robot experience data. We evaluate our method on simulated household robot data, human egocentric videos, and real-world robot recordings, demonstrating its flexibility and scalability.