 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters in Orchestrating Robot Policies: A Systematic Study of Hierarchical VLA Agents
Jun 09, 2026Hierarchical vision-language-action (Hi-VLA) systems have emerged as a promising paradigm for complex robot manipulation, by using high-level VLM planners to decompose tasks into language subgoals executed by low-level VLA controllers. Despite recent empirical progress, there is a lack of unified design principles for these systems: existing Hi-VLA systems differ in how they choose and connect planners, controllers, mechanisms to switch between the two, and how observations and memory are represented in the planner. In this paper, we present a systematic study of Hi-VLA design for robot manipulation. We unify representative Hi-VLA agents under an options-style control framework and benchmark core design choices across short-horizon, long-horizon, and reasoning-intensive tasks. Our analysis distills practical principles for building Hi-VLA systems, showing how model choices and interface mechanisms jointly shape performance. Applying these principles yields a substantially stronger system than either flat VLA control or a naively designed hierarchy, across experiments both in simulation and on a real ALOHA robot. Overall, our results provide a foundation for building more capable, robust, and principled hierarchical VLA agents. More information and video at jiahenghu.github.io/hi-vla.
ExoStart: Efficient learning for dexterous manipulation with sensorized exoskeleton demonstrations
Jun 13, 2025



Recent advancements in teleoperation systems have enabled high-quality data collection for robotic manipulators, showing impressive results in learning manipulation at scale. This progress suggests that extending these capabilities to robotic hands could unlock an even broader range of manipulation skills, especially if we could achieve the same level of dexterity that human hands exhibit. However, teleoperating robotic hands is far from a solved problem, as it presents a significant challenge due to the high degrees of freedom of robotic hands and the complex dynamics occurring during contact-rich settings. In this work, we present ExoStart, a general and scalable learning framework that leverages human dexterity to improve robotic hand control. In particular, we obtain high-quality data by collecting direct demonstrations without a robot in the loop using a sensorized low-cost wearable exoskeleton, capturing the rich behaviors that humans can demonstrate with their own hands. We also propose a simulation-based dynamics filter that generates dynamically feasible trajectories from the collected demonstrations and use the generated trajectories to bootstrap an auto-curriculum reinforcement learning method that relies only on simple sparse rewards. The ExoStart pipeline is generalizable and yields robust policies that transfer zero-shot to the real robot. Our results demonstrate that ExoStart can generate dexterous real-world hand skills, achieving a success rate above 50% on a wide range of complex tasks such as opening an AirPods case or inserting and turning a key in a lock. More details and videos can be found in https://sites.google.com/view/exostart.
Generative Image as Action Models
Jul 10, 2024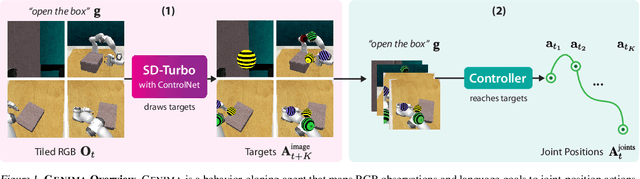

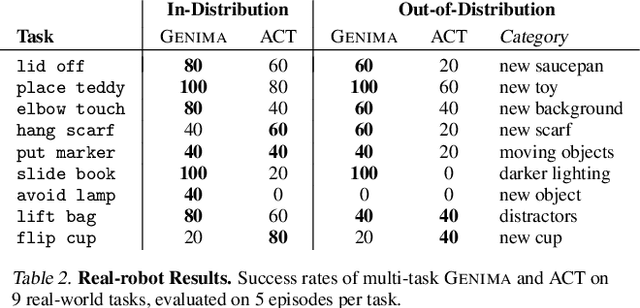
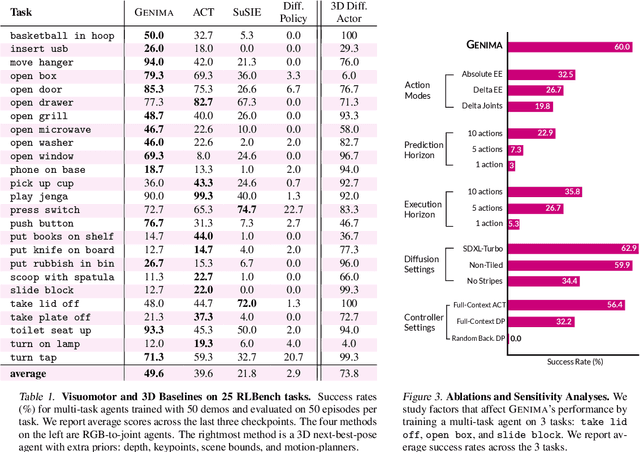
Image-generation diffusion models have been fine-tuned to unlock new capabilities such as image-editing and novel view synthesis. Can we similarly unlock image-generation models for visuomotor control? We present GENIMA, a behavior-cloning agent that fine-tunes Stable Diffusion to 'draw joint-actions' as targets on RGB images. These images are fed into a controller that maps the visual targets into a sequence of joint-positions. We study GENIMA on 25 RLBench and 9 real-world manipulation tasks. We find that, by lifting actions into image-space, internet pre-trained diffusion models can generate policies that outperform state-of-the-art visuomotor approaches, especially in robustness to scene perturbations and generalizing to novel objects. Our method is also competitive with 3D agents, despite lacking priors such as depth, keypoints, or motion-planners.
PerAct2: A Perceiver Actor Framework for Bimanual Manipulation Tasks
Jun 29, 2024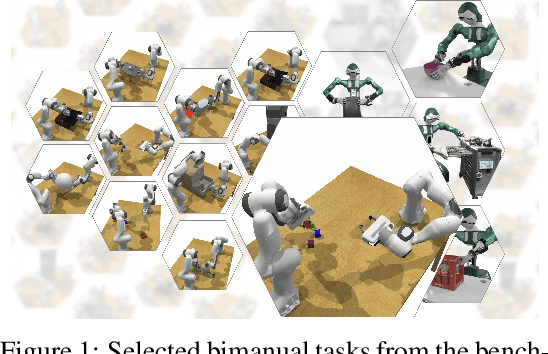
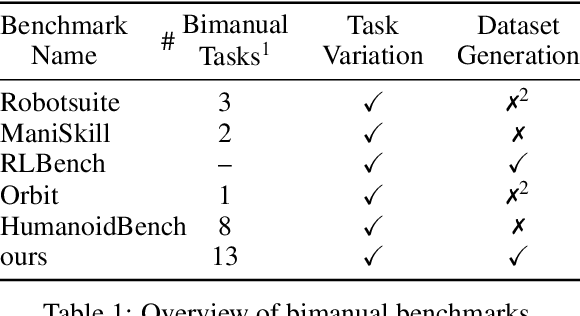
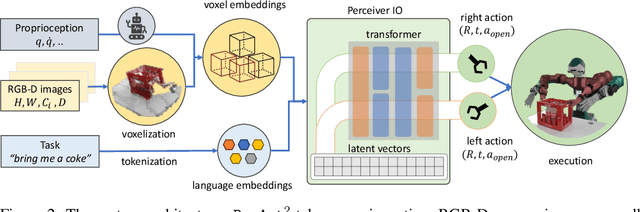

Bimanual manipulation is challenging due to precise spatial and temporal coordination required between two arms. While there exist several real-world bimanual systems, there is a lack of simulated benchmarks with a large task diversity for systematically studying bimanual capabilities across a wide range of tabletop tasks. This paper addresses the gap by extending RLBench to bimanual manipulation. We open-source our code and benchmark comprising 13 new tasks with 23 unique task variations, each requiring a high degree of coordination and adaptability. To kickstart the benchmark, we extended several state-of-the art methods to bimanual manipulation and also present a language-conditioned behavioral cloning agent -- PerAct2, which enables the learning and execution of bimanual 6-DoF manipulation tasks. Our novel network architecture efficiently integrates language processing with action prediction, allowing robots to understand and perform complex bimanual tasks in response to user-specified goals. Project website with code is available at: http://bimanual.github.io
GenSim: Generating Robotic Simulation Tasks via Large Language Models
Oct 02, 2023

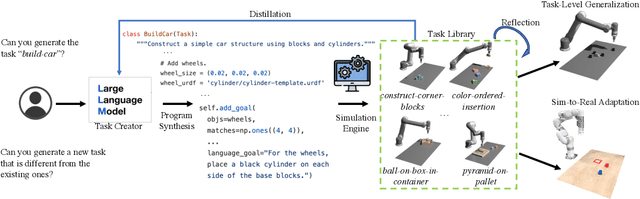
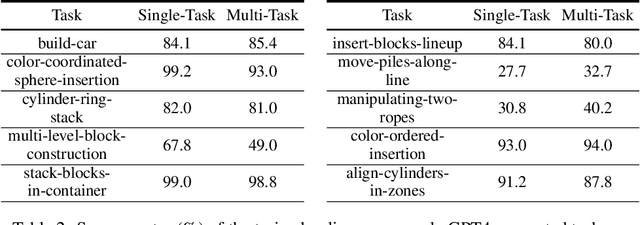
Collecting large amounts of real-world interaction data to train general robotic policies is often prohibitively expensive, thus motivating the use of simulation data. However, existing methods for data generation have generally focused on scene-level diversity (e.g., object instances and poses) rather than task-level diversity, due to the human effort required to come up with and verify novel tasks. This has made it challenging for policies trained on simulation data to demonstrate significant task-level generalization. In this paper, we propose to automatically generate rich simulation environments and expert demonstrations by exploiting a large language models' (LLM) grounding and coding ability. Our approach, dubbed GenSim, has two modes: goal-directed generation, wherein a target task is given to the LLM and the LLM proposes a task curriculum to solve the target task, and exploratory generation, wherein the LLM bootstraps from previous tasks and iteratively proposes novel tasks that would be helpful in solving more complex tasks. We use GPT4 to expand the existing benchmark by ten times to over 100 tasks, on which we conduct supervised finetuning and evaluate several LLMs including finetuned GPTs and Code Llama on code generation for robotic simulation tasks. Furthermore, we observe that LLMs-generated simulation programs can enhance task-level generalization significantly when used for multitask policy training. We further find that with minimal sim-to-real adaptation, the multitask policies pretrained on GPT4-generated simulation tasks exhibit stronger transfer to unseen long-horizon tasks in the real world and outperform baselines by 25%. See the project website (https://liruiw.github.io/gensim) for code, demos, and videos.
AR2-D2:Training a Robot Without a Robot
Jun 23, 2023Diligently gathered human demonstrations serve as the unsung heroes empowering the progression of robot learning. Today, demonstrations are collected by training people to use specialized controllers, which (tele-)operate robots to manipulate a small number of objects. By contrast, we introduce AR2-D2: a system for collecting demonstrations which (1) does not require people with specialized training, (2) does not require any real robots during data collection, and therefore, (3) enables manipulation of diverse objects with a real robot. AR2-D2 is a framework in the form of an iOS app that people can use to record a video of themselves manipulating any object while simultaneously capturing essential data modalities for training a real robot. We show that data collected via our system enables the training of behavior cloning agents in manipulating real objects. Our experiments further show that training with our AR data is as effective as training with real-world robot demonstrations. Moreover, our user study indicates that users find AR2-D2 intuitive to use and require no training in contrast to four other frequently employed methods for collecting robot demonstrations.
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

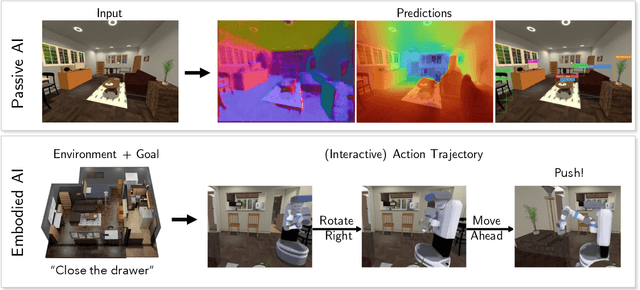
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.
Perceiver-Actor: A Multi-Task Transformer for Robotic Manipulation
Sep 12, 2022
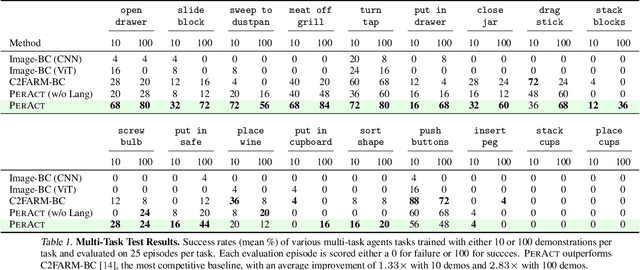
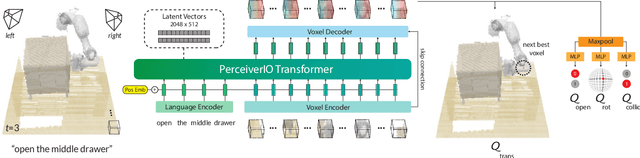
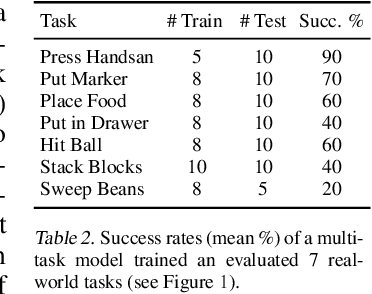
Transformers have revolutionized vision and natural language processing with their ability to scale with large datasets. But in robotic manipulation, data is both limited and expensive. Can we still benefit from Transformers with the right problem formulation? We investigate this question with PerAct, a language-conditioned behavior-cloning agent for multi-task 6-DoF manipulation. PerAct encodes language goals and RGB-D voxel observations with a Perceiver Transformer, and outputs discretized actions by "detecting the next best voxel action". Unlike frameworks that operate on 2D images, the voxelized observation and action space provides a strong structural prior for efficiently learning 6-DoF policies. With this formulation, we train a single multi-task Transformer for 18 RLBench tasks (with 249 variations) and 7 real-world tasks (with 18 variations) from just a few demonstrations per task. Our results show that PerAct significantly outperforms unstructured image-to-action agents and 3D ConvNet baselines for a wide range of tabletop tasks.
CLIPort: What and Where Pathways for Robotic Manipulation
Sep 24, 2021

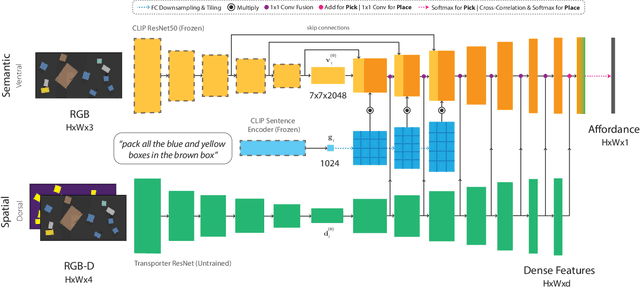

How can we imbue robots with the ability to manipulate objects precisely but also to reason about them in terms of abstract concepts? Recent works in manipulation have shown that end-to-end networks can learn dexterous skills that require precise spatial reasoning, but these methods often fail to generalize to new goals or quickly learn transferable concepts across tasks. In parallel, there has been great progress in learning generalizable semantic representations for vision and language by training on large-scale internet data, however these representations lack the spatial understanding necessary for fine-grained manipulation. To this end, we propose a framework that combines the best of both worlds: a two-stream architecture with semantic and spatial pathways for vision-based manipulation. Specifically, we present CLIPort, a language-conditioned imitation-learning agent that combines the broad semantic understanding (what) of CLIP [1] with the spatial precision (where) of Transporter [2]. Our end-to-end framework is capable of solving a variety of language-specified tabletop tasks from packing unseen objects to folding cloths, all without any explicit representations of object poses, instance segmentations, memory, symbolic states, or syntactic structures. Experiments in simulated and real-world settings show that our approach is data efficient in few-shot settings and generalizes effectively to seen and unseen semantic concepts. We even learn one multi-task policy for 10 simulated and 9 real-world tasks that is better or comparable to single-task policies.
Language Grounding with 3D Objects
Jul 26, 2021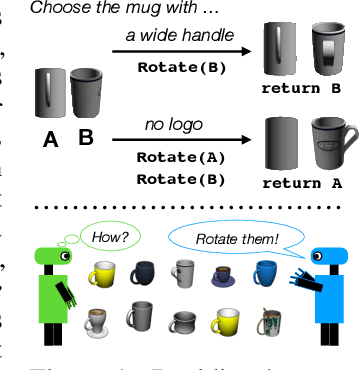
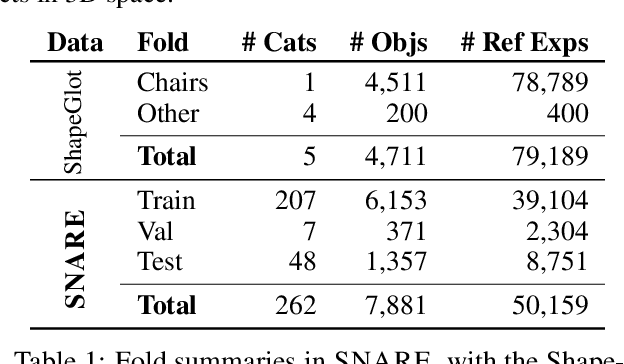
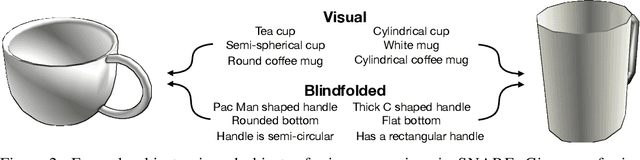
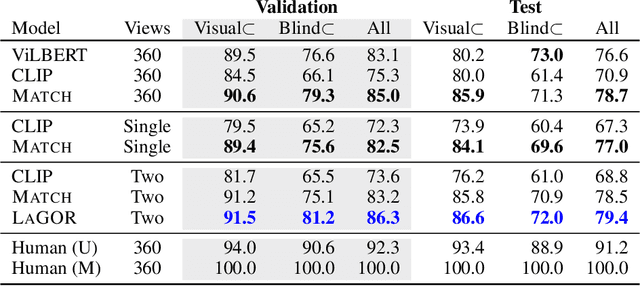
Seemingly simple natural language requests to a robot are generally underspecified, for example "Can you bring me the wireless mouse?" When viewing mice on the shelf, the number of buttons or presence of a wire may not be visible from certain angles or positions. Flat images of candidate mice may not provide the discriminative information needed for "wireless". The world, and objects in it, are not flat images but complex 3D shapes. If a human requests an object based on any of its basic properties, such as color, shape, or texture, robots should perform the necessary exploration to accomplish the task. In particular, while substantial effort and progress has been made on understanding explicitly visual attributes like color and category, comparatively little progress has been made on understanding language about shapes and contours. In this work, we introduce a novel reasoning task that targets both visual and non-visual language about 3D objects. Our new benchmark, ShapeNet Annotated with Referring Expressions (SNARE), requires a model to choose which of two objects is being referenced by a natural language description. We introduce several CLIP-based models for distinguishing objects and demonstrate that while recent advances in jointly modeling vision and language are useful for robotic language understanding, it is still the case that these models are weaker at understanding the 3D nature of objects -- properties which play a key role in manipulation. In particular, we find that adding view estimation to language grounding models improves accuracy on both SNARE and when identifying objects referred to in language on a robot platform.