 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTetraGrip: Sensor-Driven Multi-Suction Reactive Object Manipulation in Cluttered Scenes
Mar 12, 2025



Warehouse robotic systems equipped with vacuum grippers must reliably grasp a diverse range of objects from densely packed shelves. However, these environments present significant challenges, including occlusions, diverse object orientations, stacked and obstructed items, and surfaces that are difficult to suction. We introduce \tetra, a novel vacuum-based grasping strategy featuring four suction cups mounted on linear actuators. Each actuator is equipped with an optical time-of-flight (ToF) proximity sensor, enabling reactive grasping. We evaluate \tetra in a warehouse-style setting, demonstrating its ability to manipulate objects in stacked and obstructed configurations. Our results show that our RL-based policy improves picking success in stacked-object scenarios by 22.86\% compared to a single-suction gripper. Additionally, we demonstrate that TetraGrip can successfully grasp objects in scenarios where a single-suction gripper fails due to physical limitations, specifically in two cases: (1) picking an object occluded by another object and (2) retrieving an object in a complex scenario. These findings highlight the advantages of multi-actuated, suction-based grasping in unstructured warehouse environments. The project website is available at: \href{https://tetragrip.github.io/}{https://tetragrip.github.io/}.
SAM2Act: Integrating Visual Foundation Model with A Memory Architecture for Robotic Manipulation
Jan 30, 2025



Robotic manipulation systems operating in diverse, dynamic environments must exhibit three critical abilities: multitask interaction, generalization to unseen scenarios, and spatial memory. While significant progress has been made in robotic manipulation, existing approaches often fall short in generalization to complex environmental variations and addressing memory-dependent tasks. To bridge this gap, we introduce SAM2Act, a multi-view robotic transformer-based policy that leverages multi-resolution upsampling with visual representations from large-scale foundation model. SAM2Act achieves a state-of-the-art average success rate of 86.8% across 18 tasks in the RLBench benchmark, and demonstrates robust generalization on The Colosseum benchmark, with only a 4.3% performance gap under diverse environmental perturbations. Building on this foundation, we propose SAM2Act+, a memory-based architecture inspired by SAM2, which incorporates a memory bank, an encoder, and an attention mechanism to enhance spatial memory. To address the need for evaluating memory-dependent tasks, we introduce MemoryBench, a novel benchmark designed to assess spatial memory and action recall in robotic manipulation. SAM2Act+ achieves competitive performance on MemoryBench, significantly outperforming existing approaches and pushing the boundaries of memory-enabled robotic systems. Project page: https://sam2act.github.io/
OptiGrasp: Optimized Grasp Pose Detection Using RGB Images for Warehouse Picking Robots
Sep 29, 2024



In warehouse environments, robots require robust picking capabilities to manage a wide variety of objects. Effective deployment demands minimal hardware, strong generalization to new products, and resilience in diverse settings. Current methods often rely on depth sensors for structural information, which suffer from high costs, complex setups, and technical limitations. Inspired by recent advancements in computer vision, we propose an innovative approach that leverages foundation models to enhance suction grasping using only RGB images. Trained solely on a synthetic dataset, our method generalizes its grasp prediction capabilities to real-world robots and a diverse range of novel objects not included in the training set. Our network achieves an 82.3\% success rate in real-world applications. The project website with code and data will be available at http://optigrasp.github.io.
PerAct2: A Perceiver Actor Framework for Bimanual Manipulation Tasks
Jun 29, 2024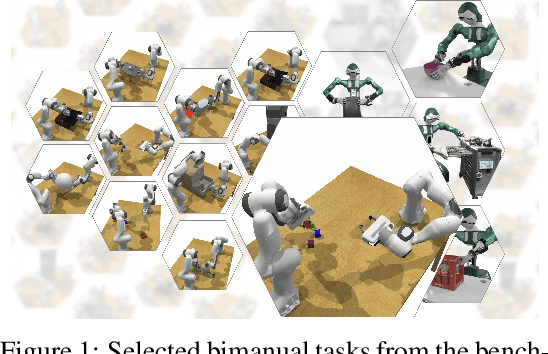
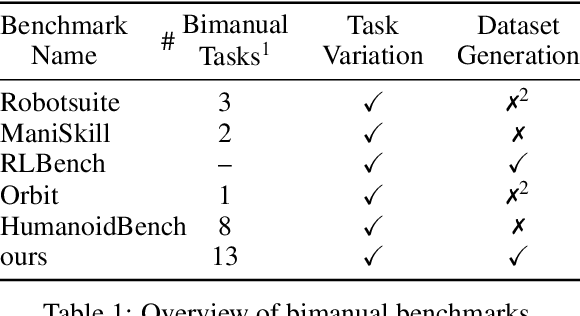
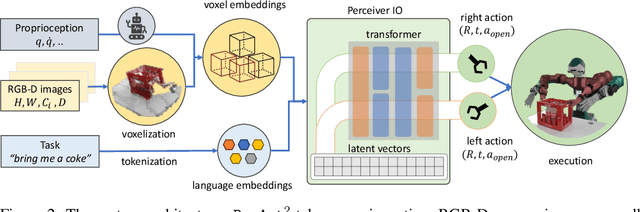

Bimanual manipulation is challenging due to precise spatial and temporal coordination required between two arms. While there exist several real-world bimanual systems, there is a lack of simulated benchmarks with a large task diversity for systematically studying bimanual capabilities across a wide range of tabletop tasks. This paper addresses the gap by extending RLBench to bimanual manipulation. We open-source our code and benchmark comprising 13 new tasks with 23 unique task variations, each requiring a high degree of coordination and adaptability. To kickstart the benchmark, we extended several state-of-the art methods to bimanual manipulation and also present a language-conditioned behavioral cloning agent -- PerAct2, which enables the learning and execution of bimanual 6-DoF manipulation tasks. Our novel network architecture efficiently integrates language processing with action prediction, allowing robots to understand and perform complex bimanual tasks in response to user-specified goals. Project website with code is available at: http://bimanual.github.io
STOW: Discrete-Frame Segmentation and Tracking of Unseen Objects for Warehouse Picking Robots
Nov 04, 2023



Segmentation and tracking of unseen object instances in discrete frames pose a significant challenge in dynamic industrial robotic contexts, such as distribution warehouses. Here, robots must handle object rearrangement, including shifting, removal, and partial occlusion by new items, and track these items after substantial temporal gaps. The task is further complicated when robots encounter objects not learned in their training sets, which requires the ability to segment and track previously unseen items. Considering that continuous observation is often inaccessible in such settings, our task involves working with a discrete set of frames separated by indefinite periods during which substantial changes to the scene may occur. This task also translates to domestic robotic applications, such as rearrangement of objects on a table. To address these demanding challenges, we introduce new synthetic and real-world datasets that replicate these industrial and household scenarios. We also propose a novel paradigm for joint segmentation and tracking in discrete frames along with a transformer module that facilitates efficient inter-frame communication. The experiments we conduct show that our approach significantly outperforms recent methods. For additional results and videos, please visit \href{https://sites.google.com/view/stow-corl23}{website}. Code and dataset will be released.
Conceptual Design of the Memory System of the Robot Cognitive Architecture ArmarX
Jun 05, 2022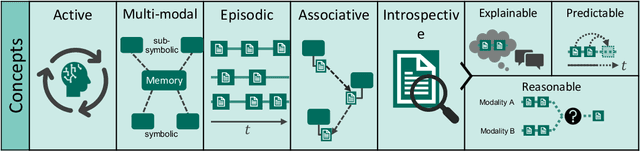
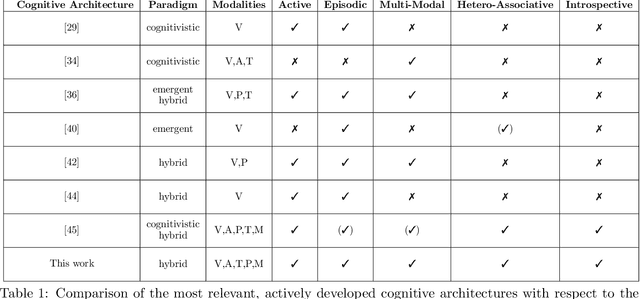
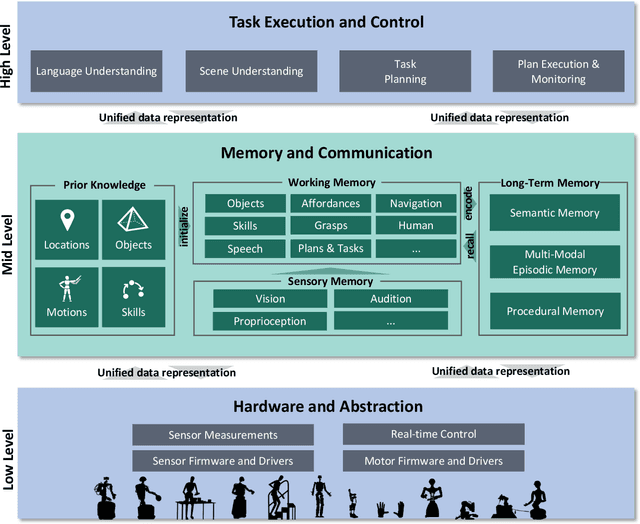
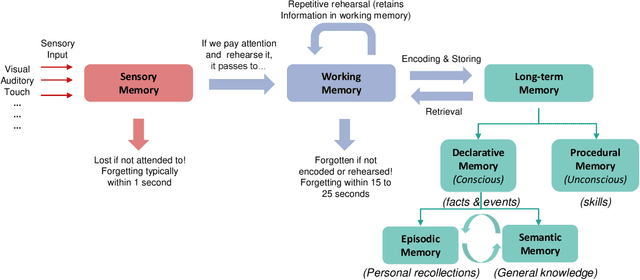
We consider the memory system as a key component of any technical cognitive system that can play a central role in bridging the gap between high-level symbolic discrete representations used for reasoning, planning and semantic scene understanding and low-level sensorimotor continuous representations used for control. In this work we described conceptual and technical characteristics such a memory system has to fulfill, together with the underlying data representation. We identify these characteristics based on the experience we gained in developing our ARMAR humanoid robot systems and discuss practical examples that demonstrate what a memory system of a humanoid robot performing tasks in human-centered environments should support, such as multi-modality, introspectability, hetero associativity, predictability or an inherently episodic structure. Based on these characteristics, we extended our robot software framework ArmarX into a unified cognitive architecture that is used in robots of the ARMAR humanoid robot family. Further, we describe, how the development of robot software led us to this novel memory-enabled cognitive architecture and we show how the memory is used by the robots to implement memory-driven behaviors.
Multimodal Gaze Stabilization of a Humanoid Robot based on Reafferences
Mar 01, 2017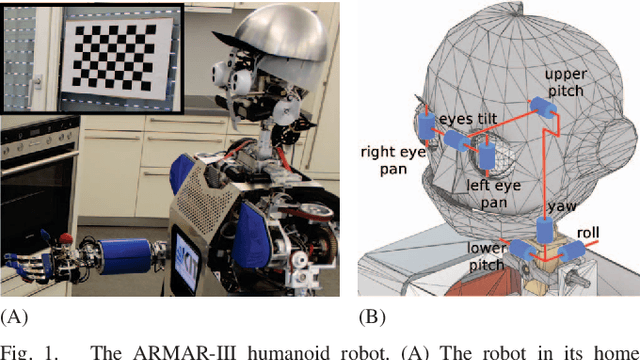

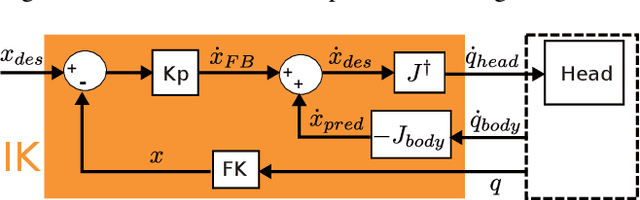
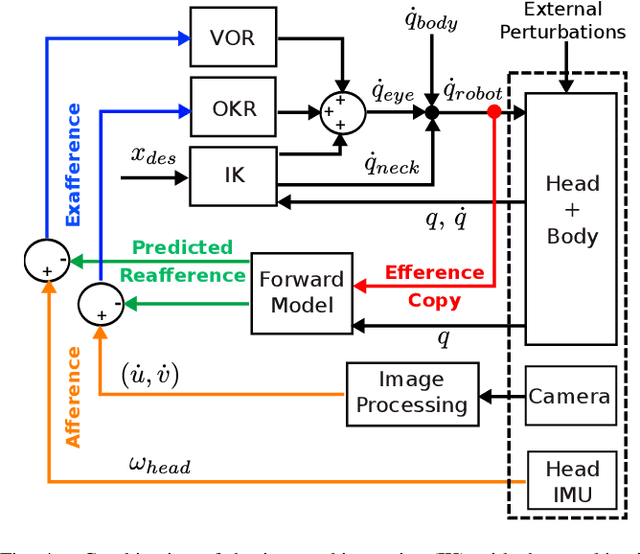
Gaze stabilization is fundamental for humanoid robots. By stabilizing vision, it enhances perception of the environment and keeps points of interest in the field of view. In this contribution, a multimodal gaze stabilization combining classic inverse kinematic control with vestibulo-ocular and optokinetic reflexes is introduced. Inspired by neuroscience, it implements a forward model that can modulate the reflexes based on the reafference principle. This principle filters self-generated movements out of the reflexive feedback loop. The versatility and effectiveness of this method are experimentally validated on the Armar-III humanoid robot. It is first demonstrated that each stabilization mechanism (inverse kinematics and reflexes) performs better than the others as a function of the type of perturbation to be stabilized. Furthermore, combining these three modalities by reafference provides a universal gaze stabilizer which can handle any kind of perturbation.