 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptual Design of the Memory System of the Robot Cognitive Architecture ArmarX
Jun 05, 2022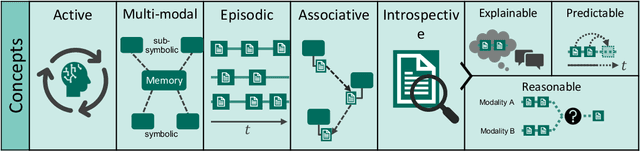
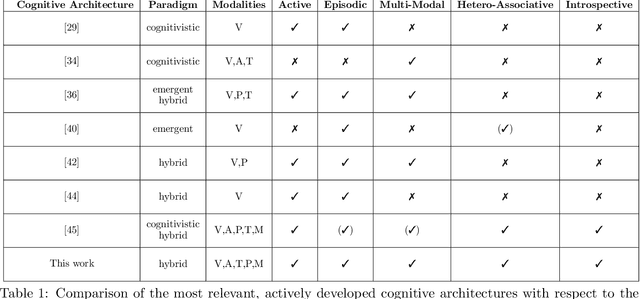
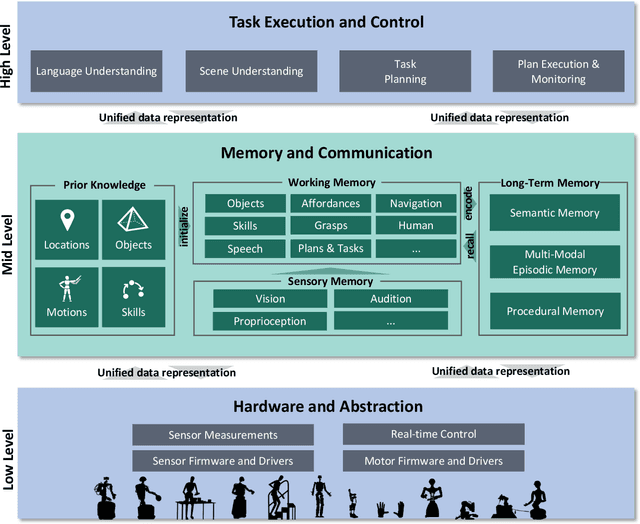
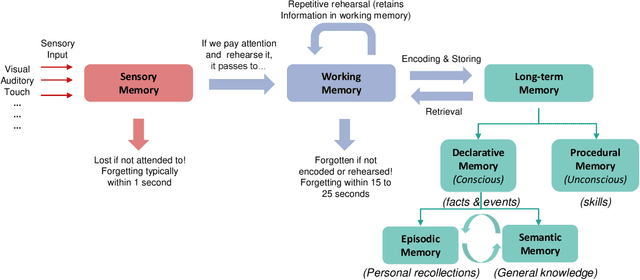
We consider the memory system as a key component of any technical cognitive system that can play a central role in bridging the gap between high-level symbolic discrete representations used for reasoning, planning and semantic scene understanding and low-level sensorimotor continuous representations used for control. In this work we described conceptual and technical characteristics such a memory system has to fulfill, together with the underlying data representation. We identify these characteristics based on the experience we gained in developing our ARMAR humanoid robot systems and discuss practical examples that demonstrate what a memory system of a humanoid robot performing tasks in human-centered environments should support, such as multi-modality, introspectability, hetero associativity, predictability or an inherently episodic structure. Based on these characteristics, we extended our robot software framework ArmarX into a unified cognitive architecture that is used in robots of the ARMAR humanoid robot family. Further, we describe, how the development of robot software led us to this novel memory-enabled cognitive architecture and we show how the memory is used by the robots to implement memory-driven behaviors.
Learning Object-Action Relations from Bimanual Human Demonstration Using Graph Networks
Sep 12, 2019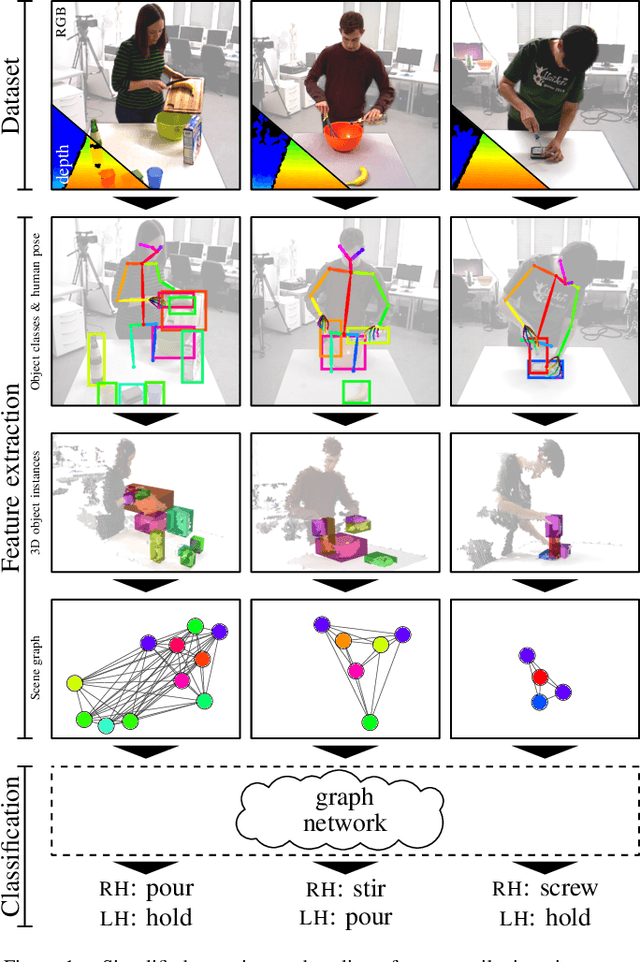

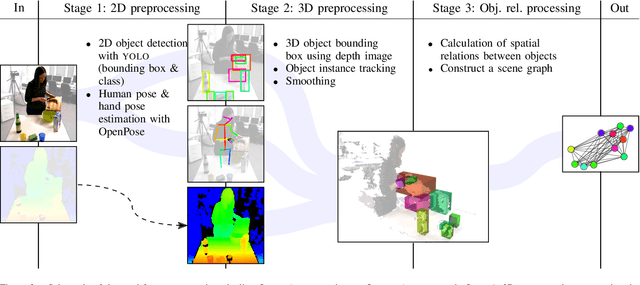
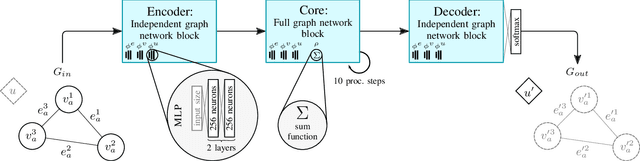
Recognizing human actions is a vital task for a humanoid robot, especially in domains like programming by demonstration. Previous approaches on action recognition primarily focused on the overall prevalent action being executed, but we argue that bimanual human motion cannot always be described sufficiently with a single action label. We present a system for frame-wise action classification and segmentation in bimanual human demonstrations. The system extracts symbolic spatial object relations from raw RGB-D video data captured from the robot's point of view in order to build graph-based scene representations. To learn object-action relations, a graph network classifier is trained using these representations together with ground truth action labels to predict the action executed by each hand. We evaluated the proposed classifier on a new RGB-D video dataset showing daily action sequences focusing on bimanual manipulation actions. It consists of 6 subjects performing 9 tasks with 10 repetitions each, which leads to 540 video recordings with 2 hours and 18 minutes total playtime and per-hand ground truth action labels for each frame. We show that the classifier is able to reliably identify (action classification macro F1-score of 0.86) the true executed action of each hand within its top 3 predictions on a frame-by-frame basis without prior temporal action segmentation.
A Framework for Evaluating Motion Segmentation Algorithms
Sep 30, 2018
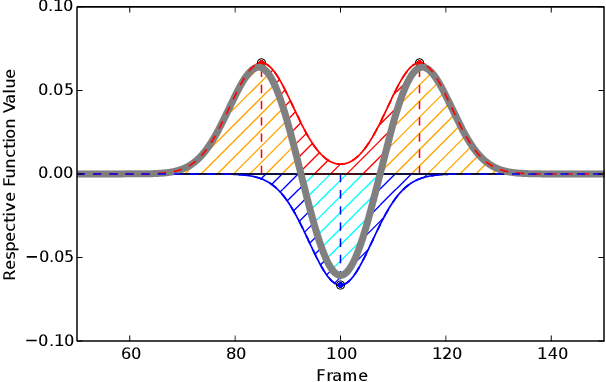
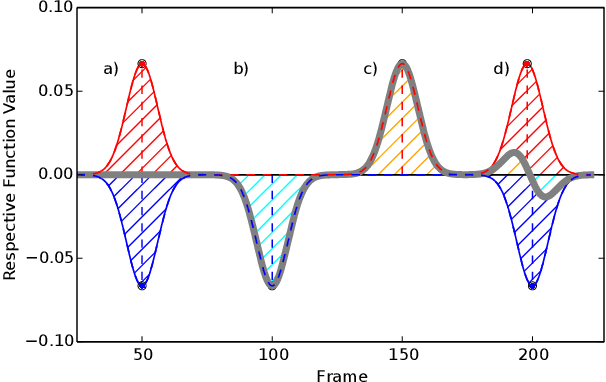
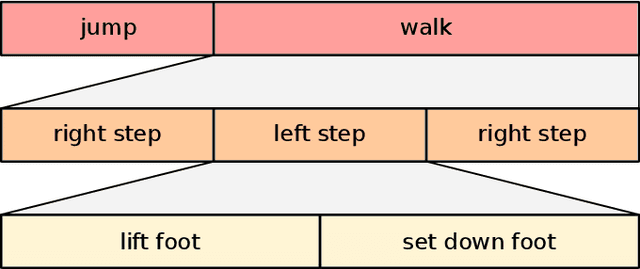
There have been many proposals for algorithms segmenting human whole-body motion in the literature. However, the wide range of use cases, datasets, and quality measures that were used for the evaluation render the comparison of algorithms challenging. In this paper, we introduce a framework that puts motion segmentation algorithms on a unified testing ground and provides a possibility to allow comparing them. The testing ground features both a set of quality measures known from the literature and a novel approach tailored to the evaluation of motion segmentation algorithms, termed Integrated Kernel approach. Datasets of motion recordings, provided with a ground truth, are included as well. They are labelled in a new way, which hierarchically organises the ground truth, to cover different use cases that segmentation algorithms can possess. The framework and datasets are publicly available and are intended to represent a service for the community regarding the comparison and evaluation of existing and new motion segmentation algorithms.