 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Spatial Bimanual Action Models Based on Affordance Regions and Human Demonstrations
Oct 11, 2024In this paper, we present a novel approach for learning bimanual manipulation actions from human demonstration by extracting spatial constraints between affordance regions, termed affordance constraints, of the objects involved. Affordance regions are defined as object parts that provide interaction possibilities to an agent. For example, the bottom of a bottle affords the object to be placed on a surface, while its spout affords the contained liquid to be poured. We propose a novel approach to learn changes of affordance constraints in human demonstration to construct spatial bimanual action models representing object interactions. To exploit the information encoded in these spatial bimanual action models, we formulate an optimization problem to determine optimal object configurations across multiple execution keypoints while taking into account the initial scene, the learned affordance constraints, and the robot's kinematics. We evaluate the approach in simulation with two example tasks (pouring drinks and rolling dough) and compare three different definitions of affordance constraints: (i) component-wise distances between affordance regions in Cartesian space, (ii) component-wise distances between affordance regions in cylindrical space, and (iii) degrees of satisfaction of manually defined symbolic spatial affordance constraints.
Incremental Learning of Full-Pose Via-Point Movement Primitives on Riemannian Manifolds
Dec 13, 2023



Movement primitives (MPs) are compact representations of robot skills that can be learned from demonstrations and combined into complex behaviors. However, merely equipping robots with a fixed set of innate MPs is insufficient to deploy them in dynamic and unpredictable environments. Instead, the full potential of MPs remains to be attained via adaptable, large-scale MP libraries. In this paper, we propose a set of seven fundamental operations to incrementally learn, improve, and re-organize MP libraries. To showcase their applicability, we provide explicit formulations of the spatial operations for libraries composed of Via-Point Movement Primitives (VMPs). By building on Riemannian manifold theory, our approach enables the incremental learning of all parameters of position and orientation VMPs within a library. Moreover, our approach stores a fixed number of parameters, thus complying with the essential principles of incremental learning. We evaluate our approach to incrementally learn a VMP library from motion capture data provided sequentially.
On the Design of Region-Avoiding Metrics for Collision-Safe Motion Generation on Riemannian Manifolds
Jul 28, 2023The generation of energy-efficient and dynamic-aware robot motions that satisfy constraints such as joint limits, self-collisions, and collisions with the environment remains a challenge. In this context, Riemannian geometry offers promising solutions by identifying robot motions with geodesics on the so-called configuration space manifold. While this manifold naturally considers the intrinsic robot dynamics, constraints such as joint limits, self-collisions, and collisions with the environment remain overlooked. In this paper, we propose a modification of the Riemannian metric of the configuration space manifold allowing for the generation of robot motions as geodesics that efficiently avoid given regions. We introduce a class of Riemannian metrics based on barrier functions that guarantee strict region avoidance by systematically generating accelerations away from no-go regions in joint and task space. We evaluate the proposed Riemannian metric to generate energy-efficient, dynamic-aware, and collision-free motions of a humanoid robot as geodesics and sequences thereof.
A Riemannian Take on Human Motion Analysis and Retargeting
Aug 02, 2022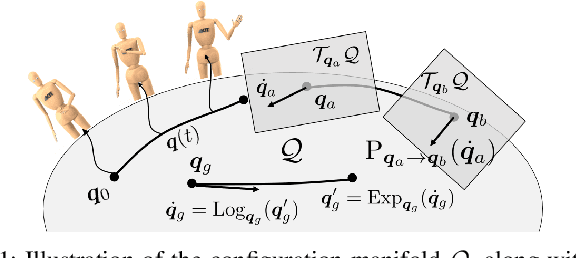
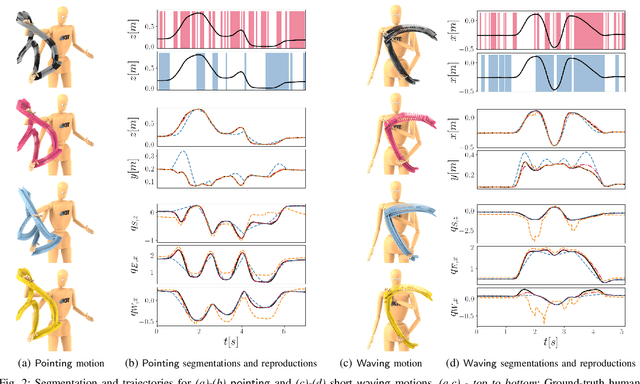
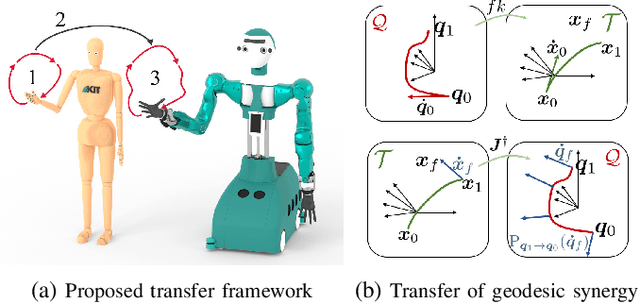
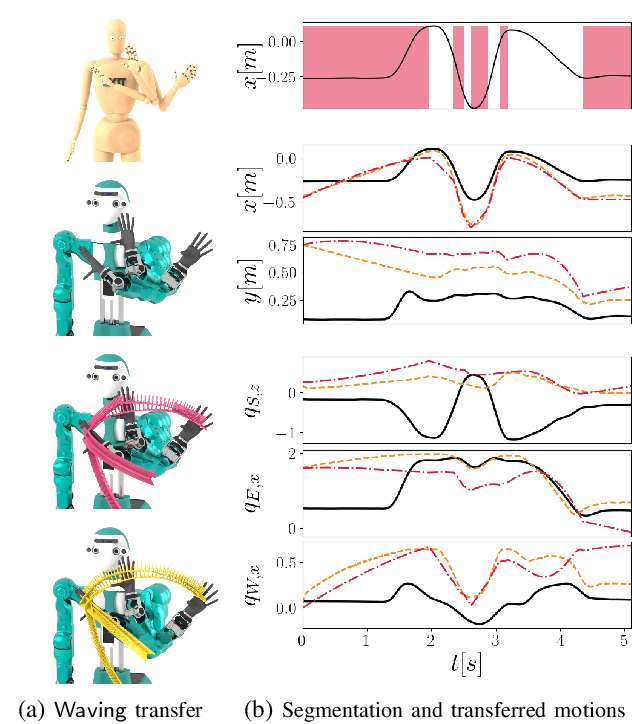
Dynamic motions of humans and robots are widely driven by posture-dependent nonlinear interactions between their degrees of freedom. However, these dynamical effects remain mostly overlooked when studying the mechanisms of human movement generation. Inspired by recent works, we hypothesize that human motions are planned as sequences of geodesic synergies, and thus correspond to coordinated joint movements achieved with piecewise minimum energy. The underlying computational model is built on Riemannian geometry to account for the inertial characteristics of the body. Through the analysis of various human arm motions, we find that our model segments motions into geodesic synergies, and successfully predicts observed arm postures, hand trajectories, as well as their respective velocity profiles. Moreover, we show that our analysis can further be exploited to transfer arm motions to robots by reproducing individual human synergies as geodesic paths in the robot configuration space.
Conceptual Design of the Memory System of the Robot Cognitive Architecture ArmarX
Jun 05, 2022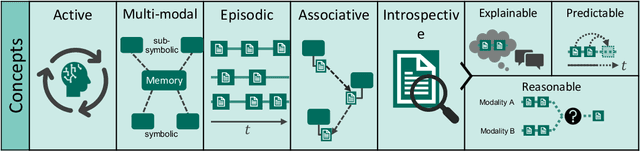
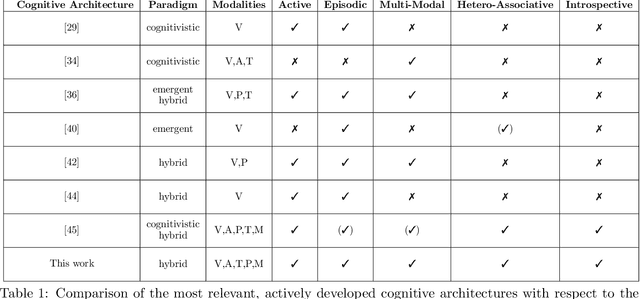
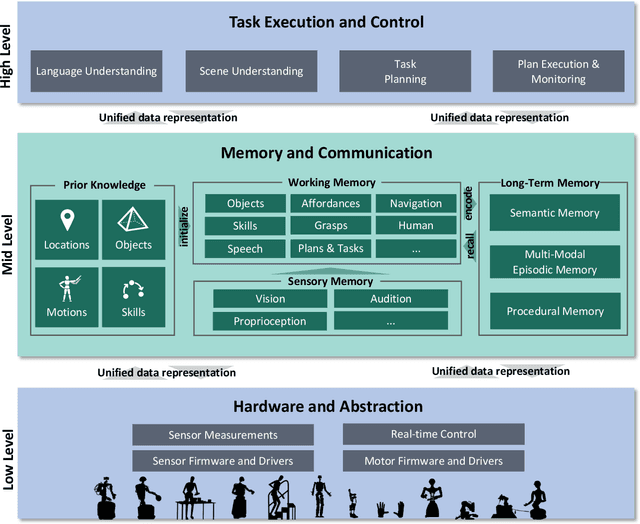
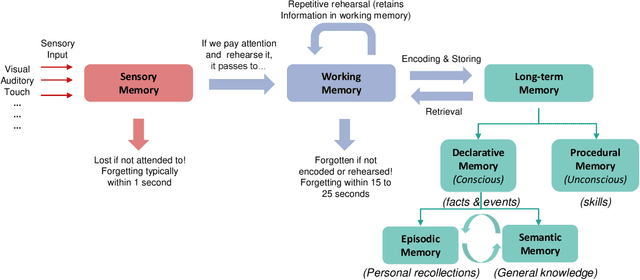
We consider the memory system as a key component of any technical cognitive system that can play a central role in bridging the gap between high-level symbolic discrete representations used for reasoning, planning and semantic scene understanding and low-level sensorimotor continuous representations used for control. In this work we described conceptual and technical characteristics such a memory system has to fulfill, together with the underlying data representation. We identify these characteristics based on the experience we gained in developing our ARMAR humanoid robot systems and discuss practical examples that demonstrate what a memory system of a humanoid robot performing tasks in human-centered environments should support, such as multi-modality, introspectability, hetero associativity, predictability or an inherently episodic structure. Based on these characteristics, we extended our robot software framework ArmarX into a unified cognitive architecture that is used in robots of the ARMAR humanoid robot family. Further, we describe, how the development of robot software led us to this novel memory-enabled cognitive architecture and we show how the memory is used by the robots to implement memory-driven behaviors.