 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Object-Action Relations from Bimanual Human Demonstration Using Graph Networks
Paper and Code
Sep 12, 2019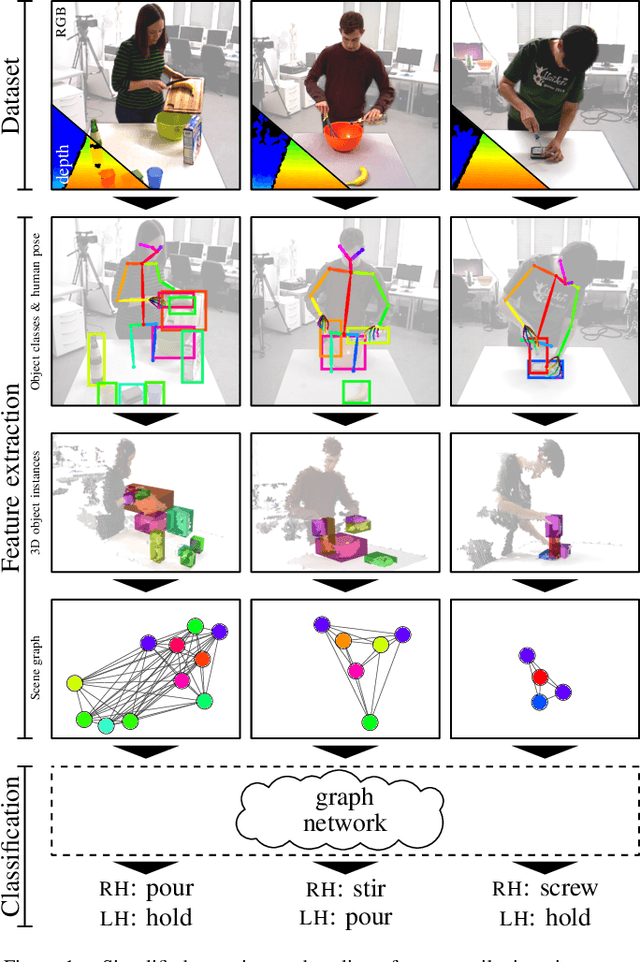

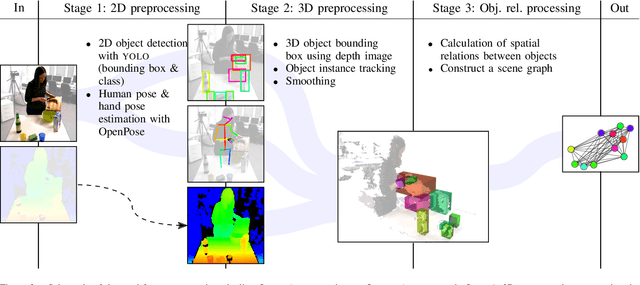
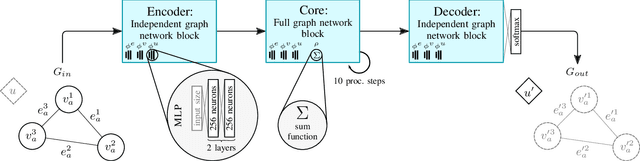
Recognizing human actions is a vital task for a humanoid robot, especially in domains like programming by demonstration. Previous approaches on action recognition primarily focused on the overall prevalent action being executed, but we argue that bimanual human motion cannot always be described sufficiently with a single action label. We present a system for frame-wise action classification and segmentation in bimanual human demonstrations. The system extracts symbolic spatial object relations from raw RGB-D video data captured from the robot's point of view in order to build graph-based scene representations. To learn object-action relations, a graph network classifier is trained using these representations together with ground truth action labels to predict the action executed by each hand. We evaluated the proposed classifier on a new RGB-D video dataset showing daily action sequences focusing on bimanual manipulation actions. It consists of 6 subjects performing 9 tasks with 10 repetitions each, which leads to 540 video recordings with 2 hours and 18 minutes total playtime and per-hand ground truth action labels for each frame. We show that the classifier is able to reliably identify (action classification macro F1-score of 0.86) the true executed action of each hand within its top 3 predictions on a frame-by-frame basis without prior temporal action segmentation.