 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Grounding with 3D Objects
Paper and Code
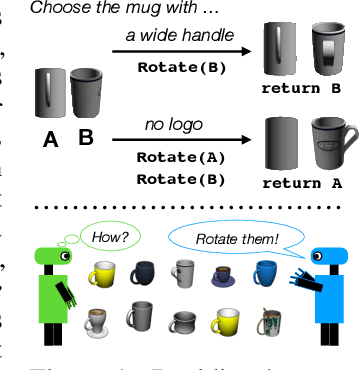
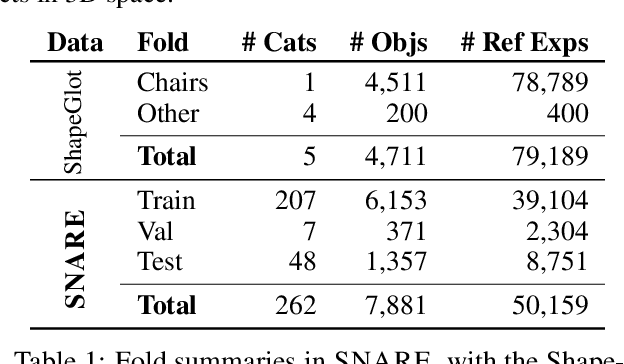
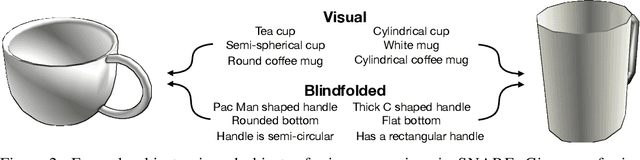
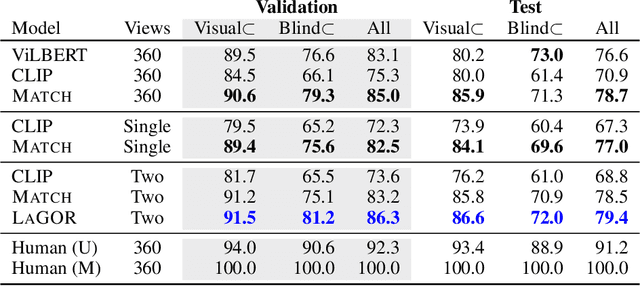
Seemingly simple natural language requests to a robot are generally underspecified, for example "Can you bring me the wireless mouse?" When viewing mice on the shelf, the number of buttons or presence of a wire may not be visible from certain angles or positions. Flat images of candidate mice may not provide the discriminative information needed for "wireless". The world, and objects in it, are not flat images but complex 3D shapes. If a human requests an object based on any of its basic properties, such as color, shape, or texture, robots should perform the necessary exploration to accomplish the task. In particular, while substantial effort and progress has been made on understanding explicitly visual attributes like color and category, comparatively little progress has been made on understanding language about shapes and contours. In this work, we introduce a novel reasoning task that targets both visual and non-visual language about 3D objects. Our new benchmark, ShapeNet Annotated with Referring Expressions (SNARE), requires a model to choose which of two objects is being referenced by a natural language description. We introduce several CLIP-based models for distinguishing objects and demonstrate that while recent advances in jointly modeling vision and language are useful for robotic language understanding, it is still the case that these models are weaker at understanding the 3D nature of objects -- properties which play a key role in manipulation. In particular, we find that adding view estimation to language grounding models improves accuracy on both SNARE and when identifying objects referred to in language on a robot platform.