 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShelving, Stacking, Hanging: Relational Pose Diffusion for Multi-modal Rearrangement
Jul 10, 2023


We propose a system for rearranging objects in a scene to achieve a desired object-scene placing relationship, such as a book inserted in an open slot of a bookshelf. The pipeline generalizes to novel geometries, poses, and layouts of both scenes and objects, and is trained from demonstrations to operate directly on 3D point clouds. Our system overcomes challenges associated with the existence of many geometrically-similar rearrangement solutions for a given scene. By leveraging an iterative pose de-noising training procedure, we can fit multi-modal demonstration data and produce multi-modal outputs while remaining precise and accurate. We also show the advantages of conditioning on relevant local geometric features while ignoring irrelevant global structure that harms both generalization and precision. We demonstrate our approach on three distinct rearrangement tasks that require handling multi-modality and generalization over object shape and pose in both simulation and the real world. Project website, code, and videos: https://anthonysimeonov.github.io/rpdiff-multi-modal/
MegaPose: 6D Pose Estimation of Novel Objects via Render & Compare
Dec 13, 2022



We introduce MegaPose, a method to estimate the 6D pose of novel objects, that is, objects unseen during training. At inference time, the method only assumes knowledge of (i) a region of interest displaying the object in the image and (ii) a CAD model of the observed object. The contributions of this work are threefold. First, we present a 6D pose refiner based on a render&compare strategy which can be applied to novel objects. The shape and coordinate system of the novel object are provided as inputs to the network by rendering multiple synthetic views of the object's CAD model. Second, we introduce a novel approach for coarse pose estimation which leverages a network trained to classify whether the pose error between a synthetic rendering and an observed image of the same object can be corrected by the refiner. Third, we introduce a large-scale synthetic dataset of photorealistic images of thousands of objects with diverse visual and shape properties and show that this diversity is crucial to obtain good generalization performance on novel objects. We train our approach on this large synthetic dataset and apply it without retraining to hundreds of novel objects in real images from several pose estimation benchmarks. Our approach achieves state-of-the-art performance on the ModelNet and YCB-Video datasets. An extensive evaluation on the 7 core datasets of the BOP challenge demonstrates that our approach achieves performance competitive with existing approaches that require access to the target objects during training. Code, dataset and trained models are available on the project page: https://megapose6d.github.io/.
Perceiver-Actor: A Multi-Task Transformer for Robotic Manipulation
Sep 12, 2022
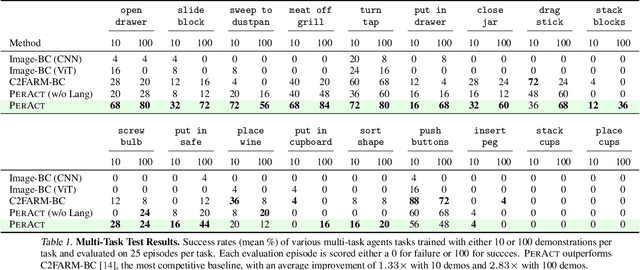
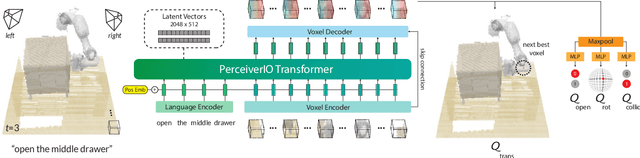
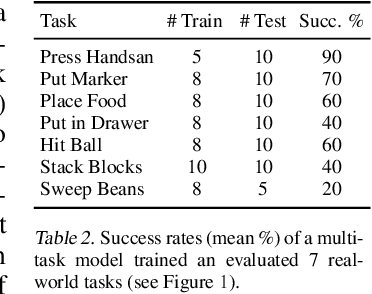
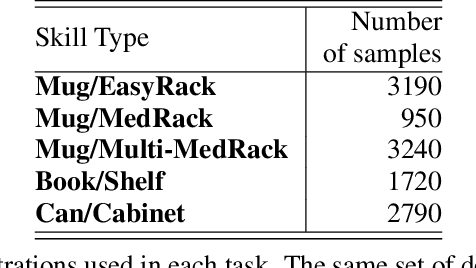
Transformers have revolutionized vision and natural language processing with their ability to scale with large datasets. But in robotic manipulation, data is both limited and expensive. Can we still benefit from Transformers with the right problem formulation? We investigate this question with PerAct, a language-conditioned behavior-cloning agent for multi-task 6-DoF manipulation. PerAct encodes language goals and RGB-D voxel observations with a Perceiver Transformer, and outputs discretized actions by "detecting the next best voxel action". Unlike frameworks that operate on 2D images, the voxelized observation and action space provides a strong structural prior for efficiently learning 6-DoF policies. With this formulation, we train a single multi-task Transformer for 18 RLBench tasks (with 249 variations) and 7 real-world tasks (with 18 variations) from just a few demonstrations per task. Our results show that PerAct significantly outperforms unstructured image-to-action agents and 3D ConvNet baselines for a wide range of tabletop tasks.
CLIPort: What and Where Pathways for Robotic Manipulation
Sep 24, 2021

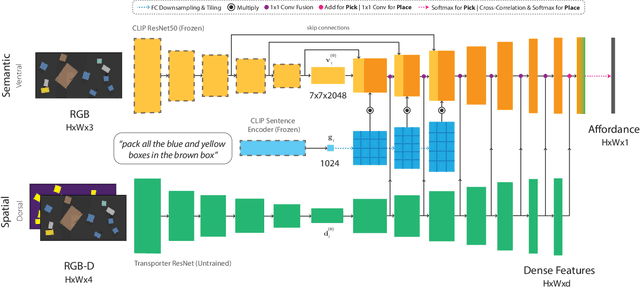

How can we imbue robots with the ability to manipulate objects precisely but also to reason about them in terms of abstract concepts? Recent works in manipulation have shown that end-to-end networks can learn dexterous skills that require precise spatial reasoning, but these methods often fail to generalize to new goals or quickly learn transferable concepts across tasks. In parallel, there has been great progress in learning generalizable semantic representations for vision and language by training on large-scale internet data, however these representations lack the spatial understanding necessary for fine-grained manipulation. To this end, we propose a framework that combines the best of both worlds: a two-stream architecture with semantic and spatial pathways for vision-based manipulation. Specifically, we present CLIPort, a language-conditioned imitation-learning agent that combines the broad semantic understanding (what) of CLIP [1] with the spatial precision (where) of Transporter [2]. Our end-to-end framework is capable of solving a variety of language-specified tabletop tasks from packing unseen objects to folding cloths, all without any explicit representations of object poses, instance segmentations, memory, symbolic states, or syntactic structures. Experiments in simulated and real-world settings show that our approach is data efficient in few-shot settings and generalizes effectively to seen and unseen semantic concepts. We even learn one multi-task policy for 10 simulated and 9 real-world tasks that is better or comparable to single-task policies.
Keypoints into the Future: Self-Supervised Correspondence in Model-Based Reinforcement Learning
Sep 10, 2020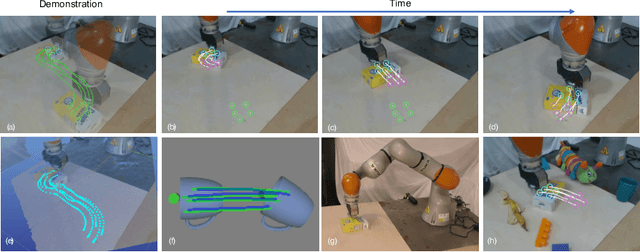
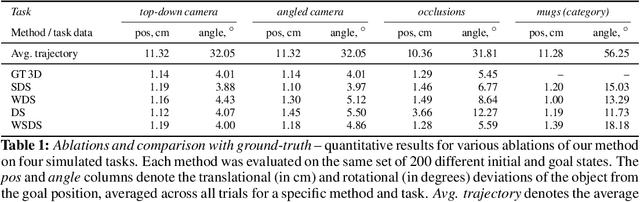


Predictive models have been at the core of many robotic systems, from quadrotors to walking robots. However, it has been challenging to develop and apply such models to practical robotic manipulation due to high-dimensional sensory observations such as images. Previous approaches to learning models in the context of robotic manipulation have either learned whole image dynamics or used autoencoders to learn dynamics in a low-dimensional latent state. In this work, we introduce model-based prediction with self-supervised visual correspondence learning, and show that not only is this indeed possible, but demonstrate that these types of predictive models show compelling performance improvements over alternative methods for vision-based RL with autoencoder-type vision training. Through simulation experiments, we demonstrate that our models provide better generalization precision, particularly in 3D scenes, scenes involving occlusion, and in category-generalization. Additionally, we validate that our method effectively transfers to the real world through hardware experiments. Videos and supplementary materials available at https://sites.google.com/view/keypointsintothefuture
Self-Supervised Correspondence in Visuomotor Policy Learning
Sep 16, 2019
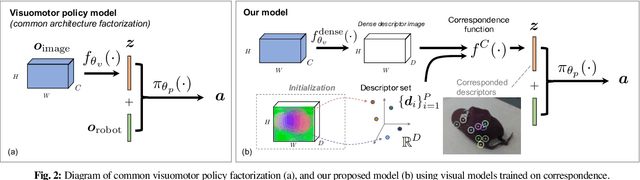
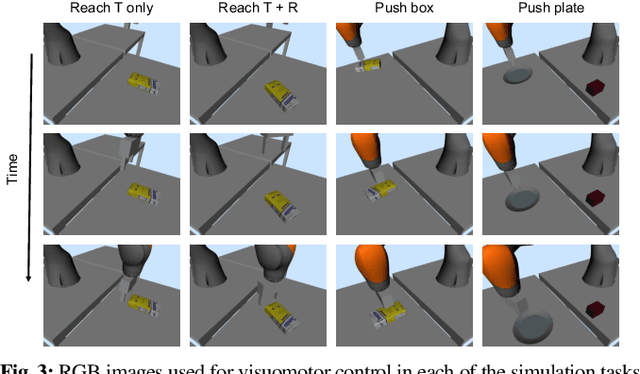
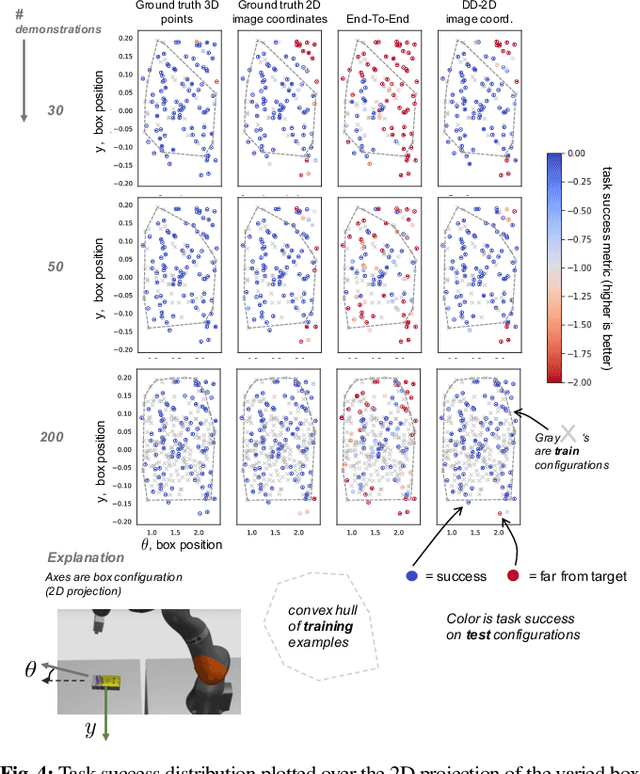
In this paper we explore using self-supervised correspondence for improving the generalization performance and sample efficiency of visuomotor policy learning. Prior work has primarily used approaches such as autoencoding, pose-based losses, and end-to-end policy optimization in order to train the visual portion of visuomotor policies. We instead propose an approach using self-supervised dense visual correspondence training, and show this enables visuomotor policy learning with surprisingly high generalization performance with modest amounts of data: using imitation learning, we demonstrate extensive hardware validation on challenging manipulation tasks with as few as 50 demonstrations. Our learned policies can generalize across classes of objects, react to deformable object configurations, and manipulate textureless symmetrical objects in a variety of backgrounds, all with closed-loop, real-time vision-based policies. Simulated imitation learning experiments suggest that correspondence training offers sample complexity and generalization benefits compared to autoencoding and end-to-end training.
kPAM: KeyPoint Affordances for Category-Level Robotic Manipulation
Mar 15, 2019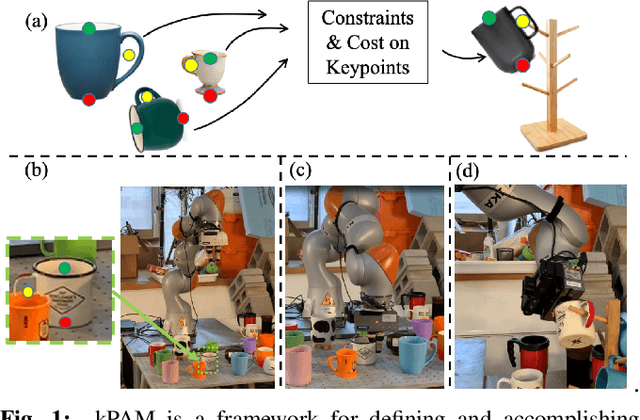



We would like robots to achieve purposeful manipulation by placing any instance from a category of objects into a desired set of goal states. Existing manipulation pipelines typically specify the desired configuration as a target 6-DOF pose and rely on explicitly estimating the pose of the manipulated objects. However, representing an object with a parameterized transformation defined on a fixed template cannot capture large intra-category shape variation, and specifying a target pose at a category level can be physically infeasible or fail to accomplish the task -- e.g. knowing the pose and size of a coffee mug relative to some canonical mug is not sufficient to successfully hang it on a rack by its handle. Hence we propose a novel formulation of category-level manipulation that uses semantic 3D keypoints as the object representation. This keypoint representation enables a simple and interpretable specification of the manipulation target as geometric costs and constraints on the keypoints, which flexibly generalizes existing pose-based manipulation methods. Using this formulation, we factor the manipulation policy into instance segmentation, 3D keypoint detection, optimization-based robot action planning and local dense-geometry-based action execution. This factorization allows us to leverage advances in these sub-problems and combine them into a general and effective perception-to-action manipulation pipeline. Our pipeline is robust to large intra-category shape variation and topology changes as the keypoint representation ignores task-irrelevant geometric details. Extensive hardware experiments demonstrate our method can reliably accomplish tasks with never-before seen objects in a category, such as placing shoes and mugs with significant shape variation into category level target configurations.
Dense Object Nets: Learning Dense Visual Object Descriptors By and For Robotic Manipulation
Sep 07, 2018
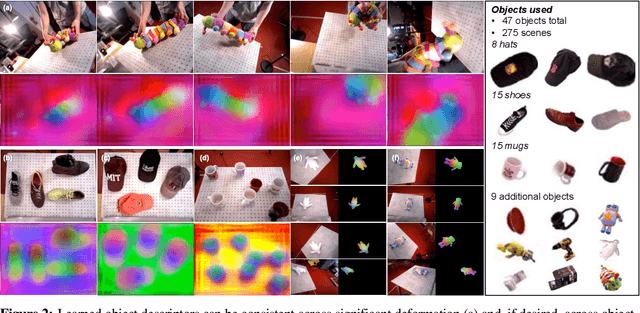
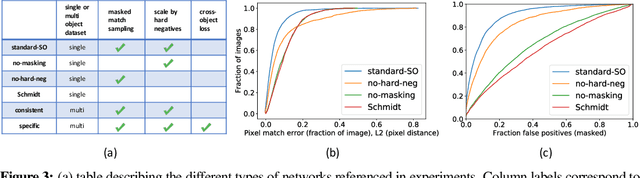
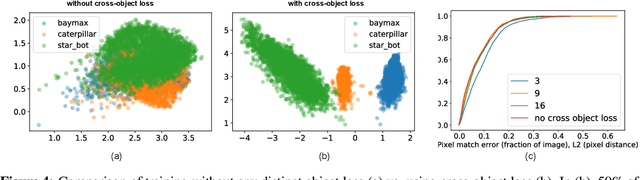
What is the right object representation for manipulation? We would like robots to visually perceive scenes and learn an understanding of the objects in them that (i) is task-agnostic and can be used as a building block for a variety of manipulation tasks, (ii) is generally applicable to both rigid and non-rigid objects, (iii) takes advantage of the strong priors provided by 3D vision, and (iv) is entirely learned from self-supervision. This is hard to achieve with previous methods: much recent work in grasping does not extend to grasping specific objects or other tasks, whereas task-specific learning may require many trials to generalize well across object configurations or other tasks. In this paper we present Dense Object Nets, which build on recent developments in self-supervised dense descriptor learning, as a consistent object representation for visual understanding and manipulation. We demonstrate they can be trained quickly (approximately 20 minutes) for a wide variety of previously unseen and potentially non-rigid objects. We additionally present novel contributions to enable multi-object descriptor learning, and show that by modifying our training procedure, we can either acquire descriptors which generalize across classes of objects, or descriptors that are distinct for each object instance. Finally, we demonstrate the novel application of learned dense descriptors to robotic manipulation. We demonstrate grasping of specific points on an object across potentially deformed object configurations, and demonstrate using class general descriptors to transfer specific grasps across objects in a class.
LabelFusion: A Pipeline for Generating Ground Truth Labels for Real RGBD Data of Cluttered Scenes
Sep 26, 2017

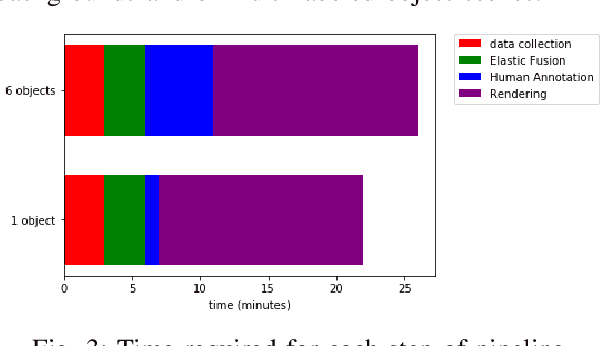

Deep neural network (DNN) architectures have been shown to outperform traditional pipelines for object segmentation and pose estimation using RGBD data, but the performance of these DNN pipelines is directly tied to how representative the training data is of the true data. Hence a key requirement for employing these methods in practice is to have a large set of labeled data for your specific robotic manipulation task, a requirement that is not generally satisfied by existing datasets. In this paper we develop a pipeline to rapidly generate high quality RGBD data with pixelwise labels and object poses. We use an RGBD camera to collect video of a scene from multiple viewpoints and leverage existing reconstruction techniques to produce a 3D dense reconstruction. We label the 3D reconstruction using a human assisted ICP-fitting of object meshes. By reprojecting the results of labeling the 3D scene we can produce labels for each RGBD image of the scene. This pipeline enabled us to collect over 1,000,000 labeled object instances in just a few days. We use this dataset to answer questions related to how much training data is required, and of what quality the data must be, to achieve high performance from a DNN architecture.