 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALOHA Unleashed: A Simple Recipe for Robot Dexterity
Oct 17, 2024Recent work has shown promising results for learning end-to-end robot policies using imitation learning. In this work we address the question of how far can we push imitation learning for challenging dexterous manipulation tasks. We show that a simple recipe of large scale data collection on the ALOHA 2 platform, combined with expressive models such as Diffusion Policies, can be effective in learning challenging bimanual manipulation tasks involving deformable objects and complex contact rich dynamics. We demonstrate our recipe on 5 challenging real-world and 3 simulated tasks and demonstrate improved performance over state-of-the-art baselines. The project website and videos can be found at aloha-unleashed.github.io.
Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs
Jul 10, 2024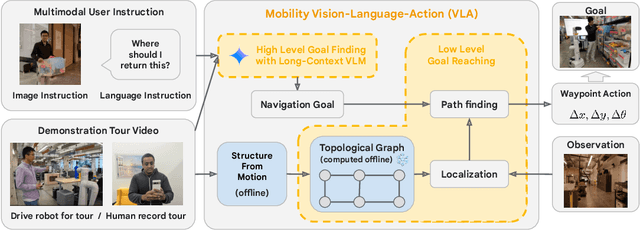
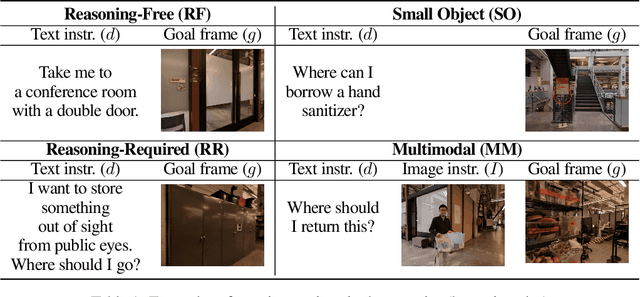


An elusive goal in navigation research is to build an intelligent agent that can understand multimodal instructions including natural language and image, and perform useful navigation. To achieve this, we study a widely useful category of navigation tasks we call Multimodal Instruction Navigation with demonstration Tours (MINT), in which the environment prior is provided through a previously recorded demonstration video. Recent advances in Vision Language Models (VLMs) have shown a promising path in achieving this goal as it demonstrates capabilities in perceiving and reasoning about multimodal inputs. However, VLMs are typically trained to predict textual output and it is an open research question about how to best utilize them in navigation. To solve MINT, we present Mobility VLA, a hierarchical Vision-Language-Action (VLA) navigation policy that combines the environment understanding and common sense reasoning power of long-context VLMs and a robust low-level navigation policy based on topological graphs. The high-level policy consists of a long-context VLM that takes the demonstration tour video and the multimodal user instruction as input to find the goal frame in the tour video. Next, a low-level policy uses the goal frame and an offline constructed topological graph to generate robot actions at every timestep. We evaluated Mobility VLA in a 836m^2 real world environment and show that Mobility VLA has a high end-to-end success rates on previously unsolved multimodal instructions such as "Where should I return this?" while holding a plastic bin.
SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
Jan 22, 2024Understanding and reasoning about spatial relationships is a fundamental capability for Visual Question Answering (VQA) and robotics. While Vision Language Models (VLM) have demonstrated remarkable performance in certain VQA benchmarks, they still lack capabilities in 3D spatial reasoning, such as recognizing quantitative relationships of physical objects like distances or size differences. We hypothesize that VLMs' limited spatial reasoning capability is due to the lack of 3D spatial knowledge in training data and aim to solve this problem by training VLMs with Internet-scale spatial reasoning data. To this end, we present a system to facilitate this approach. We first develop an automatic 3D spatial VQA data generation framework that scales up to 2 billion VQA examples on 10 million real-world images. We then investigate various factors in the training recipe, including data quality, training pipeline, and VLM architecture. Our work features the first internet-scale 3D spatial reasoning dataset in metric space. By training a VLM on such data, we significantly enhance its ability on both qualitative and quantitative spatial VQA. Finally, we demonstrate that this VLM unlocks novel downstream applications in chain-of-thought spatial reasoning and robotics due to its quantitative estimation capability. Project website: https://spatial-vlm.github.io/
RoboVQA: Multimodal Long-Horizon Reasoning for Robotics
Nov 01, 2023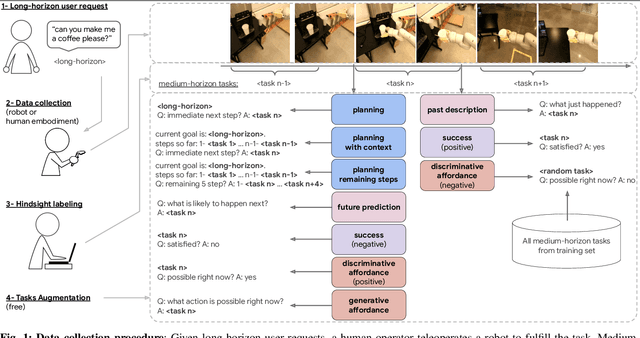

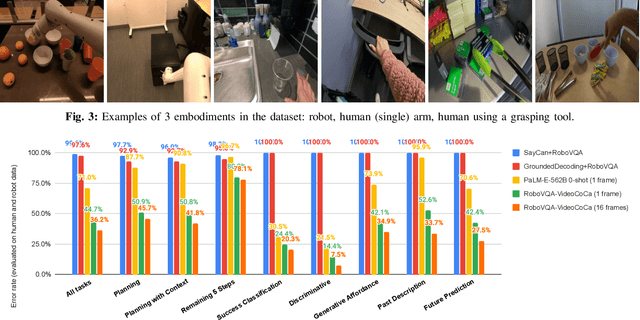
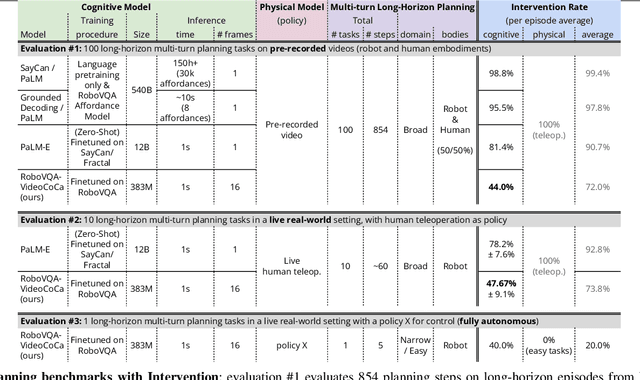
We present a scalable, bottom-up and intrinsically diverse data collection scheme that can be used for high-level reasoning with long and medium horizons and that has 2.2x higher throughput compared to traditional narrow top-down step-by-step collection. We collect realistic data by performing any user requests within the entirety of 3 office buildings and using multiple robot and human embodiments. With this data, we show that models trained on all embodiments perform better than ones trained on the robot data only, even when evaluated solely on robot episodes. We find that for a fixed collection budget it is beneficial to take advantage of cheaper human collection along with robot collection. We release a large and highly diverse (29,520 unique instructions) dataset dubbed RoboVQA containing 829,502 (video, text) pairs for robotics-focused visual question answering. We also demonstrate how evaluating real robot experiments with an intervention mechanism enables performing tasks to completion, making it deployable with human oversight even if imperfect while also providing a single performance metric. We demonstrate a single video-conditioned model named RoboVQA-VideoCoCa trained on our dataset that is capable of performing a variety of grounded high-level reasoning tasks in broad realistic settings with a cognitive intervention rate 46% lower than the zero-shot state of the art visual language model (VLM) baseline and is able to guide real robots through long-horizon tasks. The performance gap with zero-shot state-of-the-art models indicates that a lot of grounded data remains to be collected for real-world deployment, emphasizing the critical need for scalable data collection approaches. Finally, we show that video VLMs significantly outperform single-image VLMs with an average error rate reduction of 19% across all VQA tasks. Data and videos available at https://robovqa.github.io
Video Language Planning
Oct 16, 2023We are interested in enabling visual planning for complex long-horizon tasks in the space of generated videos and language, leveraging recent advances in large generative models pretrained on Internet-scale data. To this end, we present video language planning (VLP), an algorithm that consists of a tree search procedure, where we train (i) vision-language models to serve as both policies and value functions, and (ii) text-to-video models as dynamics models. VLP takes as input a long-horizon task instruction and current image observation, and outputs a long video plan that provides detailed multimodal (video and language) specifications that describe how to complete the final task. VLP scales with increasing computation budget where more computation time results in improved video plans, and is able to synthesize long-horizon video plans across different robotics domains: from multi-object rearrangement, to multi-camera bi-arm dexterous manipulation. Generated video plans can be translated into real robot actions via goal-conditioned policies, conditioned on each intermediate frame of the generated video. Experiments show that VLP substantially improves long-horizon task success rates compared to prior methods on both simulated and real robots (across 3 hardware platforms).
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Jul 28, 2023We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. Our goal is to enable a single end-to-end trained model to both learn to map robot observations to actions and enjoy the benefits of large-scale pretraining on language and vision-language data from the web. To this end, we propose to co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering. In contrast to other approaches, we propose a simple, general recipe to achieve this goal: in order to fit both natural language responses and robotic actions into the same format, we express the actions as text tokens and incorporate them directly into the training set of the model in the same way as natural language tokens. We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).
Towards Generalist Biomedical AI
Jul 26, 2023



Medicine is inherently multimodal, with rich data modalities spanning text, imaging, genomics, and more. Generalist biomedical artificial intelligence (AI) systems that flexibly encode, integrate, and interpret this data at scale can potentially enable impactful applications ranging from scientific discovery to care delivery. To enable the development of these models, we first curate MultiMedBench, a new multimodal biomedical benchmark. MultiMedBench encompasses 14 diverse tasks such as medical question answering, mammography and dermatology image interpretation, radiology report generation and summarization, and genomic variant calling. We then introduce Med-PaLM Multimodal (Med-PaLM M), our proof of concept for a generalist biomedical AI system. Med-PaLM M is a large multimodal generative model that flexibly encodes and interprets biomedical data including clinical language, imaging, and genomics with the same set of model weights. Med-PaLM M reaches performance competitive with or exceeding the state of the art on all MultiMedBench tasks, often surpassing specialist models by a wide margin. We also report examples of zero-shot generalization to novel medical concepts and tasks, positive transfer learning across tasks, and emergent zero-shot medical reasoning. To further probe the capabilities and limitations of Med-PaLM M, we conduct a radiologist evaluation of model-generated (and human) chest X-ray reports and observe encouraging performance across model scales. In a side-by-side ranking on 246 retrospective chest X-rays, clinicians express a pairwise preference for Med-PaLM M reports over those produced by radiologists in up to 40.50% of cases, suggesting potential clinical utility. While considerable work is needed to validate these models in real-world use cases, our results represent a milestone towards the development of generalist biomedical AI systems.
Scaling Up and Distilling Down: Language-Guided Robot Skill Acquisition
Jul 26, 2023We present a framework for robot skill acquisition, which 1) efficiently scale up data generation of language-labelled robot data and 2) effectively distills this data down into a robust multi-task language-conditioned visuo-motor policy. For (1), we use a large language model (LLM) to guide high-level planning, and sampling-based robot planners (e.g. motion or grasp samplers) for generating diverse and rich manipulation trajectories. To robustify this data-collection process, the LLM also infers a code-snippet for the success condition of each task, simultaneously enabling the data-collection process to detect failure and retry as well as the automatic labeling of trajectories with success/failure. For (2), we extend the diffusion policy single-task behavior-cloning approach to multi-task settings with language conditioning. Finally, we propose a new multi-task benchmark with 18 tasks across five domains to test long-horizon behavior, common-sense reasoning, tool-use, and intuitive physics. We find that our distilled policy successfully learned the robust retrying behavior in its data collection policy, while improving absolute success rates by 34.8% on average across five domains. The benchmark, code, and qualitative results are on our website https://www.cs.columbia.edu/~huy/scalingup/
Large Language Models as General Pattern Machines
Jul 10, 2023



We observe that pre-trained large language models (LLMs) are capable of autoregressively completing complex token sequences -- from arbitrary ones procedurally generated by probabilistic context-free grammars (PCFG), to more rich spatial patterns found in the Abstract Reasoning Corpus (ARC), a general AI benchmark, prompted in the style of ASCII art. Surprisingly, pattern completion proficiency can be partially retained even when the sequences are expressed using tokens randomly sampled from the vocabulary. These results suggest that without any additional training, LLMs can serve as general sequence modelers, driven by in-context learning. In this work, we investigate how these zero-shot capabilities may be applied to problems in robotics -- from extrapolating sequences of numbers that represent states over time to complete simple motions, to least-to-most prompting of reward-conditioned trajectories that can discover and represent closed-loop policies (e.g., a stabilizing controller for CartPole). While difficult to deploy today for real systems due to latency, context size limitations, and compute costs, the approach of using LLMs to drive low-level control may provide an exciting glimpse into how the patterns among words could be transferred to actions.
RoboPianist: A Benchmark for High-Dimensional Robot Control
Apr 09, 2023



We introduce a new benchmarking suite for high-dimensional control, targeted at testing high spatial and temporal precision, coordination, and planning, all with an underactuated system frequently making-and-breaking contacts. The proposed challenge is mastering the piano through bi-manual dexterity, using a pair of simulated anthropomorphic robot hands. We call it RoboPianist, and the initial version covers a broad set of 150 variable-difficulty songs. We investigate both model-free and model-based methods on the benchmark, characterizing their performance envelopes. We observe that while certain existing methods, when well-tuned, can achieve impressive levels of performance in certain aspects, there is significant room for improvement. RoboPianist provides a rich quantitative benchmarking environment, with human-interpretable results, high ease of expansion by simply augmenting the repertoire with new songs, and opportunities for further research, including in multi-task learning, zero-shot generalization, multimodal (sound, vision, touch) learning, and imitation. Supplementary information, including videos of our control policies, can be found at https://kzakka.com/robopianist/