 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-to-Sim Robot Policy Evaluation with Gaussian Splatting Simulation of Soft-Body Interactions
Nov 06, 2025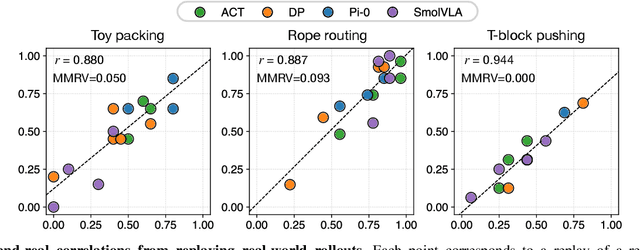

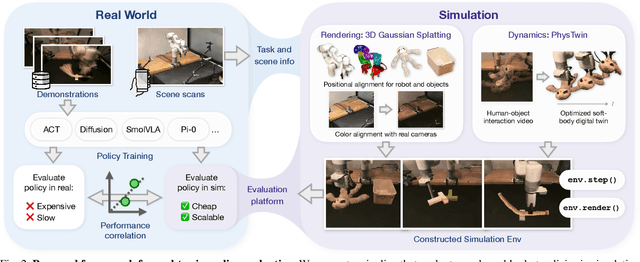
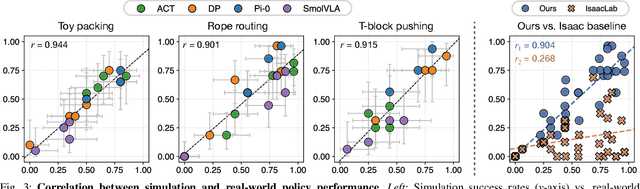
Robotic manipulation policies are advancing rapidly, but their direct evaluation in the real world remains costly, time-consuming, and difficult to reproduce, particularly for tasks involving deformable objects. Simulation provides a scalable and systematic alternative, yet existing simulators often fail to capture the coupled visual and physical complexity of soft-body interactions. We present a real-to-sim policy evaluation framework that constructs soft-body digital twins from real-world videos and renders robots, objects, and environments with photorealistic fidelity using 3D Gaussian Splatting. We validate our approach on representative deformable manipulation tasks, including plush toy packing, rope routing, and T-block pushing, demonstrating that simulated rollouts correlate strongly with real-world execution performance and reveal key behavioral patterns of learned policies. Our results suggest that combining physics-informed reconstruction with high-quality rendering enables reproducible, scalable, and accurate evaluation of robotic manipulation policies. Website: https://real2sim-eval.github.io/
OpenHAIV: A Framework Towards Practical Open-World Learning
Aug 10, 2025Substantial progress has been made in various techniques for open-world recognition. Out-of-distribution (OOD) detection methods can effectively distinguish between known and unknown classes in the data, while incremental learning enables continuous model knowledge updates. However, in open-world scenarios, these approaches still face limitations. Relying solely on OOD detection does not facilitate knowledge updates in the model, and incremental fine-tuning typically requires supervised conditions, which significantly deviate from open-world settings. To address these challenges, this paper proposes OpenHAIV, a novel framework that integrates OOD detection, new class discovery, and incremental continual fine-tuning into a unified pipeline. This framework allows models to autonomously acquire and update knowledge in open-world environments. The proposed framework is available at https://haiv-lab.github.io/openhaiv .
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
EDENet: Echo Direction Encoding Network for Place Recognition Based on Ground Penetrating Radar
Feb 28, 2025



Ground penetrating radar (GPR) based localization has gained significant recognition in robotics due to its ability to detect stable subsurface features, offering advantages in environments where traditional sensors like cameras and LiDAR may struggle. However, existing methods are primarily focused on small-scale place recognition (PR), leaving the challenges of PR in large-scale maps unaddressed. These challenges include the inherent sparsity of underground features and the variability in underground dielectric constants, which complicate robust localization. In this work, we investigate the geometric relationship between GPR echo sequences and underground scenes, leveraging the robustness of directional features to inform our network design. We introduce learnable Gabor filters for the precise extraction of directional responses, coupled with a direction-aware attention mechanism for effective geometric encoding. To further enhance performance, we incorporate a shift-invariant unit and a multi-scale aggregation strategy to better accommodate variations in di-electric constants. Experiments conducted on public datasets demonstrate that our proposed EDENet not only surpasses existing solutions in terms of PR performance but also offers advantages in model size and computational efficiency.
OpenEarthSensing: Large-Scale Fine-Grained Benchmark for Open-World Remote Sensing
Feb 28, 2025
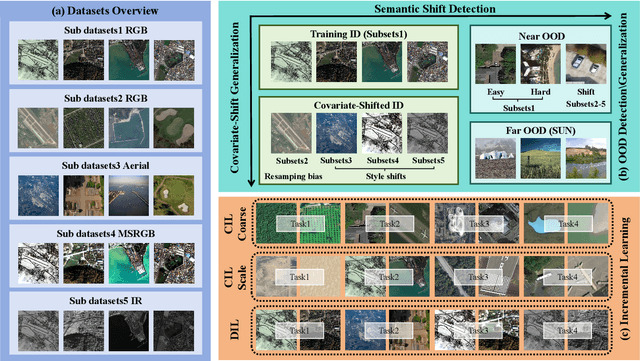

In open-world remote sensing, deployed models must continuously adapt to a steady influx of new data, which often exhibits various shifts compared to what the model encountered during the training phase. To effectively handle the new data, models are required to detect semantic shifts, adapt to covariate shifts, and continuously update themselves. These challenges give rise to a variety of open-world tasks. However, existing open-world remote sensing studies typically train and test within a single dataset to simulate open-world conditions. Currently, there is a lack of large-scale benchmarks capable of evaluating multiple open-world tasks. In this paper, we introduce OpenEarthSensing, a large-scale fine-grained benchmark for open-world remote sensing. OpenEarthSensing includes 189 scene and objects categories, covering the vast majority of potential semantic shifts that may occur in the real world. Additionally, OpenEarthSensing encompasses five data domains with significant covariate shifts, including two RGB satellite domians, one RGB aerial domian, one MS RGB domian, and one infrared domian. The various domains provide a more comprehensive testbed for evaluating the generalization performance of open-world models. We conduct the baseline evaluation of current mainstream open-world tasks and methods on OpenEarthSensing, demonstrating that it serves as a challenging benchmark for open-world remote sensing.
PO-GVINS: Tightly Coupled GNSS-Visual-Inertial Integration with Pose-Only Representation
Jan 16, 2025Accurate and reliable positioning is crucial for perception, decision-making, and other high-level applications in autonomous driving, unmanned aerial vehicles, and intelligent robots. Given the inherent limitations of standalone sensors, integrating heterogeneous sensors with complementary capabilities is one of the most effective approaches to achieving this goal. In this paper, we propose a filtering-based, tightly coupled global navigation satellite system (GNSS)-visual-inertial positioning framework with a pose-only formulation applied to the visual-inertial system (VINS), termed PO-GVINS. Specifically, multiple-view imaging used in current VINS requires a priori of 3D feature, then jointly estimate camera poses and 3D feature position, which inevitably introduces linearization error of the feature as well as facing dimensional explosion. However, the pose-only (PO) formulation, which is demonstrated to be equivalent to the multiple-view imaging and has been applied in visual reconstruction, represent feature depth using two camera poses and thus 3D feature position is removed from state vector avoiding aforementioned difficulties. Inspired by this, we first apply PO formulation in our VINS, i.e., PO-VINS. GNSS raw measurements are then incorporated with integer ambiguity resolved to achieve accurate and drift-free estimation. Extensive experiments demonstrate that the proposed PO-VINS significantly outperforms the multi-state constrained Kalman filter (MSCKF). By incorporating GNSS measurements, PO-GVINS achieves accurate, drift-free state estimation, making it a robust solution for positioning in challenging environments.
Vision Language Models are In-Context Value Learners
Nov 07, 2024
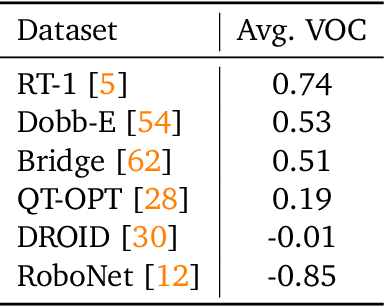
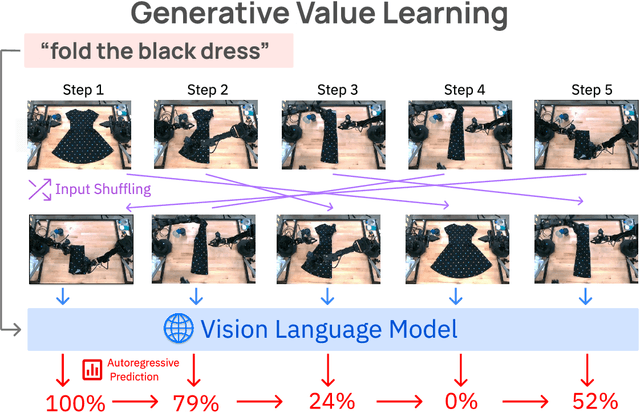
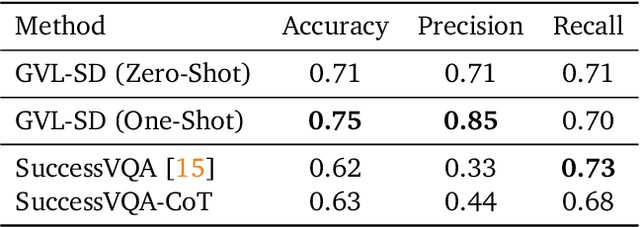
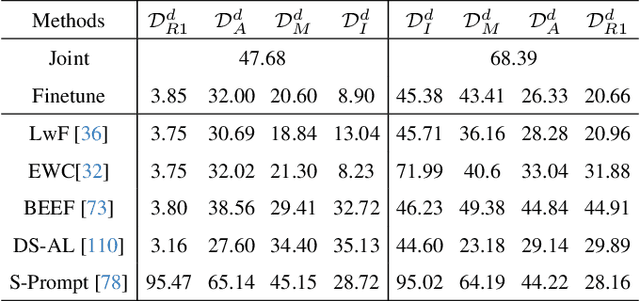
Predicting temporal progress from visual trajectories is important for intelligent robots that can learn, adapt, and improve. However, learning such progress estimator, or temporal value function, across different tasks and domains requires both a large amount of diverse data and methods which can scale and generalize. To address these challenges, we present Generative Value Learning (\GVL), a universal value function estimator that leverages the world knowledge embedded in vision-language models (VLMs) to predict task progress. Naively asking a VLM to predict values for a video sequence performs poorly due to the strong temporal correlation between successive frames. Instead, GVL poses value estimation as a temporal ordering problem over shuffled video frames; this seemingly more challenging task encourages VLMs to more fully exploit their underlying semantic and temporal grounding capabilities to differentiate frames based on their perceived task progress, consequently producing significantly better value predictions. Without any robot or task specific training, GVL can in-context zero-shot and few-shot predict effective values for more than 300 distinct real-world tasks across diverse robot platforms, including challenging bimanual manipulation tasks. Furthermore, we demonstrate that GVL permits flexible multi-modal in-context learning via examples from heterogeneous tasks and embodiments, such as human videos. The generality of GVL enables various downstream applications pertinent to visuomotor policy learning, including dataset filtering, success detection, and advantage-weighted regression -- all without any model training or finetuning.
Imagined Potential Games: A Framework for Simulating, Learning and Evaluating Interactive Behaviors
Nov 06, 2024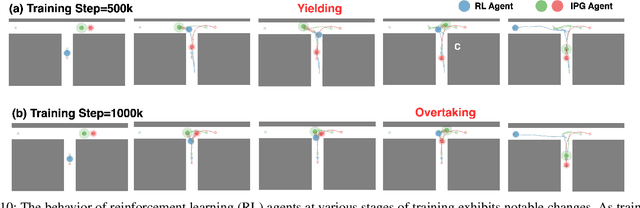


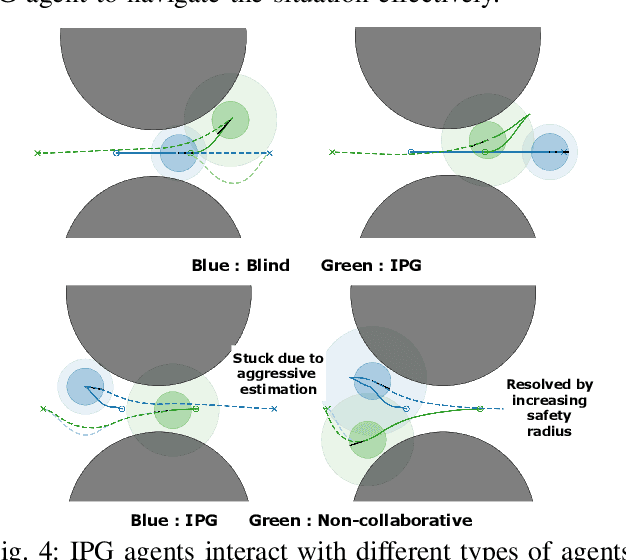
Interacting with human agents in complex scenarios presents a significant challenge for robotic navigation, particularly in environments that necessitate both collision avoidance and collaborative interaction, such as indoor spaces. Unlike static or predictably moving obstacles, human behavior is inherently complex and unpredictable, stemming from dynamic interactions with other agents. Existing simulation tools frequently fail to adequately model such reactive and collaborative behaviors, impeding the development and evaluation of robust social navigation strategies. This paper introduces a novel framework utilizing distributed potential games to simulate human-like interactions in highly interactive scenarios. Within this framework, each agent imagines a virtual cooperative game with others based on its estimation. We demonstrate this formulation can facilitate the generation of diverse and realistic interaction patterns in a configurable manner across various scenarios. Additionally, we have developed a gym-like environment leveraging our interactive agent model to facilitate the learning and evaluation of interactive navigation algorithms.
Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs
Jul 10, 2024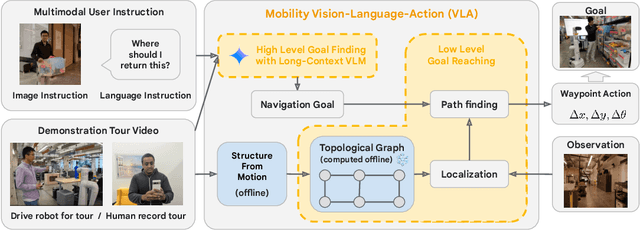
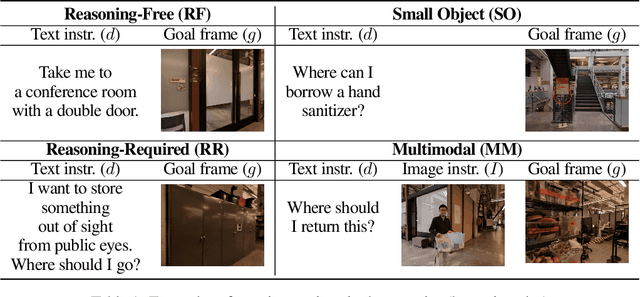


An elusive goal in navigation research is to build an intelligent agent that can understand multimodal instructions including natural language and image, and perform useful navigation. To achieve this, we study a widely useful category of navigation tasks we call Multimodal Instruction Navigation with demonstration Tours (MINT), in which the environment prior is provided through a previously recorded demonstration video. Recent advances in Vision Language Models (VLMs) have shown a promising path in achieving this goal as it demonstrates capabilities in perceiving and reasoning about multimodal inputs. However, VLMs are typically trained to predict textual output and it is an open research question about how to best utilize them in navigation. To solve MINT, we present Mobility VLA, a hierarchical Vision-Language-Action (VLA) navigation policy that combines the environment understanding and common sense reasoning power of long-context VLMs and a robust low-level navigation policy based on topological graphs. The high-level policy consists of a long-context VLM that takes the demonstration tour video and the multimodal user instruction as input to find the goal frame in the tour video. Next, a low-level policy uses the goal frame and an offline constructed topological graph to generate robot actions at every timestep. We evaluated Mobility VLA in a 836m^2 real world environment and show that Mobility VLA has a high end-to-end success rates on previously unsolved multimodal instructions such as "Where should I return this?" while holding a plastic bin.
Ghost imaging-based Non-contact Heart Rate Detection
Jun 04, 2024



Remote heart rate measurement is an increasingly concerned research field, usually using remote photoplethysmography (rPPG) to collect heart rate information through video data collection. However, in certain specific scenarios (such as low light conditions, intense lighting, and non-line-of-sight situations), traditional imaging methods fail to capture image information effectively, that may lead to difficulty or inability in measuring heart rate. To address these limitations, this study proposes using ghost imaging as a substitute for traditional imaging in the aforementioned scenarios. The mean absolute error between experimental measurements and reference true values is 4.24 bpm.Additionally, the bucket signals obtained by the ghost imaging system can be directly processed using digital signal processing techniques, thereby enhancing personal privacy protection.