 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
EDENet: Echo Direction Encoding Network for Place Recognition Based on Ground Penetrating Radar
Feb 28, 2025



Ground penetrating radar (GPR) based localization has gained significant recognition in robotics due to its ability to detect stable subsurface features, offering advantages in environments where traditional sensors like cameras and LiDAR may struggle. However, existing methods are primarily focused on small-scale place recognition (PR), leaving the challenges of PR in large-scale maps unaddressed. These challenges include the inherent sparsity of underground features and the variability in underground dielectric constants, which complicate robust localization. In this work, we investigate the geometric relationship between GPR echo sequences and underground scenes, leveraging the robustness of directional features to inform our network design. We introduce learnable Gabor filters for the precise extraction of directional responses, coupled with a direction-aware attention mechanism for effective geometric encoding. To further enhance performance, we incorporate a shift-invariant unit and a multi-scale aggregation strategy to better accommodate variations in di-electric constants. Experiments conducted on public datasets demonstrate that our proposed EDENet not only surpasses existing solutions in terms of PR performance but also offers advantages in model size and computational efficiency.
High-precision visual navigation device calibration method based on collimator
Feb 25, 2025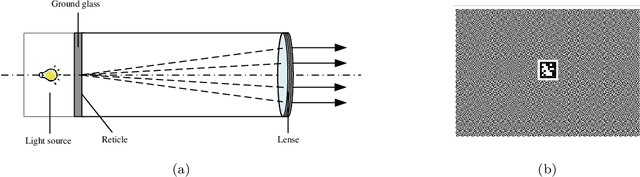
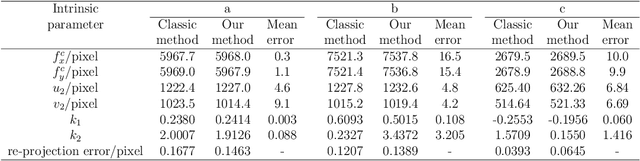
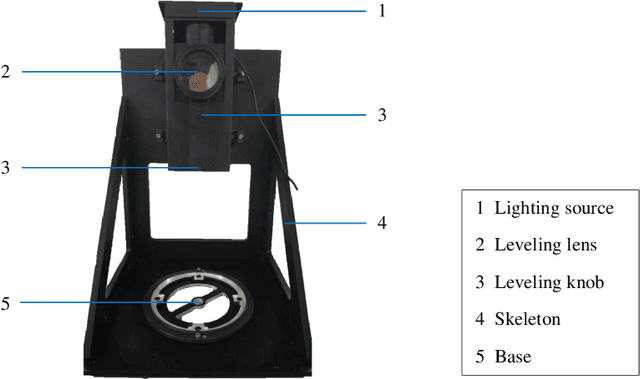

Visual navigation devices require precise calibration to achieve high-precision localization and navigation, which includes camera and attitude calibration. To address the limitations of time-consuming camera calibration and complex attitude adjustment processes, this study presents a collimator-based calibration method and system. Based on the optical characteristics of the collimator, a single-image camera calibration algorithm is introduced. In addition, integrated with the precision adjustment mechanism of the calibration frame, a rotation transfer model between coordinate systems enables efficient attitude calibration. Experimental results demonstrate that the proposed method achieves accuracy and stability comparable to traditional multi-image calibration techniques. Specifically, the re-projection errors are less than 0.1463 pixels, and average attitude angle errors are less than 0.0586 degrees with a standard deviation less than 0.0257 degrees, demonstrating high precision and robustness.
Reinforced Decoder: Towards Training Recurrent Neural Networks for Time Series Forecasting
Jun 14, 2024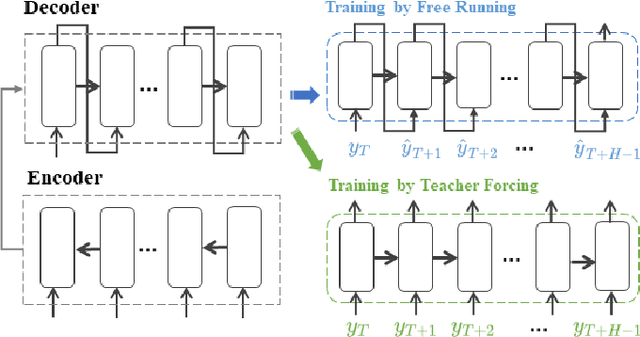
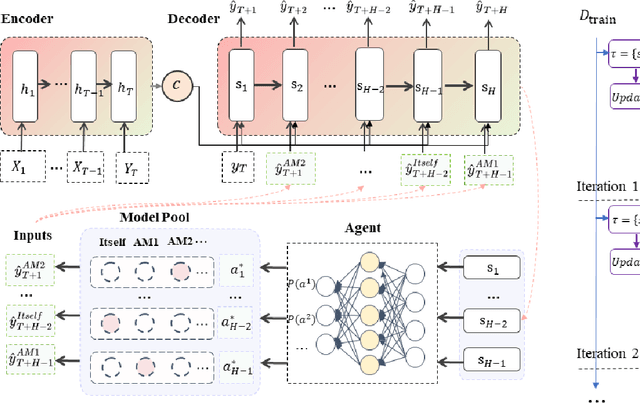
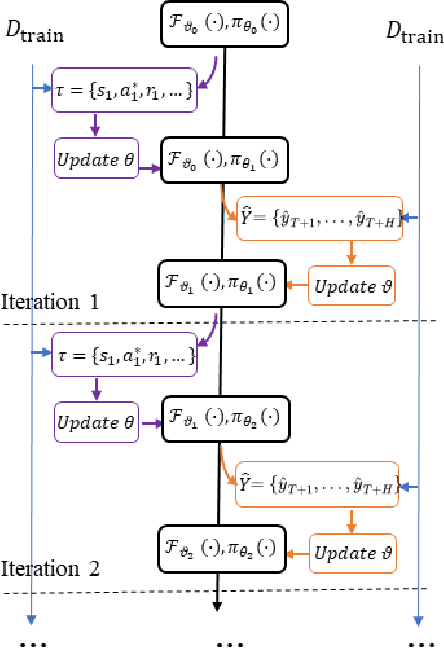
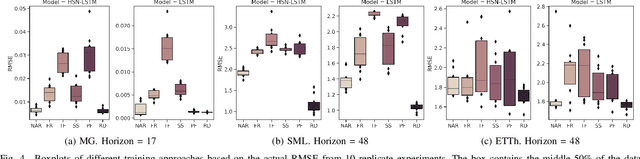
Recurrent neural network-based sequence-to-sequence models have been extensively applied for multi-step-ahead time series forecasting. These models typically involve a decoder trained using either its previous forecasts or the actual observed values as the decoder inputs. However, relying on self-generated predictions can lead to the rapid accumulation of errors over multiple steps, while using the actual observations introduces exposure bias as these values are unavailable during the extrapolation stage. In this regard, this study proposes a novel training approach called reinforced decoder, which introduces auxiliary models to generate alternative decoder inputs that remain accessible when extrapolating. Additionally, a reinforcement learning algorithm is utilized to dynamically select the optimal inputs to improve accuracy. Comprehensive experiments demonstrate that our approach outperforms representative training methods over several datasets. Furthermore, the proposed approach also exhibits promising performance when generalized to self-attention-based sequence-to-sequence forecasting models.
SE-MoE: A Scalable and Efficient Mixture-of-Experts Distributed Training and Inference System
May 20, 2022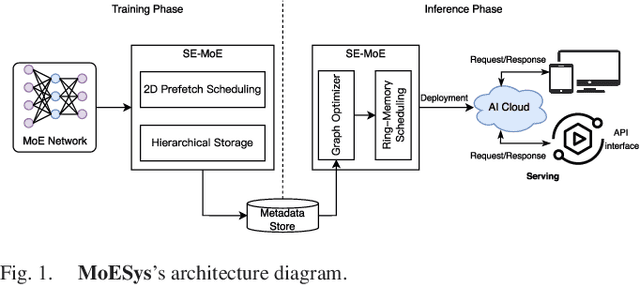
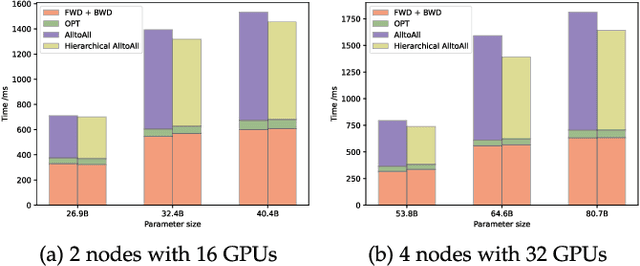
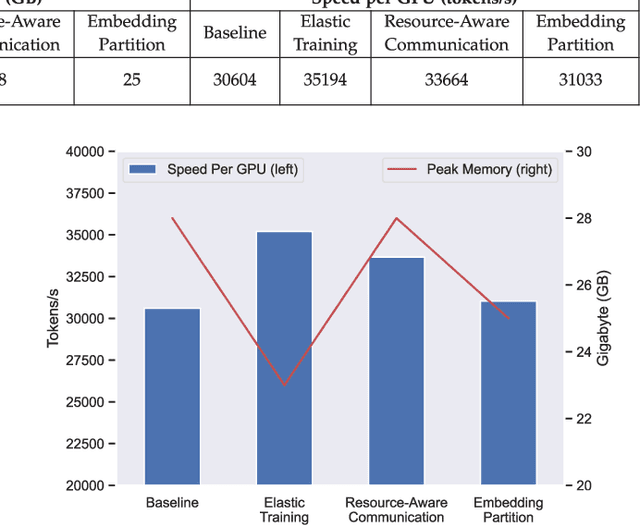
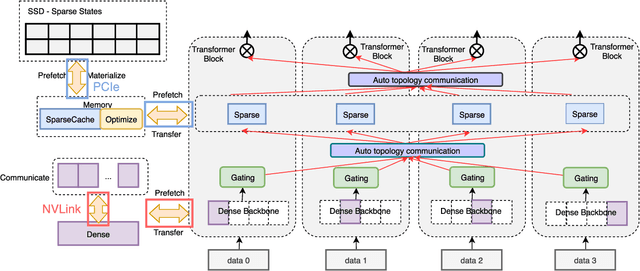
With the increasing diversity of ML infrastructures nowadays, distributed training over heterogeneous computing systems is desired to facilitate the production of big models. Mixture-of-Experts (MoE) models have been proposed to lower the cost of training subject to the overall size of models/data through gating and parallelism in a divide-and-conquer fashion. While DeepSpeed has made efforts in carrying out large-scale MoE training over heterogeneous infrastructures, the efficiency of training and inference could be further improved from several system aspects, including load balancing, communication/computation efficiency, and memory footprint limits. In this work, we present SE-MoE that proposes Elastic MoE training with 2D prefetch and Fusion communication over Hierarchical storage, so as to enjoy efficient parallelisms in various types. For scalable inference in a single node, especially when the model size is larger than GPU memory, SE-MoE forms the CPU-GPU memory jointly into a ring of sections to load the model, and executes the computation tasks across the memory sections in a round-robin manner for efficient inference. We carried out extensive experiments to evaluate SE-MoE, where SE-MoE successfully trains a Unified Feature Optimization (UFO) model with a Sparsely-Gated Mixture-of-Experts model of 12B parameters in 8 days on 48 A100 GPU cards. The comparison against the state-of-the-art shows that SE-MoE outperformed DeepSpeed with 33% higher throughput (tokens per second) in training and 13% higher throughput in inference in general. Particularly, under unbalanced MoE Tasks, e.g., UFO, SE-MoE achieved 64% higher throughput with 18% lower memory footprints. The code of the framework will be released on: https://github.com/PaddlePaddle/Paddle.
An Empirical Study of Low Precision Quantization for TinyML
Mar 10, 2022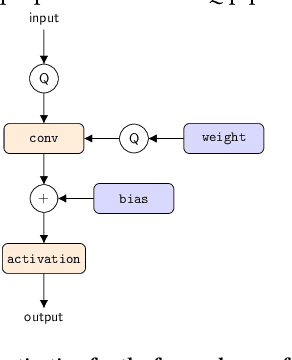

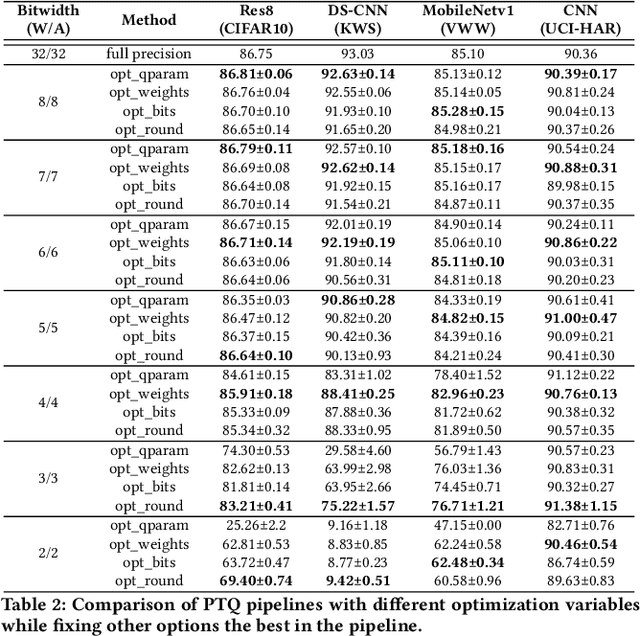
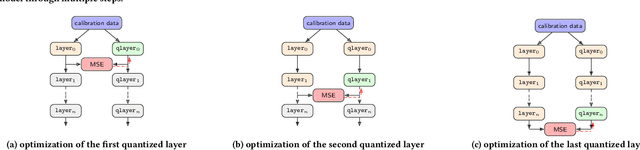
Tiny machine learning (tinyML) has emerged during the past few years aiming to deploy machine learning models to embedded AI processors with highly constrained memory and computation capacity. Low precision quantization is an important model compression technique that can greatly reduce both memory consumption and computation cost of model inference. In this study, we focus on post-training quantization (PTQ) algorithms that quantize a model to low-bit (less than 8-bit) precision with only a small set of calibration data and benchmark them on different tinyML use cases. To achieve a fair comparison, we build a simulated quantization framework to investigate recent PTQ algorithms. Furthermore, we break down those algorithms into essential components and re-assembled a generic PTQ pipeline. With ablation study on different alternatives of components in the pipeline, we reveal key design choices when performing low precision quantization. We hope this work could provide useful data points and shed lights on the future research of low precision quantization.
End-to-end Adaptive Distributed Training on PaddlePaddle
Dec 06, 2021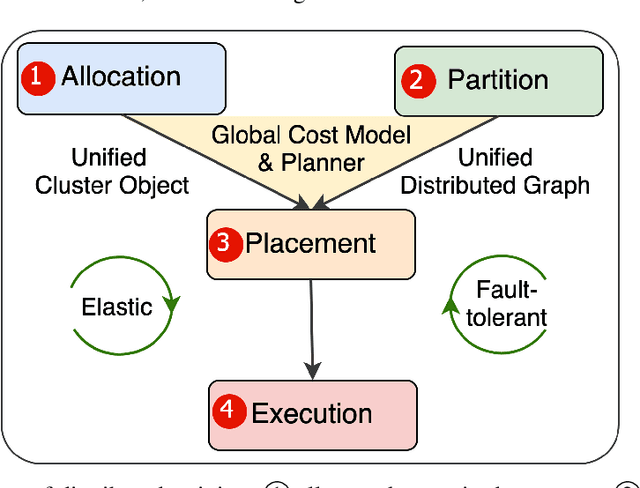
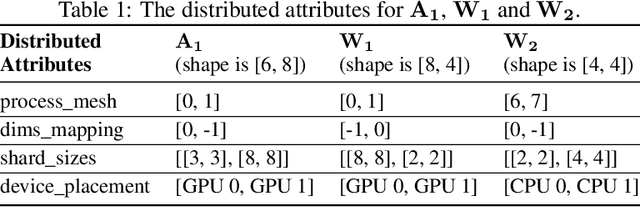
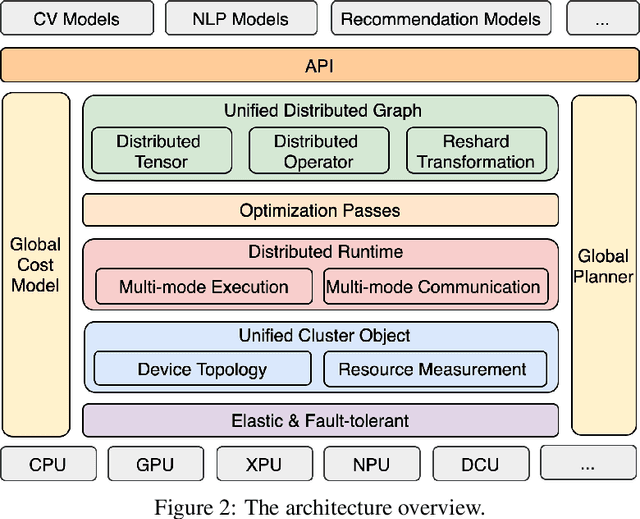
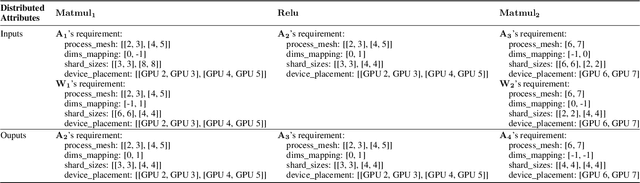
Distributed training has become a pervasive and effective approach for training a large neural network (NN) model with processing massive data. However, it is very challenging to satisfy requirements from various NN models, diverse computing resources, and their dynamic changes during a training job. In this study, we design our distributed training framework in a systematic end-to-end view to provide the built-in adaptive ability for different scenarios, especially for industrial applications and production environments, by fully considering resource allocation, model partition, task placement, and distributed execution. Based on the unified distributed graph and the unified cluster object, our adaptive framework is equipped with a global cost model and a global planner, which can enable arbitrary parallelism, resource-aware placement, multi-mode execution, fault-tolerant, and elastic distributed training. The experiments demonstrate that our framework can satisfy various requirements from the diversity of applications and the heterogeneity of resources with highly competitive performance. The ERNIE language model with 260 billion parameters is efficiently trained on thousands of AI processors with 91.7% weak scalability. The throughput of the model from the recommender system by employing the heterogeneous pipeline asynchronous execution can be increased up to 2.1 times and 3.3 times that of the GPU-only and CPU-only training respectively. Moreover, the fault-tolerant and elastic distributed training have been successfully applied to the online industrial applications, which give a reduction of 34.49% in the number of failed long-term training jobs and an increase of 33.91% for the global scheduling efficiency in the production environment.
Multilevel Image Thresholding Using a Fully Informed Cuckoo Search Algorithm
May 31, 2020
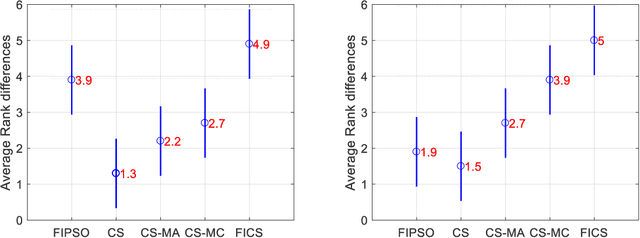
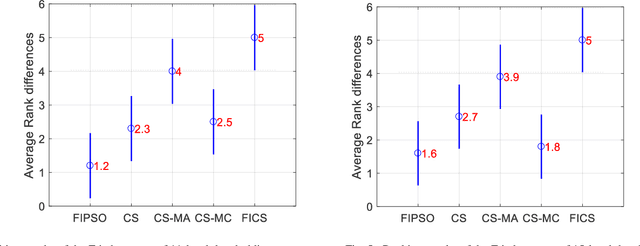
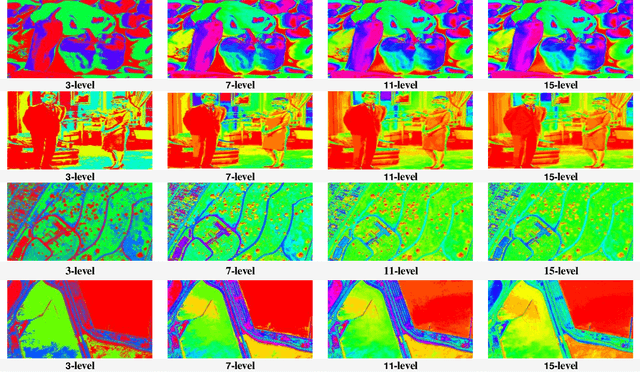
Though effective in the segmentation, conventional multilevel thresholding methods are computationally expensive as exhaustive search are used for optimal thresholds to optimize the objective functions. To overcome this problem, population-based metaheuristic algorithms are widely used to improve the searching capacity. In this paper, we improve a popular metaheuristic called cuckoo search using a ring topology based fully informed strategy. In this strategy, each individual in the population learns from its neighborhoods to improve the cooperation of the population and the learning efficiency. Best solution or best fitness value can be obtained from the initial random threshold values, whose quality is evaluated by the correlation function. Experimental results have been examined on various numbers of thresholds. The results demonstrate that the proposed algorithm is more accurate and efficient than other four popular methods.
Novel Co-variant Feature Point Matching Based on Gaussian Mixture Model
Oct 26, 2019
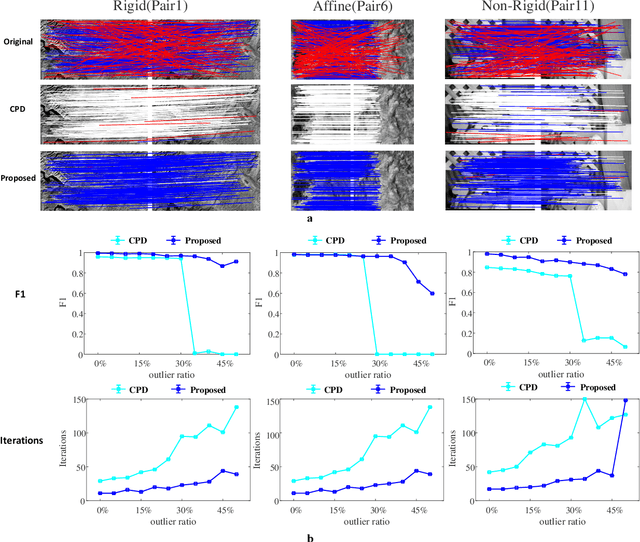
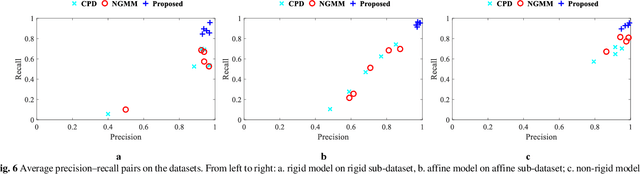
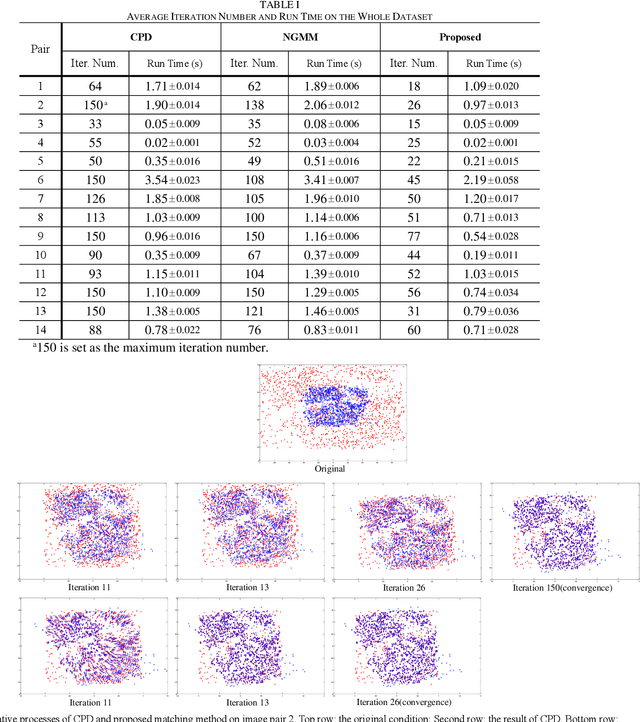
The feature frame is a key idea of feature matching problem between two images. However, most of the traditional matching methods only simply employ the spatial location information (the coordinates), which ignores the shape and orientation information of the local feature. Such additional information can be obtained along with coordinates using general co-variant detectors such as DOG, Hessian, Harris-Affine and MSER. In this paper, we develop a novel method considering all the feature center position coordinates, the local feature shape and orientation information based on Gaussian Mixture Model for co-variant feature matching. We proposed three sub-versions in our method for solving the matching problem in different conditions: rigid, affine and non-rigid, respectively, which all optimized by expectation maximization algorithm. Due to the effective utilization of the additional shape and orientation information, the proposed model can significantly improve the performance in terms of convergence speed and recall. Besides, it is more robust to the outliers.
Low-Power Computer Vision: Status, Challenges, Opportunities
Apr 15, 2019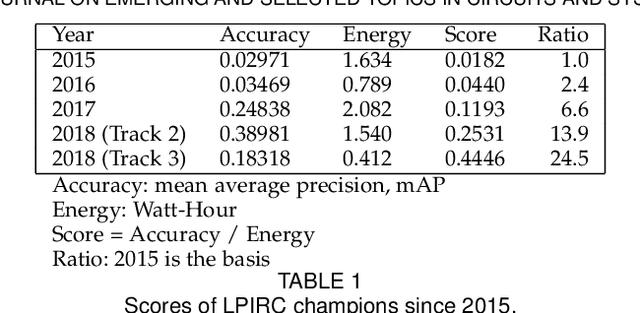
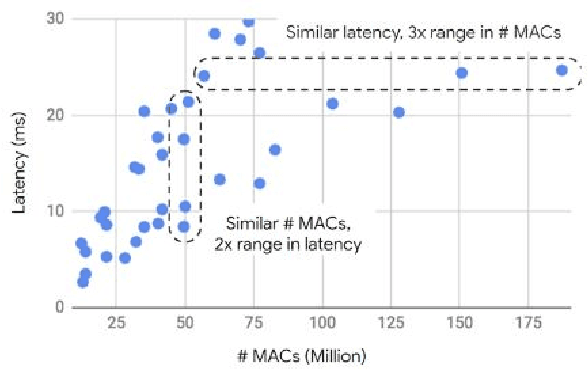
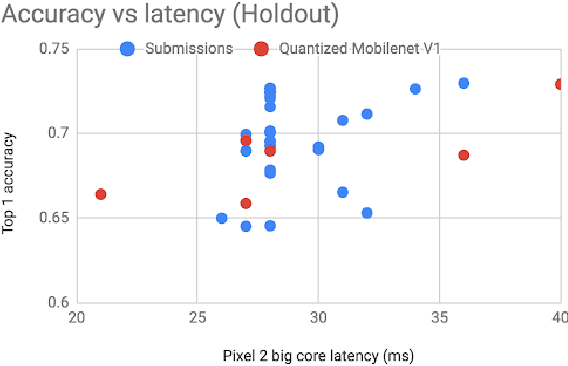
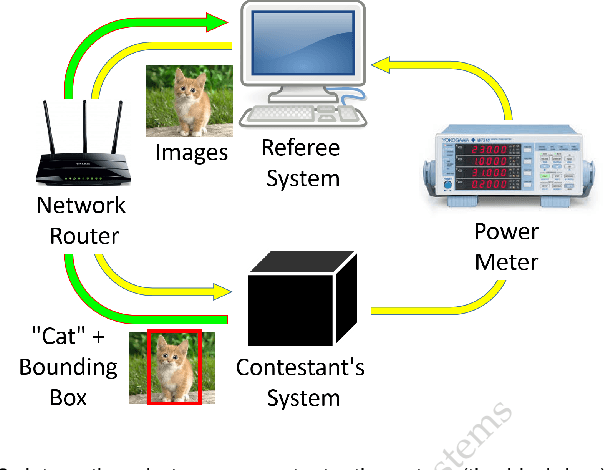
Computer vision has achieved impressive progress in recent years. Meanwhile, mobile phones have become the primary computing platforms for millions of people. In addition to mobile phones, many autonomous systems rely on visual data for making decisions and some of these systems have limited energy (such as unmanned aerial vehicles also called drones and mobile robots). These systems rely on batteries and energy efficiency is critical. This article serves two main purposes: (1) Examine the state-of-the-art for low-power solutions to detect objects in images. Since 2015, the IEEE Annual International Low-Power Image Recognition Challenge (LPIRC) has been held to identify the most energy-efficient computer vision solutions. This article summarizes 2018 winners' solutions. (2) Suggest directions for research as well as opportunities for low-power computer vision.