 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Nebula-I: A General Framework for Collaboratively Training Deep Learning Models on Low-Bandwidth Cloud Clusters
May 19, 2022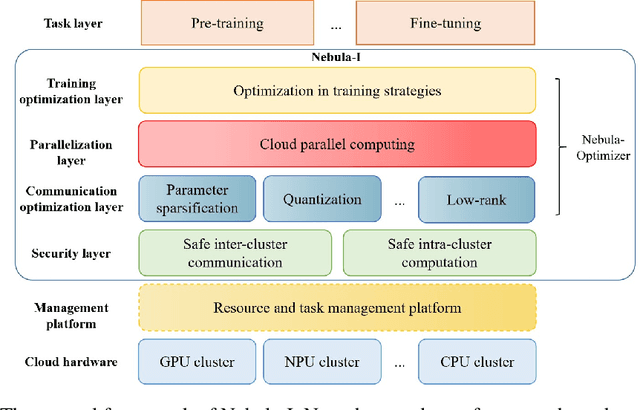
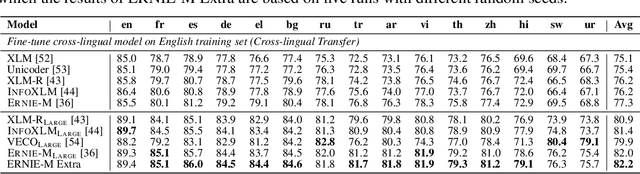
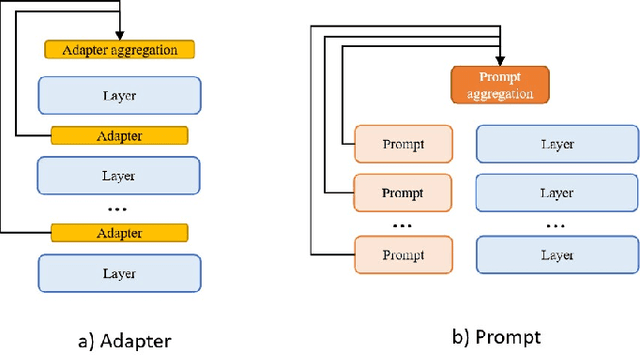
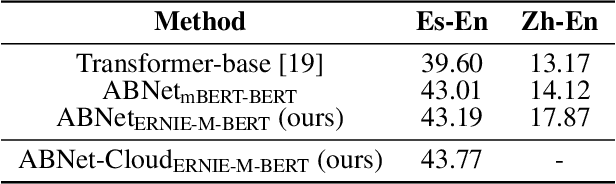
The ever-growing model size and scale of compute have attracted increasing interests in training deep learning models over multiple nodes. However, when it comes to training on cloud clusters, especially across remote clusters, huge challenges are faced. In this work, we introduce a general framework, Nebula-I, for collaboratively training deep learning models over remote heterogeneous clusters, the connections between which are low-bandwidth wide area networks (WANs). We took natural language processing (NLP) as an example to show how Nebula-I works in different training phases that include: a) pre-training a multilingual language model using two remote clusters; and b) fine-tuning a machine translation model using knowledge distilled from pre-trained models, which run through the most popular paradigm of recent deep learning. To balance the accuracy and communication efficiency, in Nebula-I, parameter-efficient training strategies, hybrid parallel computing methods and adaptive communication acceleration techniques are jointly applied. Meanwhile, security strategies are employed to guarantee the safety, reliability and privacy in intra-cluster computation and inter-cluster communication. Nebula-I is implemented with the PaddlePaddle deep learning framework, which can support collaborative training over heterogeneous hardware, e.g. GPU and NPU. Experiments demonstrate that the proposed framework could substantially maximize the training efficiency while preserving satisfactory NLP performance. By using Nebula-I, users can run large-scale training tasks over cloud clusters with minimum developments, and the utility of existed large pre-trained models could be further promoted. We also introduced new state-of-the-art results on cross-lingual natural language inference tasks, which are generated based upon a novel learning framework and Nebula-I.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021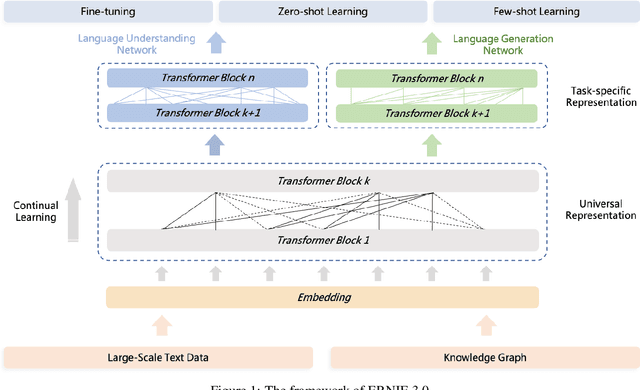
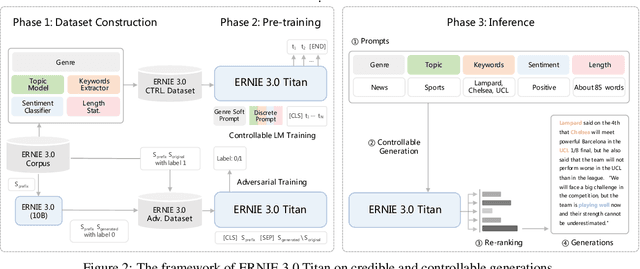
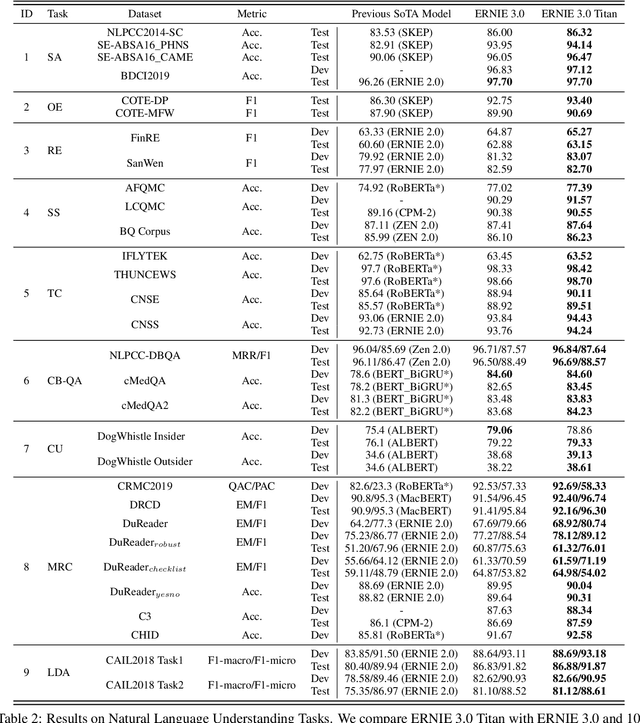
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.
End-to-end Adaptive Distributed Training on PaddlePaddle
Dec 06, 2021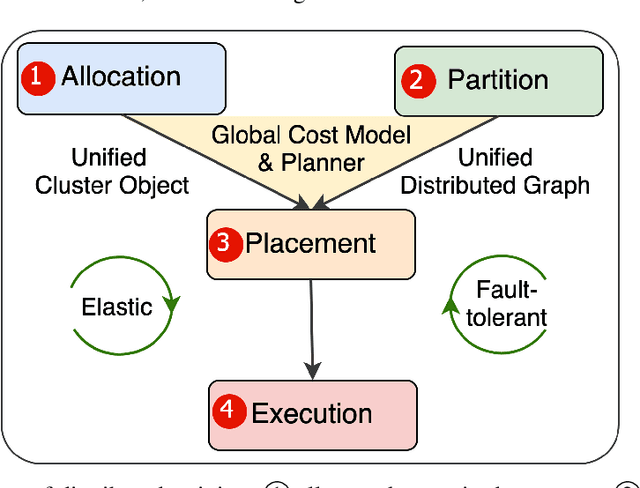
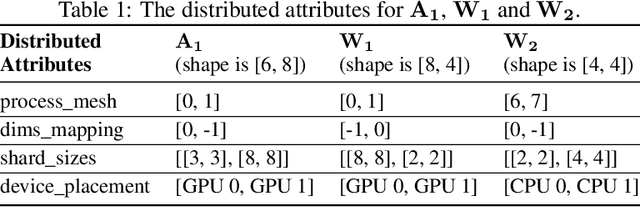
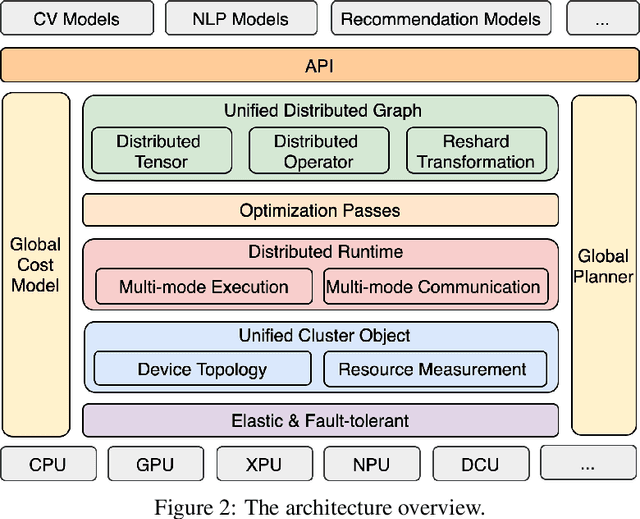
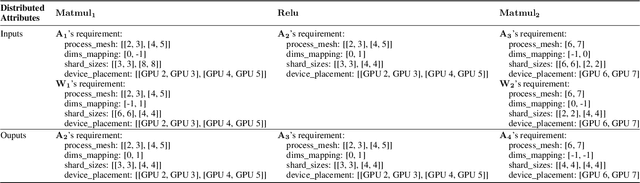
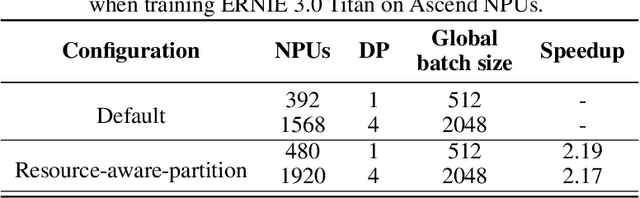
Distributed training has become a pervasive and effective approach for training a large neural network (NN) model with processing massive data. However, it is very challenging to satisfy requirements from various NN models, diverse computing resources, and their dynamic changes during a training job. In this study, we design our distributed training framework in a systematic end-to-end view to provide the built-in adaptive ability for different scenarios, especially for industrial applications and production environments, by fully considering resource allocation, model partition, task placement, and distributed execution. Based on the unified distributed graph and the unified cluster object, our adaptive framework is equipped with a global cost model and a global planner, which can enable arbitrary parallelism, resource-aware placement, multi-mode execution, fault-tolerant, and elastic distributed training. The experiments demonstrate that our framework can satisfy various requirements from the diversity of applications and the heterogeneity of resources with highly competitive performance. The ERNIE language model with 260 billion parameters is efficiently trained on thousands of AI processors with 91.7% weak scalability. The throughput of the model from the recommender system by employing the heterogeneous pipeline asynchronous execution can be increased up to 2.1 times and 3.3 times that of the GPU-only and CPU-only training respectively. Moreover, the fault-tolerant and elastic distributed training have been successfully applied to the online industrial applications, which give a reduction of 34.49% in the number of failed long-term training jobs and an increase of 33.91% for the global scheduling efficiency in the production environment.
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Jul 05, 2021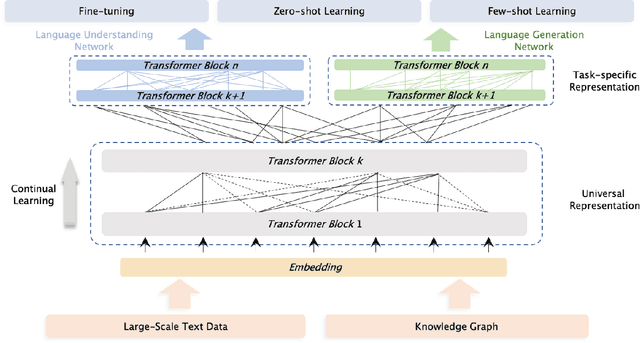

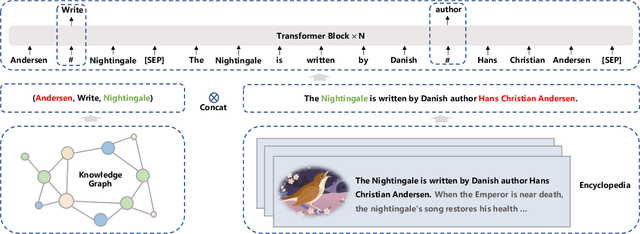
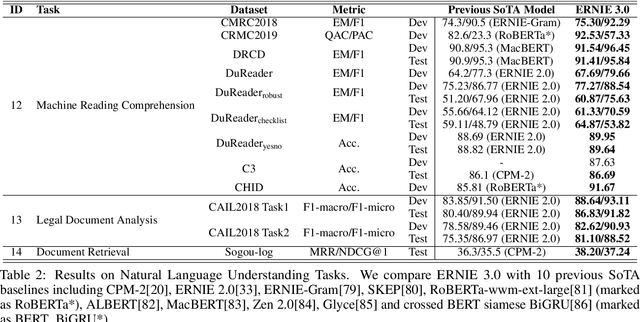
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 and GPT-3 have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).