 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing
Jan 29, 2026We introduce PaddleOCR-VL-1.5, an upgraded model achieving a new state-of-the-art (SOTA) accuracy of 94.5% on OmniDocBench v1.5. To rigorously evaluate robustness against real-world physical distortions, including scanning, skew, warping, screen-photography, and illumination, we propose the Real5-OmniDocBench benchmark. Experimental results demonstrate that this enhanced model attains SOTA performance on the newly curated benchmark. Furthermore, we extend the model's capabilities by incorporating seal recognition and text spotting tasks, while remaining a 0.9B ultra-compact VLM with high efficiency. Code: https://github.com/PaddlePaddle/PaddleOCR
PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
Oct 16, 2025In this report, we propose PaddleOCR-VL, a SOTA and resource-efficient model tailored for document parsing. Its core component is PaddleOCR-VL-0.9B, a compact yet powerful vision-language model (VLM) that integrates a NaViT-style dynamic resolution visual encoder with the ERNIE-4.5-0.3B language model to enable accurate element recognition. This innovative model efficiently supports 109 languages and excels in recognizing complex elements (e.g., text, tables, formulas, and charts), while maintaining minimal resource consumption. Through comprehensive evaluations on widely used public benchmarks and in-house benchmarks, PaddleOCR-VL achieves SOTA performance in both page-level document parsing and element-level recognition. It significantly outperforms existing solutions, exhibits strong competitiveness against top-tier VLMs, and delivers fast inference speeds. These strengths make it highly suitable for practical deployment in real-world scenarios.
Low-Precision Training of Large Language Models: Methods, Challenges, and Opportunities
May 02, 2025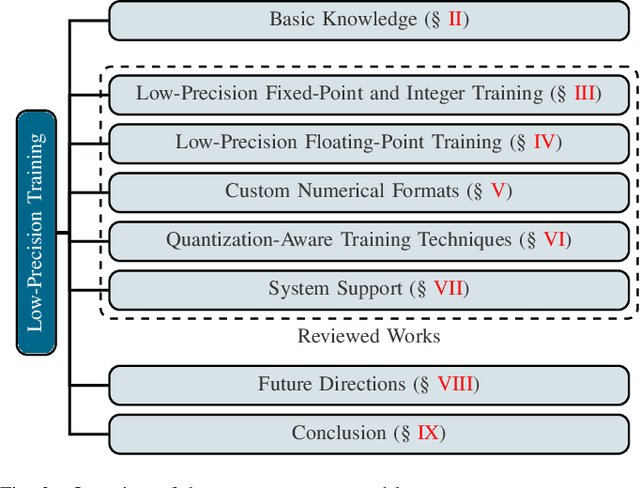
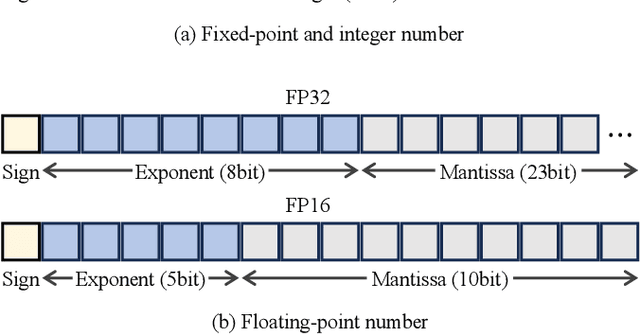
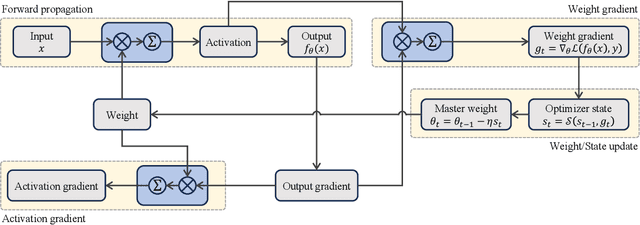
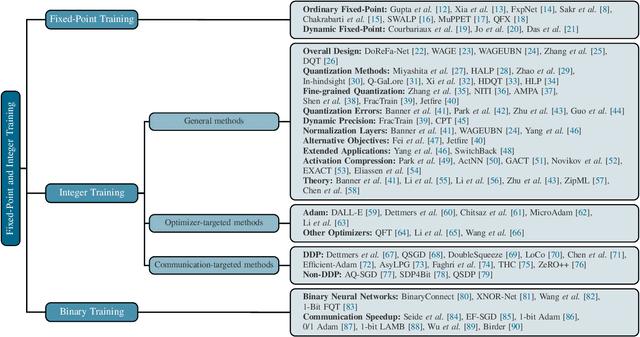
Large language models (LLMs) have achieved impressive performance across various domains. However, the substantial hardware resources required for their training present a significant barrier to efficiency and scalability. To mitigate this challenge, low-precision training techniques have been widely adopted, leading to notable advancements in training efficiency. Despite these gains, low-precision training involves several components$\unicode{x2013}$such as weights, activations, and gradients$\unicode{x2013}$each of which can be represented in different numerical formats. The resulting diversity has created a fragmented landscape in low-precision training research, making it difficult for researchers to gain a unified overview of the field. This survey provides a comprehensive review of existing low-precision training methods. To systematically organize these approaches, we categorize them into three primary groups based on their underlying numerical formats, which is a key factor influencing hardware compatibility, computational efficiency, and ease of reference for readers. The categories are: (1) fixed-point and integer-based methods, (2) floating-point-based methods, and (3) customized format-based methods. Additionally, we discuss quantization-aware training approaches, which share key similarities with low-precision training during forward propagation. Finally, we highlight several promising research directions to advance this field. A collection of papers discussed in this survey is provided in https://github.com/Hao840/Awesome-Low-Precision-Training.
FlashMask: Efficient and Rich Mask Extension of FlashAttention
Oct 02, 2024


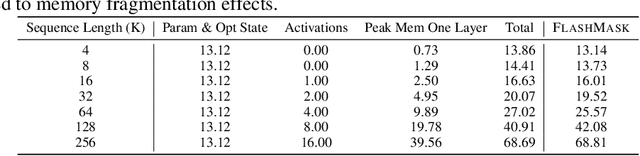
The computational and memory demands of vanilla attention scale quadratically with the sequence length $N$, posing significant challenges for processing long sequences in Transformer models. FlashAttention alleviates these challenges by eliminating the $O(N^2)$ memory dependency and reducing attention latency through IO-aware memory optimizations. However, its native support for certain attention mask types is limited, and it does not inherently accommodate more complex masking requirements. Previous approaches resort to using dense masks with $O(N^2)$ memory complexity, leading to inefficiencies. In this paper, we propose FlashMask, an extension of FlashAttention that introduces a column-wise sparse representation of attention masks. This approach efficiently represents a wide range of mask types and facilitates the development of optimized kernel implementations. By adopting this novel representation, FlashMask achieves linear memory complexity $O(N)$, suitable for modeling long-context sequences. Moreover, this representation enables kernel optimizations that eliminate unnecessary computations by leveraging sparsity in the attention mask, without sacrificing computational accuracy, resulting in higher computational efficiency. We evaluate FlashMask's performance in fine-tuning and alignment training of LLMs such as SFT, LoRA, DPO, and RM. FlashMask achieves significant throughput improvements, with end-to-end speedups ranging from 1.65x to 3.22x compared to existing FlashAttention dense method. Additionally, our kernel-level comparisons demonstrate that FlashMask surpasses the latest counterpart, FlexAttention, by 12.1% to 60.7% in terms of kernel TFLOPs/s, achieving 37.8% to 62.3% of the theoretical maximum FLOPs/s on the A100 GPU. The code is open-sourced on PaddlePaddle and integrated into PaddleNLP, supporting models with over 100 billion parameters for contexts up to 128K tokens.
NACL: A General and Effective KV Cache Eviction Framework for LLMs at Inference Time
Aug 07, 2024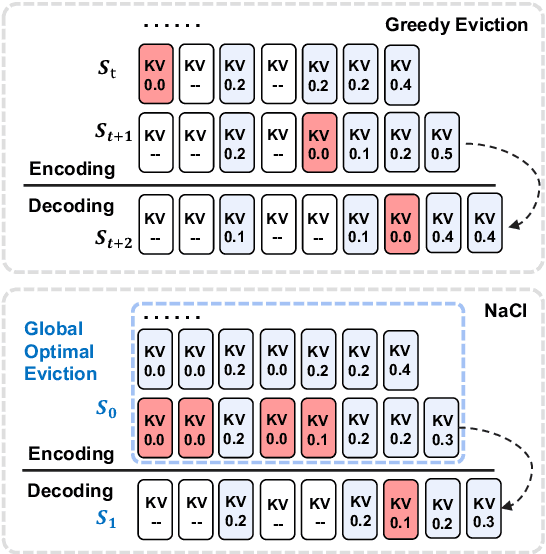
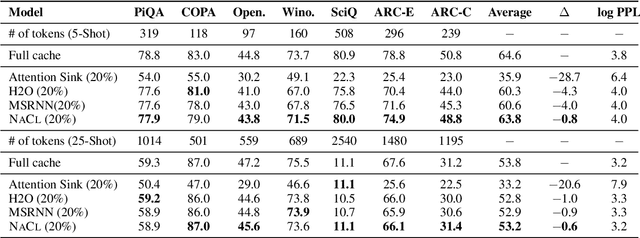
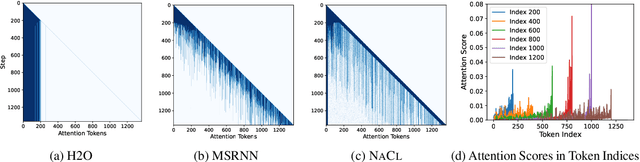
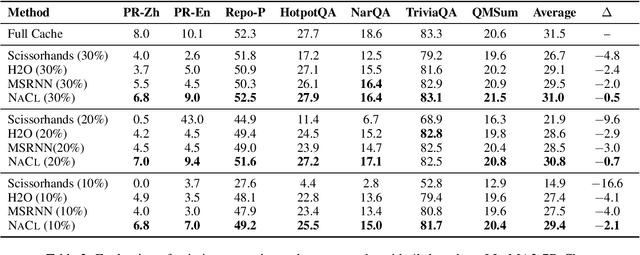
Large Language Models (LLMs) have ignited an innovative surge of AI applications, marking a new era of exciting possibilities equipped with extended context windows. However, hosting these models is cost-prohibitive mainly due to the extensive memory consumption of KV Cache involving long-context modeling. Despite several works proposing to evict unnecessary tokens from the KV Cache, most of them rely on the biased local statistics of accumulated attention scores and report performance using unconvincing metric like perplexity on inadequate short-text evaluation. In this paper, we propose NACL, a general framework for long-context KV cache eviction that achieves more optimal and efficient eviction in a single operation during the encoding phase. Due to NACL's efficiency, we combine more accurate attention score statistics in PROXY TOKENS EVICTION with the diversified random eviction strategy of RANDOM EVICTION, aiming to alleviate the issue of attention bias and enhance the robustness in maintaining pivotal tokens for long-context modeling tasks. Notably, our method significantly improves the performance on short- and long-text tasks by 80% and 76% respectively, reducing KV Cache by up to 50% with over 95% performance maintenance. The code is available at https: //github.com/PaddlePaddle/Research/ tree/master/NLP/ACL2024-NACL.
A Framework for Cost-Effective and Self-Adaptive LLM Shaking and Recovery Mechanism
Mar 12, 2024



As Large Language Models (LLMs) gain great success in real-world applications, an increasing number of users are seeking to develop and deploy their customized LLMs through cloud services. Nonetheless, in some specific domains, there are still concerns regarding cost and trade-offs between privacy issues and accuracy. In this study, we introduce a cost-effective and self-adaptive LLM shaking tuning and recovery mechanism, named CypherTalk. With carefully designed horizontal and vertical shaking operators, we can achieve comparable accuracy results with SOTA privacy-preserving LLM schemes using Cryptography-based or Differential Privacy-based methods. Experiments also show that with the CypherTalk framework, users can achieve reliable accuracy when using optimized shaking operator settings. To our best knowledge, this is the first work that considers cost, and trade-off between model utility and privacy in LLM scenarios.
Spectral Heterogeneous Graph Convolutions via Positive Noncommutative Polynomials
May 31, 2023Heterogeneous Graph Neural Networks (HGNNs) have gained significant popularity in various heterogeneous graph learning tasks. However, most HGNNs rely on spatial domain-based message passing and attention modules for information propagation and aggregation. These spatial-based HGNNs neglect the utilization of spectral graph convolutions, which are the foundation of Graph Convolutional Networks (GCN) on homogeneous graphs. Inspired by the effectiveness and scalability of spectral-based GNNs on homogeneous graphs, this paper explores the extension of spectral-based GNNs to heterogeneous graphs. We propose PSHGCN, a novel heterogeneous convolutional network based on positive noncommutative polynomials. PSHGCN provides a simple yet effective approach for learning spectral graph convolutions on heterogeneous graphs. Moreover, we demonstrate the rationale of PSHGCN in graph optimization. We conducted an extensive experimental study to show that PSHGCN can learn diverse spectral heterogeneous graph convolutions and achieve superior performance in node classification tasks. Our code is available at https://github.com/ivam-he/PSHGCN.
Label Information Enhanced Fraud Detection against Low Homophily in Graphs
Feb 21, 2023



Node classification is a substantial problem in graph-based fraud detection. Many existing works adopt Graph Neural Networks (GNNs) to enhance fraud detectors. While promising, currently most GNN-based fraud detectors fail to generalize to the low homophily setting. Besides, label utilization has been proved to be significant factor for node classification problem. But we find they are less effective in fraud detection tasks due to the low homophily in graphs. In this work, we propose GAGA, a novel Group AGgregation enhanced TrAnsformer, to tackle the above challenges. Specifically, the group aggregation provides a portable method to cope with the low homophily issue. Such an aggregation explicitly integrates the label information to generate distinguishable neighborhood information. Along with group aggregation, an attempt towards end-to-end trainable group encoding is proposed which augments the original feature space with the class labels. Meanwhile, we devise two additional learnable encodings to recognize the structural and relational context. Then, we combine the group aggregation and the learnable encodings into a Transformer encoder to capture the semantic information. Experimental results clearly show that GAGA outperforms other competitive graph-based fraud detectors by up to 24.39% on two trending public datasets and a real-world industrial dataset from Anonymous. Even more, the group aggregation is demonstrated to outperform other label utilization methods (e.g., C&S, BoT/UniMP) in the low homophily setting.
TA-MoE: Topology-Aware Large Scale Mixture-of-Expert Training
Feb 20, 2023Sparsely gated Mixture-of-Expert (MoE) has demonstrated its effectiveness in scaling up deep neural networks to an extreme scale. Despite that numerous efforts have been made to improve the performance of MoE from the model design or system optimization perspective, existing MoE dispatch patterns are still not able to fully exploit the underlying heterogeneous network environments. In this paper, we propose TA-MoE, a topology-aware routing strategy for large-scale MoE trainging, from a model-system co-design perspective, which can dynamically adjust the MoE dispatch pattern according to the network topology. Based on communication modeling, we abstract the dispatch problem into an optimization objective and obtain the approximate dispatch pattern under different topologies. On top of that, we design a topology-aware auxiliary loss, which can adaptively route the data to fit in the underlying topology without sacrificing the model accuracy. Experiments show that TA-MoE can substantially outperform its counterparts on various hardware and model configurations, with roughly 1.01x-1.61x, 1.01x-4.77x, 1.25x-1.54x improvements over the popular DeepSpeed-MoE, FastMoE and FasterMoE.
PP-YOLOE-R: An Efficient Anchor-Free Rotated Object Detector
Nov 04, 2022



Arbitrary-oriented object detection is a fundamental task in visual scenes involving aerial images and scene text. In this report, we present PP-YOLOE-R, an efficient anchor-free rotated object detector based on PP-YOLOE. We introduce a bag of useful tricks in PP-YOLOE-R to improve detection precision with marginal extra parameters and computational cost. As a result, PP-YOLOE-R-l and PP-YOLOE-R-x achieve 78.14 and 78.28 mAP respectively on DOTA 1.0 dataset with single-scale training and testing, which outperform almost all other rotated object detectors. With multi-scale training and testing, PP-YOLOE-R-l and PP-YOLOE-R-x further improve the detection precision to 80.02 and 80.73 mAP. In this case, PP-YOLOE-R-x surpasses all anchor-free methods and demonstrates competitive performance to state-of-the-art anchor-based two-stage models. Further, PP-YOLOE-R is deployment friendly and PP-YOLOE-R-s/m/l/x can reach 69.8/55.1/48.3/37.1 FPS respectively on RTX 2080 Ti with TensorRT and FP16-precision. Source code and pre-trained models are available at https://github.com/PaddlePaddle/PaddleDetection, which is powered by https://github.com/PaddlePaddle/Paddle.