 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-mmLayout: Multi-grained MultiModal Transformer for Document Understanding
Paper and Code
Sep 18, 2022


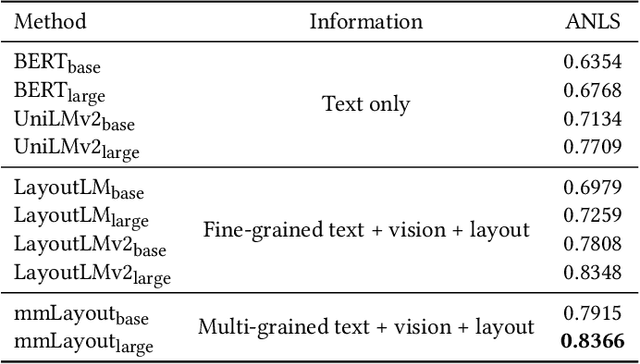
Recent efforts of multimodal Transformers have improved Visually Rich Document Understanding (VrDU) tasks via incorporating visual and textual information. However, existing approaches mainly focus on fine-grained elements such as words and document image patches, making it hard for them to learn from coarse-grained elements, including natural lexical units like phrases and salient visual regions like prominent image regions. In this paper, we attach more importance to coarse-grained elements containing high-density information and consistent semantics, which are valuable for document understanding. At first, a document graph is proposed to model complex relationships among multi-grained multimodal elements, in which salient visual regions are detected by a cluster-based method. Then, a multi-grained multimodal Transformer called mmLayout is proposed to incorporate coarse-grained information into existing pre-trained fine-grained multimodal Transformers based on the graph. In mmLayout, coarse-grained information is aggregated from fine-grained, and then, after further processing, is fused back into fine-grained for final prediction. Furthermore, common sense enhancement is introduced to exploit the semantic information of natural lexical units. Experimental results on four tasks, including information extraction and document question answering, show that our method can improve the performance of multimodal Transformers based on fine-grained elements and achieve better performance with fewer parameters. Qualitative analyses show that our method can capture consistent semantics in coarse-grained elements.