 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATTNPO: Attention-Guided Process Supervision for Efficient Reasoning
Feb 10, 2026Large reasoning models trained with reinforcement learning and verifiable rewards (RLVR) achieve strong performance on complex reasoning tasks, yet often overthink, generating redundant reasoning without performance gains. Existing trajectory-level length penalties often fail to effectively shorten reasoning length and degrade accuracy, as they uniformly treat all reasoning steps and lack fine-grained signals to distinguish redundancy from necessity. Meanwhile, process-supervised methods are typically resource-intensive and suffer from inaccurate credit assignment. To address these issues, we propose ATTNPO, a low-overhead process-supervised RL framework that leverages the model's intrinsic attention signals for step-level credit assignment. We first identify a set of special attention heads that naturally focus on essential steps while suppressing redundant ones. By leveraging the attention scores of these heads, We then employ two sub-strategies to mitigate overthinking by discouraging redundant steps while preserving accuracy by reducing penalties on essential steps. Experimental results show that ATTNPO substantially reduces reasoning length while significantly improving performance across 9 benchmarks.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Weights-Rotated Preference Optimization for Large Language Models
Aug 25, 2025Despite the efficacy of Direct Preference Optimization (DPO) in aligning Large Language Models (LLMs), reward hacking remains a pivotal challenge. This issue emerges when LLMs excessively reduce the probability of rejected completions to achieve high rewards, without genuinely meeting their intended goals. As a result, this leads to overly lengthy generation lacking diversity, as well as catastrophic forgetting of knowledge. We investigate the underlying reason behind this issue, which is representation redundancy caused by neuron collapse in the parameter space. Hence, we propose a novel Weights-Rotated Preference Optimization (RoPO) algorithm, which implicitly constrains the output layer logits with the KL divergence inherited from DPO and explicitly constrains the intermediate hidden states by fine-tuning on a multi-granularity orthogonal matrix. This design prevents the policy model from deviating too far from the reference model, thereby retaining the knowledge and expressive capabilities acquired during pre-training and SFT stages. Our RoPO achieves up to a 3.27-point improvement on AlpacaEval 2, and surpasses the best baseline by 6.2 to 7.5 points on MT-Bench with merely 0.015% of the trainable parameters, demonstrating its effectiveness in alleviating the reward hacking problem of DPO.
ERNIE-UniX2: A Unified Cross-lingual Cross-modal Framework for Understanding and Generation
Nov 09, 2022



Recent cross-lingual cross-modal works attempt to extend Vision-Language Pre-training (VLP) models to non-English inputs and achieve impressive performance. However, these models focus only on understanding tasks utilizing encoder-only architecture. In this paper, we propose ERNIE-UniX2, a unified cross-lingual cross-modal pre-training framework for both generation and understanding tasks. ERNIE-UniX2 integrates multiple pre-training paradigms (e.g., contrastive learning and language modeling) based on encoder-decoder architecture and attempts to learn a better joint representation across languages and modalities. Furthermore, ERNIE-UniX2 can be seamlessly fine-tuned for varieties of generation and understanding downstream tasks. Pre-trained on both multilingual text-only and image-text datasets, ERNIE-UniX2 achieves SOTA results on various cross-lingual cross-modal generation and understanding tasks such as multimodal machine translation and multilingual visual question answering.
ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts
Oct 27, 2022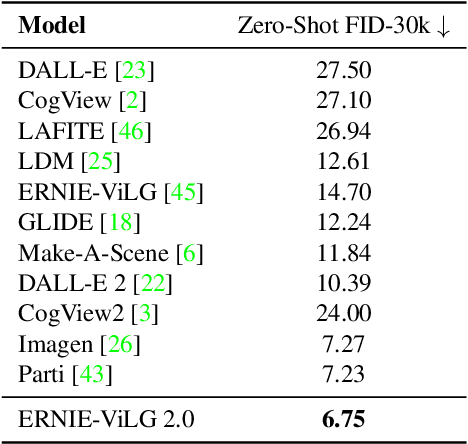
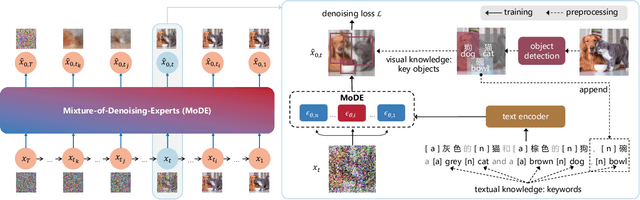
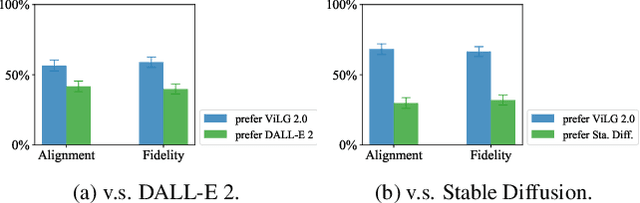
Recent progress in diffusion models has revolutionized the popular technology of text-to-image generation. While existing approaches could produce photorealistic high-resolution images with text conditions, there are still several open problems to be solved, which limits the further improvement of image fidelity and text relevancy. In this paper, we propose ERNIE-ViLG 2.0, a large-scale Chinese text-to-image diffusion model, which progressively upgrades the quality of generated images~by: (1) incorporating fine-grained textual and visual knowledge of key elements in the scene, and (2) utilizing different denoising experts at different denoising stages. With the proposed mechanisms, ERNIE-ViLG 2.0 not only achieves the state-of-the-art on MS-COCO with zero-shot FID score of 6.75, but also significantly outperforms recent models in terms of image fidelity and image-text alignment, with side-by-side human evaluation on the bilingual prompt set ViLG-300.
ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
Oct 14, 2022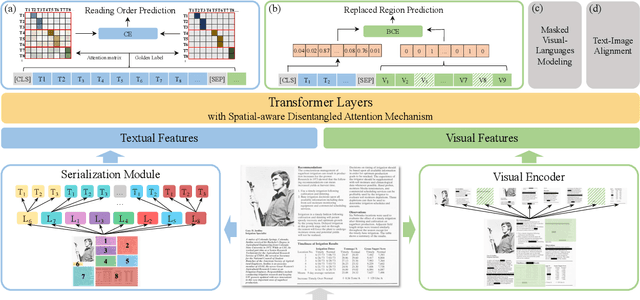



Recent years have witnessed the rise and success of pre-training techniques in visually-rich document understanding. However, most existing methods lack the systematic mining and utilization of layout-centered knowledge, leading to sub-optimal performances. In this paper, we propose ERNIE-Layout, a novel document pre-training solution with layout knowledge enhancement in the whole workflow, to learn better representations that combine the features from text, layout, and image. Specifically, we first rearrange input sequences in the serialization stage, and then present a correlative pre-training task, reading order prediction, to learn the proper reading order of documents. To improve the layout awareness of the model, we integrate a spatial-aware disentangled attention into the multi-modal transformer and a replaced regions prediction task into the pre-training phase. Experimental results show that ERNIE-Layout achieves superior performance on various downstream tasks, setting new state-of-the-art on key information extraction, document image classification, and document question answering datasets. The code and models are publicly available at http://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout.
ERNIE-ViL 2.0: Multi-view Contrastive Learning for Image-Text Pre-training
Sep 30, 2022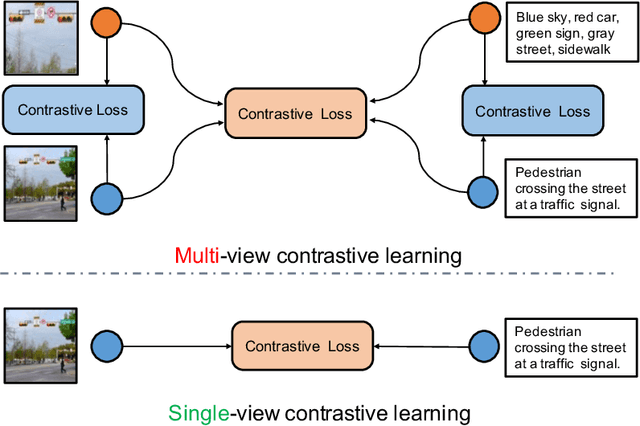
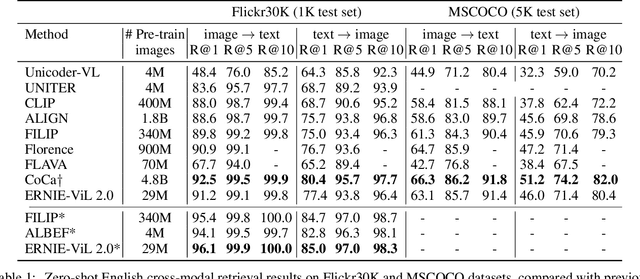
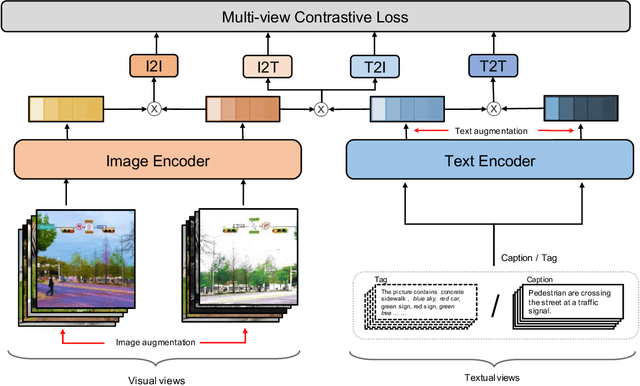
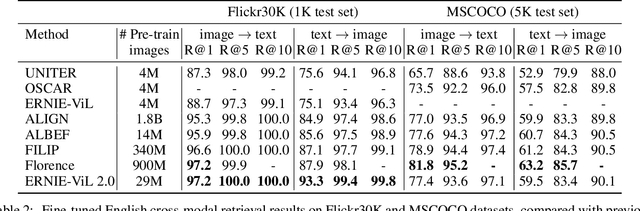
Recent Vision-Language Pre-trained (VLP) models based on dual encoder have attracted extensive attention from academia and industry due to their superior performance on various cross-modal tasks and high computational efficiency. They attempt to learn cross-modal representation using contrastive learning on image-text pairs, however, the built inter-modal correlations only rely on a single view for each modality. Actually, an image or a text contains various potential views, just as humans could capture a real-world scene via diverse descriptions or photos. In this paper, we propose ERNIE-ViL 2.0, a Multi-View Contrastive learning framework to build intra-modal and inter-modal correlations between diverse views simultaneously, aiming at learning a more robust cross-modal representation. Specifically, we construct multiple views within each modality to learn the intra-modal correlation for enhancing the single-modal representation. Besides the inherent visual/textual views, we construct sequences of object tags as a special textual view to narrow the cross-modal semantic gap on noisy image-text pairs. Pre-trained with 29M publicly available datasets, ERNIE-ViL 2.0 achieves competitive results on English cross-modal retrieval. Additionally, to generalize our method to Chinese cross-modal tasks, we train ERNIE-ViL 2.0 through scaling up the pre-training datasets to 1.5B Chinese image-text pairs, resulting in significant improvements compared to previous SOTA results on Chinese cross-modal retrieval. We release our pre-trained models in https://github.com/PaddlePaddle/ERNIE.
ERNIE-mmLayout: Multi-grained MultiModal Transformer for Document Understanding
Sep 18, 2022


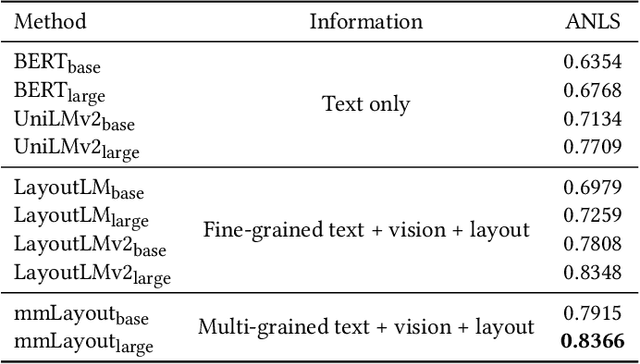
Recent efforts of multimodal Transformers have improved Visually Rich Document Understanding (VrDU) tasks via incorporating visual and textual information. However, existing approaches mainly focus on fine-grained elements such as words and document image patches, making it hard for them to learn from coarse-grained elements, including natural lexical units like phrases and salient visual regions like prominent image regions. In this paper, we attach more importance to coarse-grained elements containing high-density information and consistent semantics, which are valuable for document understanding. At first, a document graph is proposed to model complex relationships among multi-grained multimodal elements, in which salient visual regions are detected by a cluster-based method. Then, a multi-grained multimodal Transformer called mmLayout is proposed to incorporate coarse-grained information into existing pre-trained fine-grained multimodal Transformers based on the graph. In mmLayout, coarse-grained information is aggregated from fine-grained, and then, after further processing, is fused back into fine-grained for final prediction. Furthermore, common sense enhancement is introduced to exploit the semantic information of natural lexical units. Experimental results on four tasks, including information extraction and document question answering, show that our method can improve the performance of multimodal Transformers based on fine-grained elements and achieve better performance with fewer parameters. Qualitative analyses show that our method can capture consistent semantics in coarse-grained elements.
ERNIE-ViLG: Unified Generative Pre-training for Bidirectional Vision-Language Generation
Dec 31, 2021
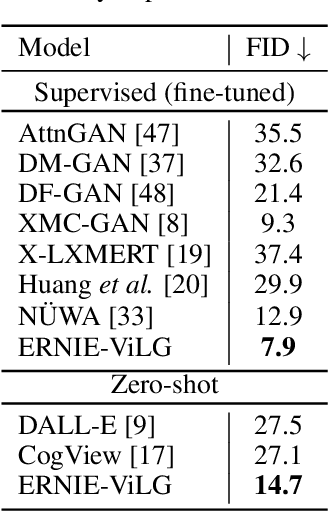


Conventional methods for the image-text generation tasks mainly tackle the naturally bidirectional generation tasks separately, focusing on designing task-specific frameworks to improve the quality and fidelity of the generated samples. Recently, Vision-Language Pre-training models have greatly improved the performance of the image-to-text generation tasks, but large-scale pre-training models for text-to-image synthesis task are still under-developed. In this paper, we propose ERNIE-ViLG, a unified generative pre-training framework for bidirectional image-text generation with transformer model. Based on the image quantization models, we formulate both image generation and text generation as autoregressive generative tasks conditioned on the text/image input. The bidirectional image-text generative modeling eases the semantic alignments across vision and language. For the text-to-image generation process, we further propose an end-to-end training method to jointly learn the visual sequence generator and the image reconstructor. To explore the landscape of large-scale pre-training for bidirectional text-image generation, we train a 10-billion parameter ERNIE-ViLG model on a large-scale dataset of 145 million (Chinese) image-text pairs which achieves state-of-the-art performance for both text-to-image and image-to-text tasks, obtaining an FID of 7.9 on MS-COCO for text-to-image synthesis and best results on COCO-CN and AIC-ICC for image captioning.
ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph
Jun 30, 2020

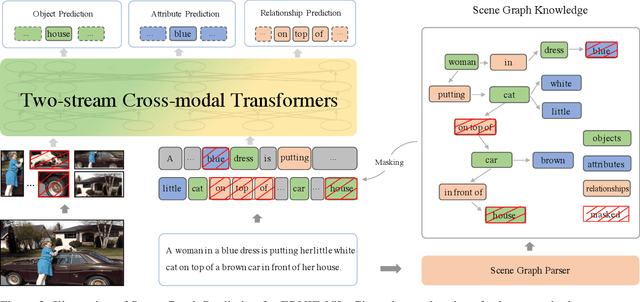
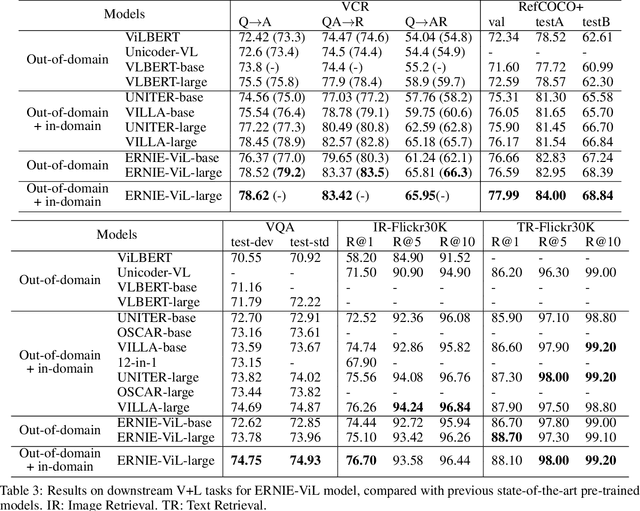
We propose a knowledge-enhanced approach, ERNIE-ViL, to learn joint representations of vision and language. ERNIE-ViL tries to construct the detailed semantic connections (objects, attributes of objects and relationships between objects in visual scenes) across vision and language, which are essential to vision-language cross-modal tasks. Incorporating knowledge from scene graphs, ERNIE-ViL constructs Scene Graph Prediction tasks, i.e., Object Prediction, Attribute Prediction and Relationship Prediction in the pre-training phase. More specifically, these prediction tasks are implemented by predicting nodes of different types in the scene graph parsed from the sentence. Thus, ERNIE-ViL can model the joint representation characterizing the alignments of the detailed semantics across vision and language. Pre-trained on two large image-text alignment datasets (Conceptual Captions and SBU), ERNIE-ViL learns better and more robust joint representations. It achieves state-of-the-art performance on 5 vision-language downstream tasks after fine-tuning ERNIE-ViL. Furthermore, it ranked the 1st place on the VCR leader-board with an absolute improvement of 3.7\%.