 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Efficient Text-Guided 3D-Aware Portrait Generation with Score Distillation Sampling on Distribution
Jun 03, 2023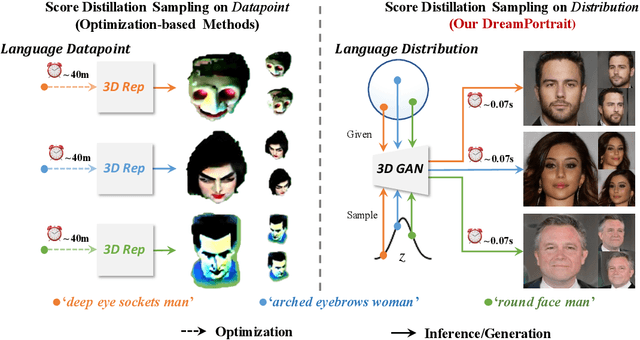

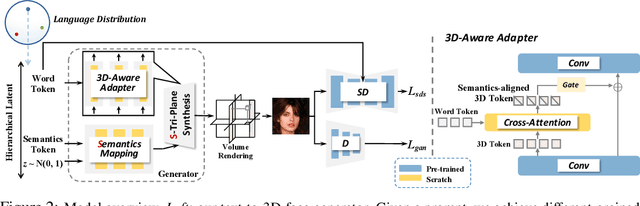

Text-to-3D is an emerging task that allows users to create 3D content with infinite possibilities. Existing works tackle the problem by optimizing a 3D representation with guidance from pre-trained diffusion models. An apparent drawback is that they need to optimize from scratch for each prompt, which is computationally expensive and often yields poor visual fidelity. In this paper, we propose DreamPortrait, which aims to generate text-guided 3D-aware portraits in a single-forward pass for efficiency. To achieve this, we extend Score Distillation Sampling from datapoint to distribution formulation, which injects semantic prior into a 3D distribution. However, the direct extension will lead to the mode collapse problem since the objective only pursues semantic alignment. Hence, we propose to optimize a distribution with hierarchical condition adapters and GAN loss regularization. For better 3D modeling, we further design a 3D-aware gated cross-attention mechanism to explicitly let the model perceive the correspondence between the text and the 3D-aware space. These elaborated designs enable our model to generate portraits with robust multi-view semantic consistency, eliminating the need for optimization-based methods. Extensive experiments demonstrate our model's highly competitive performance and significant speed boost against existing methods.
ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts
Oct 27, 2022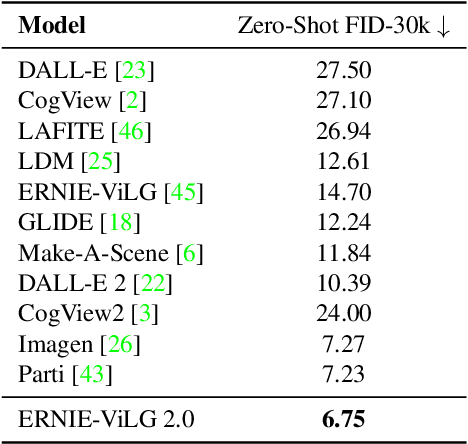
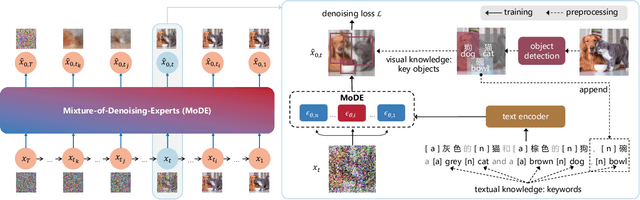
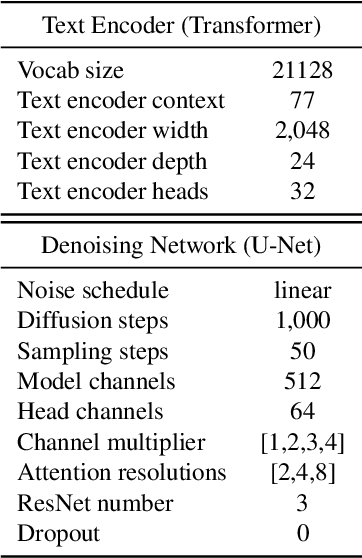
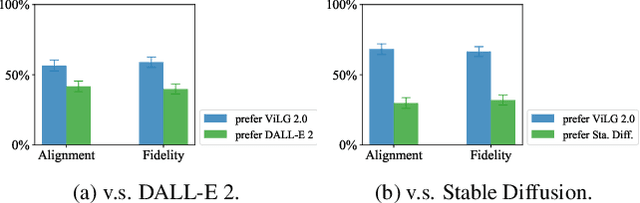
Recent progress in diffusion models has revolutionized the popular technology of text-to-image generation. While existing approaches could produce photorealistic high-resolution images with text conditions, there are still several open problems to be solved, which limits the further improvement of image fidelity and text relevancy. In this paper, we propose ERNIE-ViLG 2.0, a large-scale Chinese text-to-image diffusion model, which progressively upgrades the quality of generated images~by: (1) incorporating fine-grained textual and visual knowledge of key elements in the scene, and (2) utilizing different denoising experts at different denoising stages. With the proposed mechanisms, ERNIE-ViLG 2.0 not only achieves the state-of-the-art on MS-COCO with zero-shot FID score of 6.75, but also significantly outperforms recent models in terms of image fidelity and image-text alignment, with side-by-side human evaluation on the bilingual prompt set ViLG-300.
VD-PCR: Improving Visual Dialog with Pronoun Coreference Resolution
May 29, 2022
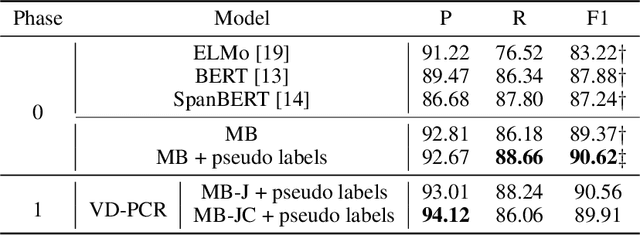
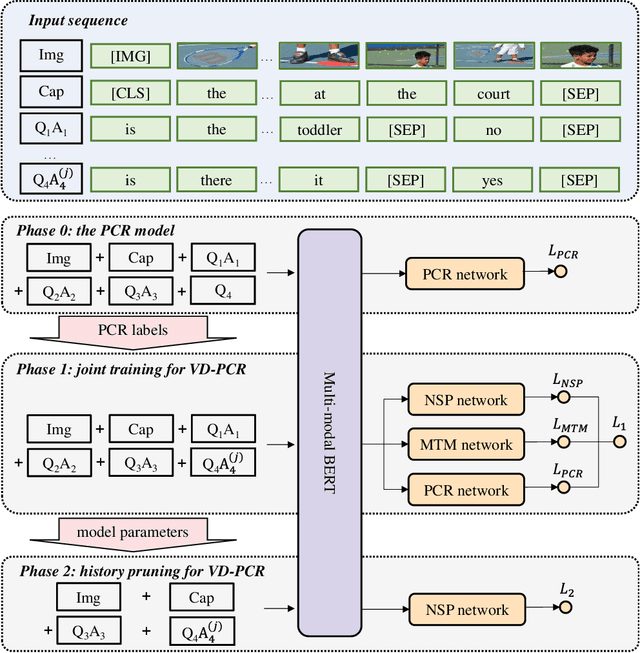
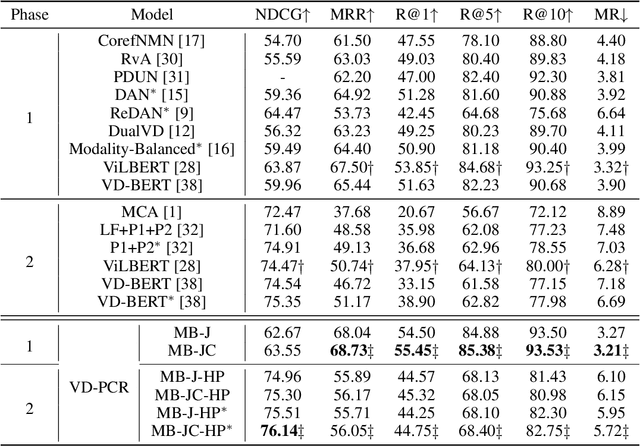
The visual dialog task requires an AI agent to interact with humans in multi-round dialogs based on a visual environment. As a common linguistic phenomenon, pronouns are often used in dialogs to improve the communication efficiency. As a result, resolving pronouns (i.e., grounding pronouns to the noun phrases they refer to) is an essential step towards understanding dialogs. In this paper, we propose VD-PCR, a novel framework to improve Visual Dialog understanding with Pronoun Coreference Resolution in both implicit and explicit ways. First, to implicitly help models understand pronouns, we design novel methods to perform the joint training of the pronoun coreference resolution and visual dialog tasks. Second, after observing that the coreference relationship of pronouns and their referents indicates the relevance between dialog rounds, we propose to explicitly prune the irrelevant history rounds in visual dialog models' input. With pruned input, the models can focus on relevant dialog history and ignore the distraction in the irrelevant one. With the proposed implicit and explicit methods, VD-PCR achieves state-of-the-art experimental results on the VisDial dataset.
* The manuscript version of the paper. The published version is available at https://doi.org/10.1016/j.patcog.2022.108540 . The data, code and models are available at: https://github.com/HKUST- KnowComp/VD-PCR
METGEN: A Module-Based Entailment Tree Generation Framework for Answer Explanation
May 05, 2022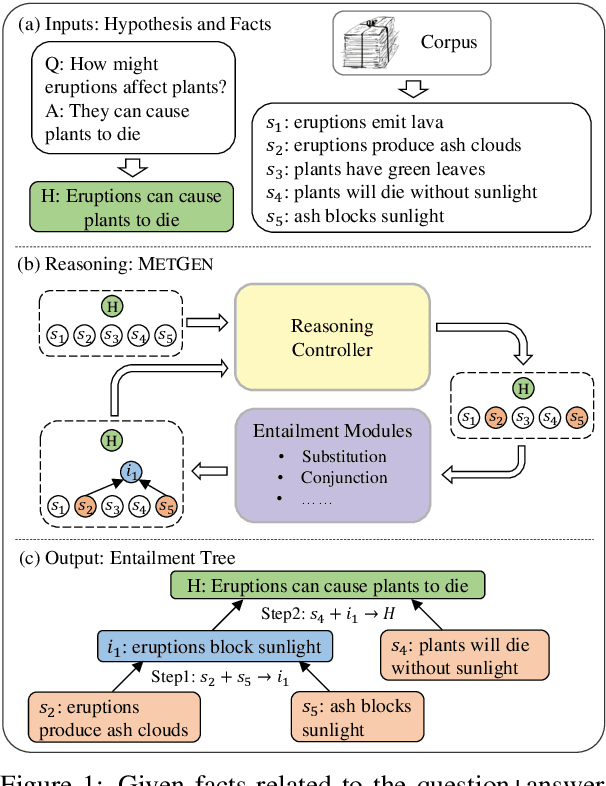

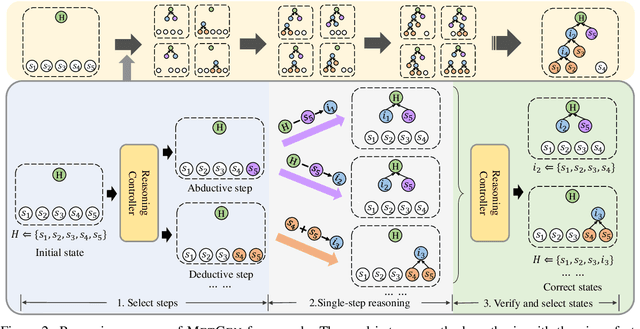
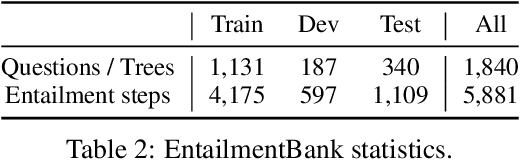
Knowing the reasoning chains from knowledge to the predicted answers can help construct an explainable question answering (QA) system. Advances on QA explanation propose to explain the answers with entailment trees composed of multiple entailment steps. While current work proposes to generate entailment trees with end-to-end generative models, the steps in the generated trees are not constrained and could be unreliable. In this paper, we propose METGEN, a Module-based Entailment Tree GENeration framework that has multiple modules and a reasoning controller. Given a question and several supporting knowledge, METGEN can iteratively generate the entailment tree by conducting single-step entailment with separate modules and selecting the reasoning flow with the controller. As each module is guided to perform a specific type of entailment reasoning, the steps generated by METGEN are more reliable and valid. Experiment results on the standard benchmark show that METGEN can outperform previous state-of-the-art models with only 9% of the parameters.
Exophoric Pronoun Resolution in Dialogues with Topic Regularization
Sep 10, 2021



Resolving pronouns to their referents has long been studied as a fundamental natural language understanding problem. Previous works on pronoun coreference resolution (PCR) mostly focus on resolving pronouns to mentions in text while ignoring the exophoric scenario. Exophoric pronouns are common in daily communications, where speakers may directly use pronouns to refer to some objects present in the environment without introducing the objects first. Although such objects are not mentioned in the dialogue text, they can often be disambiguated by the general topics of the dialogue. Motivated by this, we propose to jointly leverage the local context and global topics of dialogues to solve the out-of-text PCR problem. Extensive experiments demonstrate the effectiveness of adding topic regularization for resolving exophoric pronouns.
What You See is What You Get: Visual Pronoun Coreference Resolution in Dialogues
Sep 01, 2019


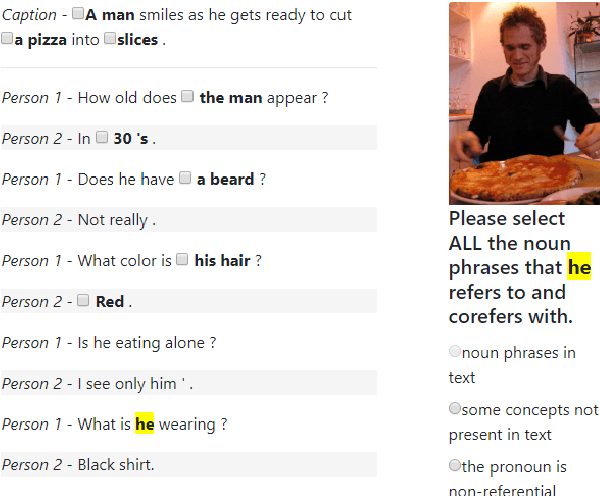
Grounding a pronoun to a visual object it refers to requires complex reasoning from various information sources, especially in conversational scenarios. For example, when people in a conversation talk about something all speakers can see, they often directly use pronouns (e.g., it) to refer to it without previous introduction. This fact brings a huge challenge for modern natural language understanding systems, particularly conventional context-based pronoun coreference models. To tackle this challenge, in this paper, we formally define the task of visual-aware pronoun coreference resolution (PCR) and introduce VisPro, a large-scale dialogue PCR dataset, to investigate whether and how the visual information can help resolve pronouns in dialogues. We then propose a novel visual-aware PCR model, VisCoref, for this task and conduct comprehensive experiments and case studies on our dataset. Results demonstrate the importance of the visual information in this PCR case and show the effectiveness of the proposed model.
Foreground segmentation based on multi-resolution and matting
Feb 10, 2014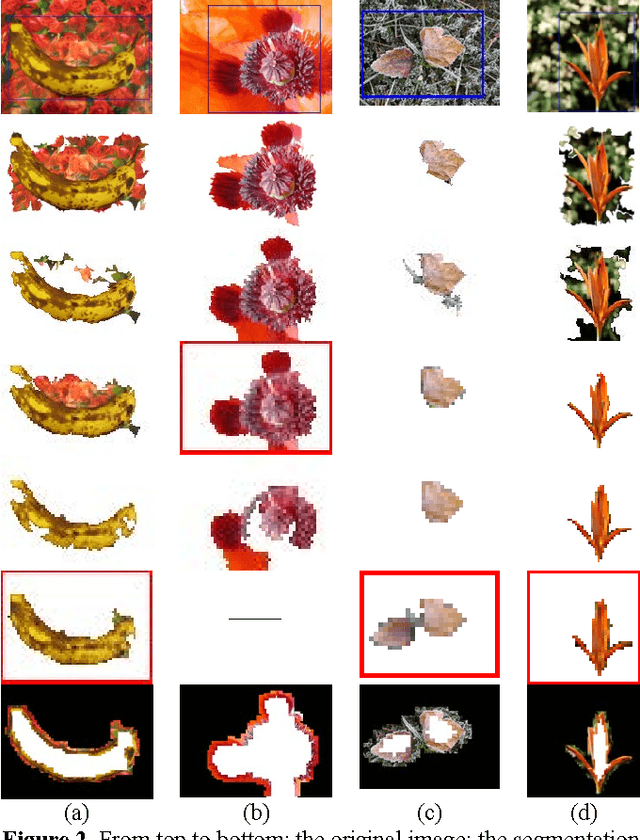

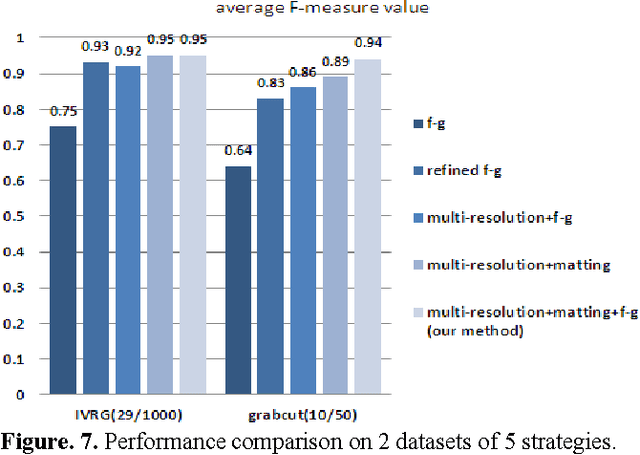
We propose a foreground segmentation algorithm that does foreground extraction under different scales and refines the result by matting. First, the input image is filtered and resampled to 5 different resolutions. Then each of them is segmented by adaptive figure-ground classification and the best segmentation is automatically selected by an evaluation score that maximizes the difference between foreground and background. This segmentation is upsampled to the original size, and a corresponding trimap is built. Closed-form matting is employed to label the boundary region, and the result is refined by a final figure-ground classification. Experiments show the success of our method in treating challenging images with cluttered background and adapting to loose initial bounding-box.