 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGVGS: Gaussian Visibility-Aware Multi-View Geometry for Accurate Surface Reconstruction
Jan 28, 20263D Gaussian Splatting enables efficient optimization and high-quality rendering, yet accurate surface reconstruction remains challenging. Prior methods improve surface reconstruction by refining Gaussian depth estimates, either via multi-view geometric consistency or through monocular depth priors. However, multi-view constraints become unreliable under large geometric discrepancies, while monocular priors suffer from scale ambiguity and local inconsistency, ultimately leading to inaccurate Gaussian depth supervision. To address these limitations, we introduce a Gaussian visibility-aware multi-view geometric consistency constraint that aggregates the visibility of shared Gaussian primitives across views, enabling more accurate and stable geometric supervision. In addition, we propose a progressive quadtree-calibrated Monocular depth constraint that performs block-wise affine calibration from coarse to fine spatial scales, mitigating the scale ambiguity of depth priors while preserving fine-grained surface details. Extensive experiments on DTU and TNT datasets demonstrate consistent improvements in geometric accuracy over prior Gaussian-based and implicit surface reconstruction methods. Codes are available at an anonymous repository: https://github.com/GVGScode/GVGS.
Neural Cone Radiosity for Interactive Global Illumination with Glossy Materials
Sep 09, 2025Modeling of high-frequency outgoing radiance distributions has long been a key challenge in rendering, particularly for glossy material. Such distributions concentrate radiative energy within a narrow lobe and are highly sensitive to changes in view direction. However, existing neural radiosity methods, which primarily rely on positional feature encoding, exhibit notable limitations in capturing these high-frequency, strongly view-dependent radiance distributions. To address this, we propose a highly-efficient approach by reflectance-aware ray cone encoding based on the neural radiosity framework, named neural cone radiosity. The core idea is to employ a pre-filtered multi-resolution hash grid to accurately approximate the glossy BSDF lobe, embedding view-dependent reflectance characteristics directly into the encoding process through continuous spatial aggregation. Our design not only significantly improves the network's ability to model high-frequency reflection distributions but also effectively handles surfaces with a wide range of glossiness levels, from highly glossy to low-gloss finishes. Meanwhile, our method reduces the network's burden in fitting complex radiance distributions, allowing the overall architecture to remain compact and efficient. Comprehensive experimental results demonstrate that our method consistently produces high-quality, noise-free renderings in real time under various glossiness conditions, and delivers superior fidelity and realism compared to baseline approaches.
Vertex Features for Neural Global Illumination
Aug 11, 2025Recent research on learnable neural representations has been widely adopted in the field of 3D scene reconstruction and neural rendering applications. However, traditional feature grid representations often suffer from substantial memory footprint, posing a significant bottleneck for modern parallel computing hardware. In this paper, we present neural vertex features, a generalized formulation of learnable representation for neural rendering tasks involving explicit mesh surfaces. Instead of uniformly distributing neural features throughout 3D space, our method stores learnable features directly at mesh vertices, leveraging the underlying geometry as a compact and structured representation for neural processing. This not only optimizes memory efficiency, but also improves feature representation by aligning compactly with the surface using task-specific geometric priors. We validate our neural representation across diverse neural rendering tasks, with a specific emphasis on neural radiosity. Experimental results demonstrate that our method reduces memory consumption to only one-fifth (or even less) of grid-based representations, while maintaining comparable rendering quality and lowering inference overhead.
SAIP-Net: Enhancing Remote Sensing Image Segmentation via Spectral Adaptive Information Propagation
Apr 23, 2025



Semantic segmentation of remote sensing imagery demands precise spatial boundaries and robust intra-class consistency, challenging conventional hierarchical models. To address limitations arising from spatial domain feature fusion and insufficient receptive fields, this paper introduces SAIP-Net, a novel frequency-aware segmentation framework that leverages Spectral Adaptive Information Propagation. SAIP-Net employs adaptive frequency filtering and multi-scale receptive field enhancement to effectively suppress intra-class feature inconsistencies and sharpen boundary lines. Comprehensive experiments demonstrate significant performance improvements over state-of-the-art methods, highlighting the effectiveness of spectral-adaptive strategies combined with expanded receptive fields for remote sensing image segmentation.
HUG: Hierarchical Urban Gaussian Splatting with Block-Based Reconstruction
Apr 23, 2025As urban 3D scenes become increasingly complex and the demand for high-quality rendering grows, efficient scene reconstruction and rendering techniques become crucial. We present HUG, a novel approach to address inefficiencies in handling large-scale urban environments and intricate details based on 3D Gaussian splatting. Our method optimizes data partitioning and the reconstruction pipeline by incorporating a hierarchical neural Gaussian representation. We employ an enhanced block-based reconstruction pipeline focusing on improving reconstruction quality within each block and reducing the need for redundant training regions around block boundaries. By integrating neural Gaussian representation with a hierarchical architecture, we achieve high-quality scene rendering at a low computational cost. This is demonstrated by our state-of-the-art results on public benchmarks, which prove the effectiveness and advantages in large-scale urban scene representation.
The Role of Machine Learning in Reducing Healthcare Costs: The Impact of Medication Adherence and Preventive Care on Hospitalization Expenses
Apr 10, 2025This study reveals the important role of prevention care and medication adherence in reducing hospitalizations. By using a structured dataset of 1,171 patients, four machine learning models Logistic Regression, Gradient Boosting, Random Forest, and Artificial Neural Networks are applied to predict five-year hospitalization risk, with the Gradient Boosting model achieving the highest accuracy of 81.2%. The result demonstrated that patients with high medication adherence and consistent preventive care can reduce 38.3% and 37.7% in hospitalization risk. The finding also suggests that targeted preventive care can have positive Return on Investment (ROI), and therefore ML models can effectively direct personalized interventions and contribute to long-term medical savings.
AA-RMVSNet: Adaptive Aggregation Recurrent Multi-view Stereo Network
Aug 09, 2021
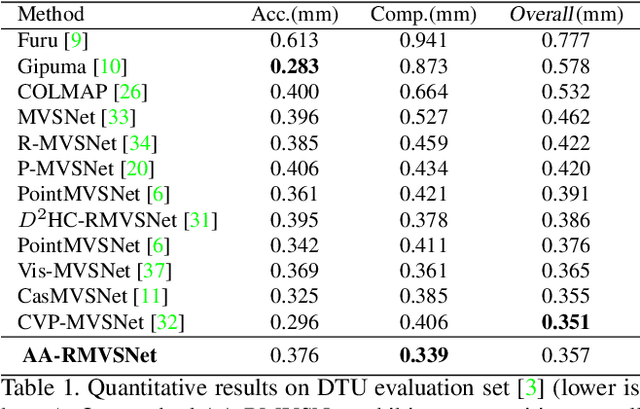
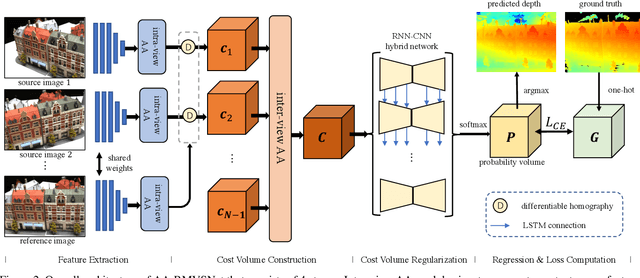
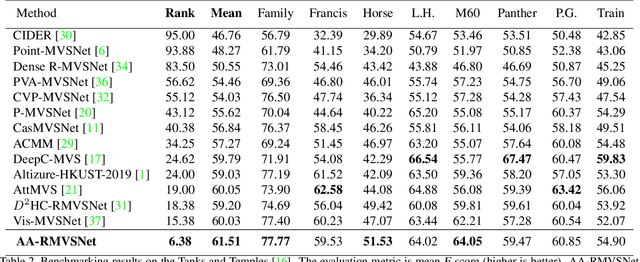
In this paper, we present a novel recurrent multi-view stereo network based on long short-term memory (LSTM) with adaptive aggregation, namely AA-RMVSNet. We firstly introduce an intra-view aggregation module to adaptively extract image features by using context-aware convolution and multi-scale aggregation, which efficiently improves the performance on challenging regions, such as thin objects and large low-textured surfaces. To overcome the difficulty of varying occlusion in complex scenes, we propose an inter-view cost volume aggregation module for adaptive pixel-wise view aggregation, which is able to preserve better-matched pairs among all views. The two proposed adaptive aggregation modules are lightweight, effective and complementary regarding improving the accuracy and completeness of 3D reconstruction. Instead of conventional 3D CNNs, we utilize a hybrid network with recurrent structure for cost volume regularization, which allows high-resolution reconstruction and finer hypothetical plane sweep. The proposed network is trained end-to-end and achieves excellent performance on various datasets. It ranks $1^{st}$ among all submissions on Tanks and Temples benchmark and achieves competitive results on DTU dataset, which exhibits strong generalizability and robustness. Implementation of our method is available at https://github.com/QT-Zhu/AA-RMVSNet.
Dense Hybrid Recurrent Multi-view Stereo Net with Dynamic Consistency Checking
Jul 21, 2020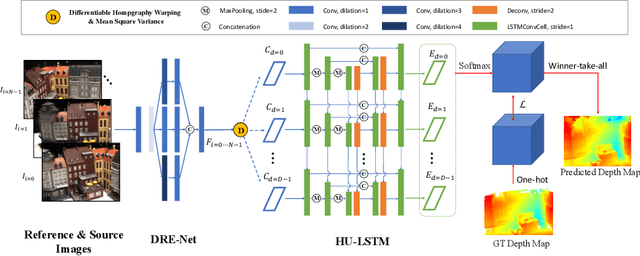
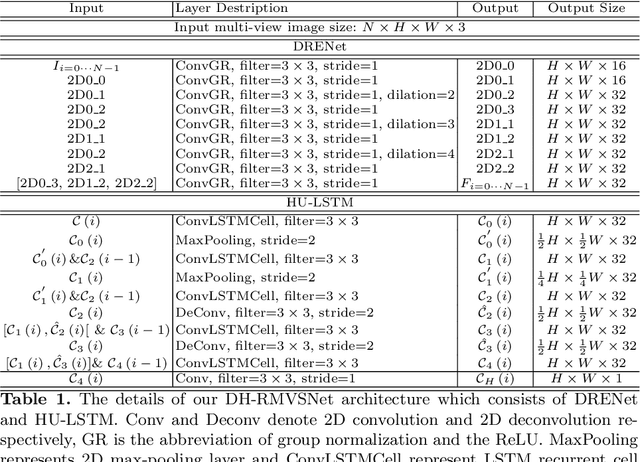
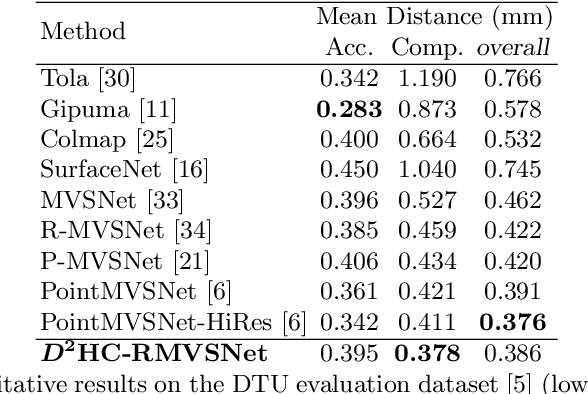

In this paper, we propose an efficient and effective dense hybrid recurrent multi-view stereo net with dynamic consistency checking, namely $D^{2}$HC-RMVSNet, for accurate dense point cloud reconstruction. Our novel hybrid recurrent multi-view stereo net consists of two core modules: 1) a light DRENet (Dense Reception Expanded) module to extract dense feature maps of original size with multi-scale context information, 2) a HU-LSTM (Hybrid U-LSTM) to regularize 3D matching volume into predicted depth map, which efficiently aggregates different scale information by coupling LSTM and U-Net architecture. To further improve the accuracy and completeness of reconstructed point clouds, we leverage a dynamic consistency checking strategy instead of prefixed parameters and strategies widely adopted in existing methods for dense point cloud reconstruction. In doing so, we dynamically aggregate geometric consistency matching error among all the views. Our method ranks \textbf{$1^{st}$} on the complex outdoor \textsl{Tanks and Temples} benchmark over all the methods. Extensive experiments on the in-door DTU dataset show our method exhibits competitive performance to the state-of-the-art method while dramatically reduces memory consumption, which costs only $19.4\%$ of R-MVSNet memory consumption. The codebase is available at \hyperlink{https://github.com/yhw-yhw/D2HC-RMVSNet}{https://github.com/yhw-yhw/D2HC-RMVSNet}.
* Accepted by ECCV2020 as Spotlight
Graph-Based Parallel Large Scale Structure from Motion
Dec 23, 2019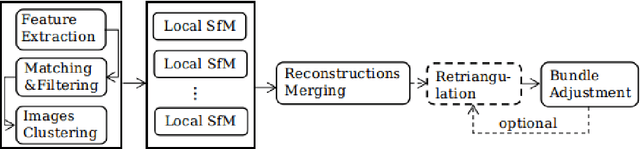
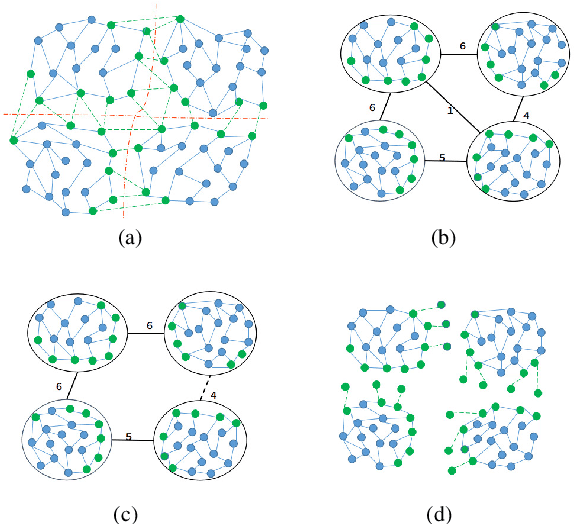
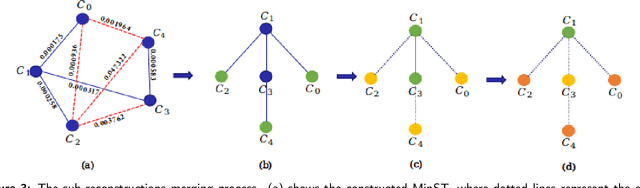

While Structure from Motion (SfM) achieves great success in 3D reconstruction, it still meets challenges on large scale scenes. In this work, large scale SfM is deemed as a graph problem, and we tackle it in a divide-and-conquer manner. Firstly, the images clustering algorithm divides images into clusters with strong connectivity, leading to robust local reconstructions. Then followed with an image expansion step, the connection and completeness of scenes are enhanced by expanding along with a maximum spanning tree. After local reconstructions, we construct a minimum spanning tree (MinST) to find accurate similarity transformations. Then the MinST is transformed into a Minimum Height Tree (MHT) to find a proper anchor node and is further utilized to prevent error accumulation. When evaluated on different kinds of datasets, our approach shows superiority over the state-of-the-art in accuracy and efficiency. Our algorithm is open-sourced at https://github.com/AIBluefisher/GraphSfM.
Bundle Adjustment Revisited
Dec 09, 2019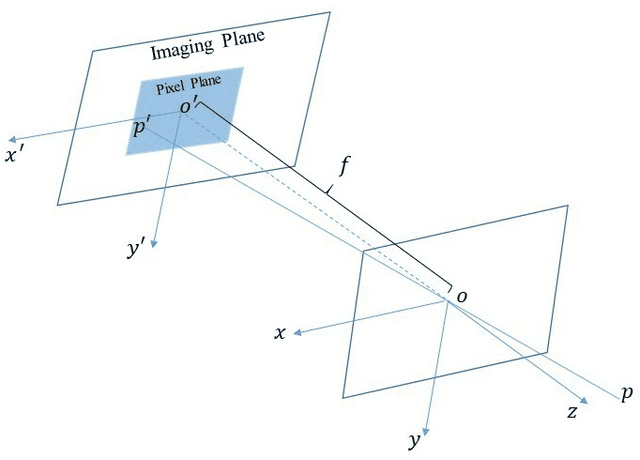
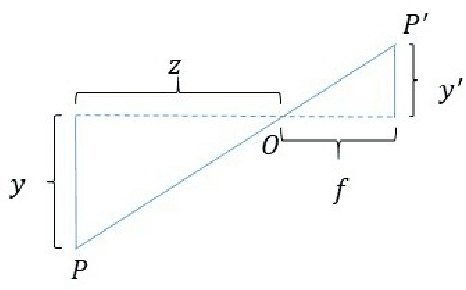


3D reconstruction has been developing all these two decades, from moderate to medium size and to large scale. It's well known that bundle adjustment plays an important role in 3D reconstruction, mainly in Structure from Motion(SfM) and Simultaneously Localization and Mapping(SLAM). While bundle adjustment optimizes camera parameters and 3D points as a non-negligible final step, it suffers from memory and efficiency requirements in very large scale reconstruction. In this paper, we study the development of bundle adjustment elaborately in both conventional and distributed approaches. The detailed derivation and pseudo code are also given in this paper.