 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid Multi-view Stereo Net with Self-adaptive View Aggregation
Paper and Code

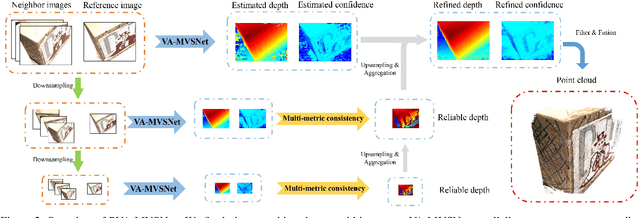
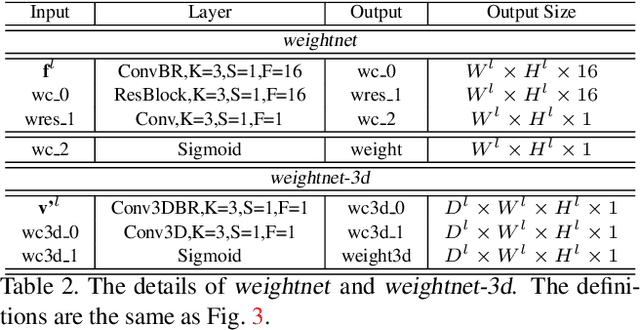
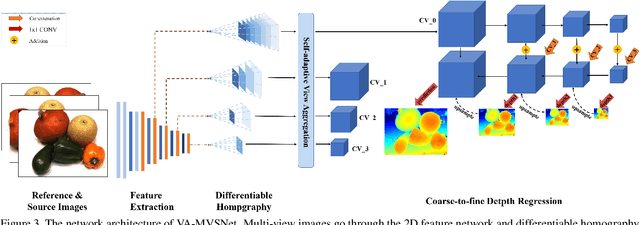
In this paper, we propose an effective and efficient pyramid multi-view stereo (MVS) net for accurate and complete dense point cloud reconstruction. Different from existing deep-learning based MVS methods, our VA-MVSNet incorporates the cost variance between different views by introducing two novel self-adaptive view aggregation: pixel-wise view aggregation and voxel-wise view aggregation. Moreover, to enhance the point cloud reconstruction on the texture-less regions, we extend VA-MVSNet with pyramid multi-scale images input as PVA-MVSNet, where multi-metric constraints are leveraged to aggregate the reliable depth estimation at the coarser scale to fill-in the mismatched regions at the finer scale. Experimental results show that our approach establishes a new state-of-the-art on the DTU dataset with significant improvements in the completeness and overall quality of 3D reconstruction, and ranks 1st on the Tanks and Temples benchmark among all published deep-learning based methods. Our codebase is available at https://github.com/yhw-yhw/PVAMVSNet.