 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceMind++: Toward Allocentric Cognitive Maps for Spatially Grounded Video MLLMs
May 10, 2026Recent multimodal large language models (MLLMs) have made remarkable progress in visual understanding and language-based reasoning, yet they lack a persistent world-centered representation for spatially consistent reasoning in 3D environments. Inspired by the mammalian dual-stream system, where semantic and spatial cues are processed separately and integrated into an allocentric cognitive map, we propose SpaceMind++, a video MLLM architecture that explicitly builds a voxelized cognitive map from RGB videos. This map reorganizes fragmented egocentric observations into a shared 3D metric representation, enabling the model to preserve object permanence and spatial topology across changing viewpoints. To make this allocentric representation usable by a pretrained video MLLM without disrupting its native visual-token interface, we introduce Coordinate-Guided Deep Iterative Fusion, a new mechanism that relays map-level spatial knowledge back into the original 2D visual features. This fusion is explicitly guided by coordinate embeddings and 3D Rotary Positional Encoding, which ground semantic interactions in metric 3D space, resembling the entorhinal binding of sensory features to metric space. Extensive experiments show that SpaceMind++ achieves new state-of-the-art performance on VSI-Bench. Furthermore, it demonstrates superior out-of-distribution generalization on SPBench, SITE-Bench, and SPAR-Bench, underscoring its robustness in unseen 3D environments.
Clinical-Prior Guided Multi-Modal Learning with Latent Attention Pooling for Gait-Based Scoliosis Screening
Feb 06, 2026Adolescent Idiopathic Scoliosis (AIS) is a prevalent spinal deformity whose progression can be mitigated through early detection. Conventional screening methods are often subjective, difficult to scale, and reliant on specialized clinical expertise. Video-based gait analysis offers a promising alternative, but current datasets and methods frequently suffer from data leakage, where performance is inflated by repeated clips from the same individual, or employ oversimplified models that lack clinical interpretability. To address these limitations, we introduce ScoliGait, a new benchmark dataset comprising 1,572 gait video clips for training and 300 fully independent clips for testing. Each clip is annotated with radiographic Cobb angles and descriptive text based on clinical kinematic priors. We propose a multi-modal framework that integrates a clinical-prior-guided kinematic knowledge map for interpretable feature representation, alongside a latent attention pooling mechanism to fuse video, text, and knowledge map modalities. Our method establishes a new state-of-the-art, demonstrating a significant performance gap on a realistic, non-repeating subject benchmark. Our approach establishes a new state of the art, showing a significant performance gain on a realistic, subject-independent benchmark. This work provides a robust, interpretable, and clinically grounded foundation for scalable, non-invasive AIS assessment.
Token Entropy Regularization for Multi-modal Antenna Affiliation Identification
Jan 29, 2026Accurate antenna affiliation identification is crucial for optimizing and maintaining communication networks. Current practice, however, relies on the cumbersome and error-prone process of manual tower inspections. We propose a novel paradigm shift that fuses video footage of base stations, antenna geometric features, and Physical Cell Identity (PCI) signals, transforming antenna affiliation identification into multi-modal classification and matching tasks. Publicly available pretrained transformers struggle with this unique task due to a lack of analogous data in the communications domain, which hampers cross-modal alignment. To address this, we introduce a dedicated training framework that aligns antenna images with corresponding PCI signals. To tackle the representation alignment challenge, we propose a novel Token Entropy Regularization module in the pretraining stage. Our experiments demonstrate that TER accelerates convergence and yields significant performance gains. Further analysis reveals that the entropy of the first token is modality-dependent. Code will be made available upon publication.
RPBG: Towards Robust Neural Point-based Graphics in the Wild
May 09, 2024
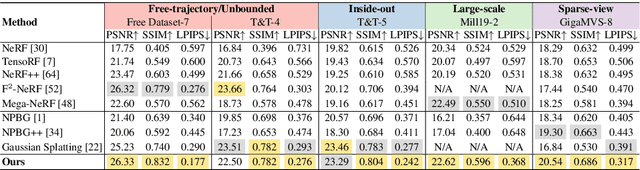

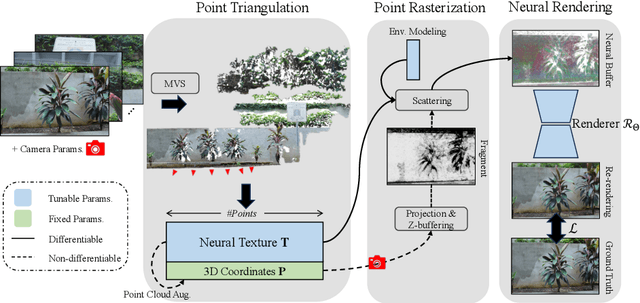
Point-based representations have recently gained popularity in novel view synthesis, for their unique advantages, e.g., intuitive geometric representation, simple manipulation, and faster convergence. However, based on our observation, these point-based neural re-rendering methods are only expected to perform well under ideal conditions and suffer from noisy, patchy points and unbounded scenes, which are challenging to handle but defacto common in real applications. To this end, we revisit one such influential method, known as Neural Point-based Graphics (NPBG), as our baseline, and propose Robust Point-based Graphics (RPBG). We in-depth analyze the factors that prevent NPBG from achieving satisfactory renderings on generic datasets, and accordingly reform the pipeline to make it more robust to varying datasets in-the-wild. Inspired by the practices in image restoration, we greatly enhance the neural renderer to enable the attention-based correction of point visibility and the inpainting of incomplete rasterization, with only acceptable overheads. We also seek for a simple and lightweight alternative for environment modeling and an iterative method to alleviate the problem of poor geometry. By thorough evaluation on a wide range of datasets with different shooting conditions and camera trajectories, RPBG stably outperforms the baseline by a large margin, and exhibits its great robustness over state-of-the-art NeRF-based variants. Code available at https://github.com/QT-Zhu/RPBG.
AA-RMVSNet: Adaptive Aggregation Recurrent Multi-view Stereo Network
Aug 09, 2021
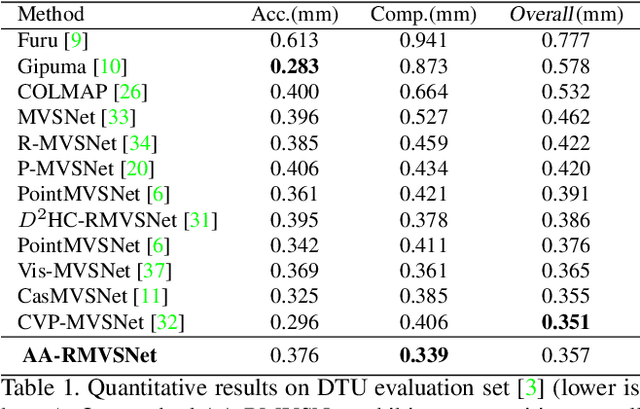
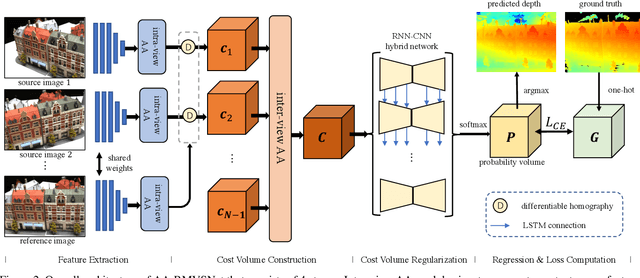
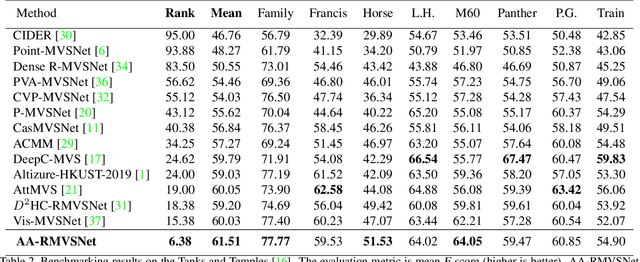
In this paper, we present a novel recurrent multi-view stereo network based on long short-term memory (LSTM) with adaptive aggregation, namely AA-RMVSNet. We firstly introduce an intra-view aggregation module to adaptively extract image features by using context-aware convolution and multi-scale aggregation, which efficiently improves the performance on challenging regions, such as thin objects and large low-textured surfaces. To overcome the difficulty of varying occlusion in complex scenes, we propose an inter-view cost volume aggregation module for adaptive pixel-wise view aggregation, which is able to preserve better-matched pairs among all views. The two proposed adaptive aggregation modules are lightweight, effective and complementary regarding improving the accuracy and completeness of 3D reconstruction. Instead of conventional 3D CNNs, we utilize a hybrid network with recurrent structure for cost volume regularization, which allows high-resolution reconstruction and finer hypothetical plane sweep. The proposed network is trained end-to-end and achieves excellent performance on various datasets. It ranks $1^{st}$ among all submissions on Tanks and Temples benchmark and achieves competitive results on DTU dataset, which exhibits strong generalizability and robustness. Implementation of our method is available at https://github.com/QT-Zhu/AA-RMVSNet.
Dense Hybrid Recurrent Multi-view Stereo Net with Dynamic Consistency Checking
Jul 21, 2020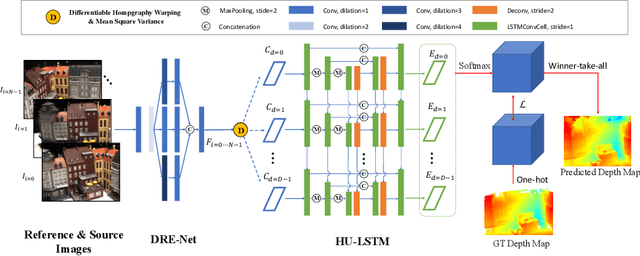
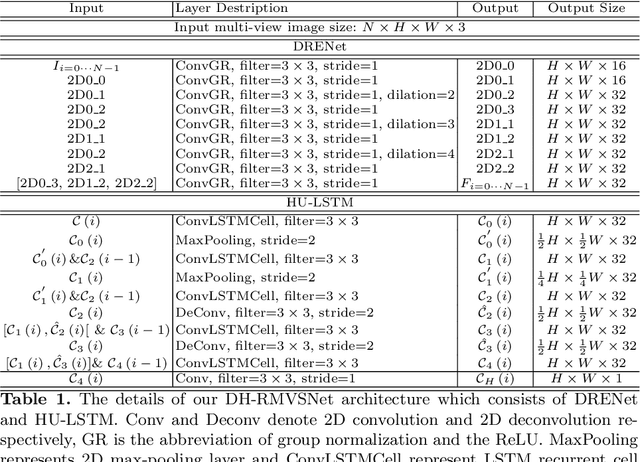
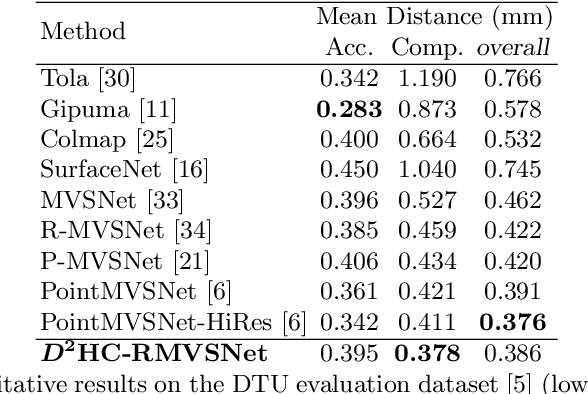

In this paper, we propose an efficient and effective dense hybrid recurrent multi-view stereo net with dynamic consistency checking, namely $D^{2}$HC-RMVSNet, for accurate dense point cloud reconstruction. Our novel hybrid recurrent multi-view stereo net consists of two core modules: 1) a light DRENet (Dense Reception Expanded) module to extract dense feature maps of original size with multi-scale context information, 2) a HU-LSTM (Hybrid U-LSTM) to regularize 3D matching volume into predicted depth map, which efficiently aggregates different scale information by coupling LSTM and U-Net architecture. To further improve the accuracy and completeness of reconstructed point clouds, we leverage a dynamic consistency checking strategy instead of prefixed parameters and strategies widely adopted in existing methods for dense point cloud reconstruction. In doing so, we dynamically aggregate geometric consistency matching error among all the views. Our method ranks \textbf{$1^{st}$} on the complex outdoor \textsl{Tanks and Temples} benchmark over all the methods. Extensive experiments on the in-door DTU dataset show our method exhibits competitive performance to the state-of-the-art method while dramatically reduces memory consumption, which costs only $19.4\%$ of R-MVSNet memory consumption. The codebase is available at \hyperlink{https://github.com/yhw-yhw/D2HC-RMVSNet}{https://github.com/yhw-yhw/D2HC-RMVSNet}.
* Accepted by ECCV2020 as Spotlight
Pyramid Multi-view Stereo Net with Self-adaptive View Aggregation
Dec 06, 2019
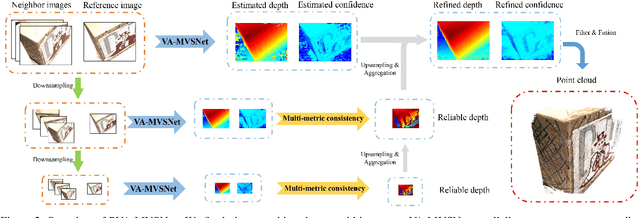
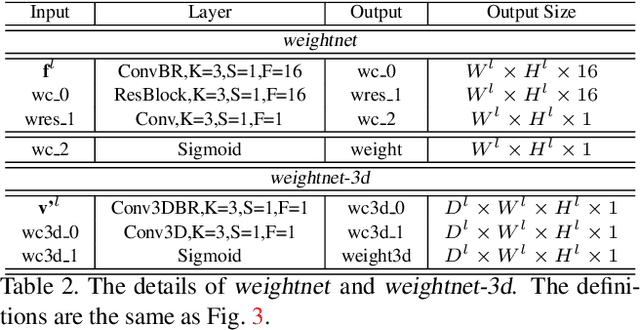
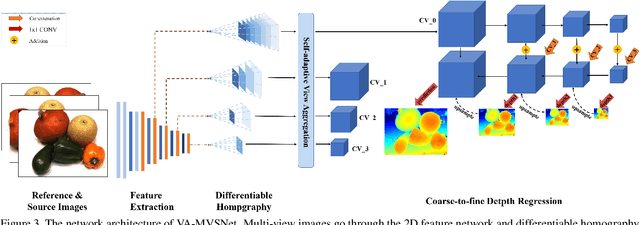
In this paper, we propose an effective and efficient pyramid multi-view stereo (MVS) net for accurate and complete dense point cloud reconstruction. Different from existing deep-learning based MVS methods, our VA-MVSNet incorporates the cost variance between different views by introducing two novel self-adaptive view aggregation: pixel-wise view aggregation and voxel-wise view aggregation. Moreover, to enhance the point cloud reconstruction on the texture-less regions, we extend VA-MVSNet with pyramid multi-scale images input as PVA-MVSNet, where multi-metric constraints are leveraged to aggregate the reliable depth estimation at the coarser scale to fill-in the mismatched regions at the finer scale. Experimental results show that our approach establishes a new state-of-the-art on the DTU dataset with significant improvements in the completeness and overall quality of 3D reconstruction, and ranks 1st on the Tanks and Temples benchmark among all published deep-learning based methods. Our codebase is available at https://github.com/yhw-yhw/PVAMVSNet.