 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaoLRM: Repurposing Pre-trained Large Reconstruction Models for Parametric 3D Face Reconstruction
Jan 19, 2026We propose KaoLRM to re-target the learned prior of the Large Reconstruction Model (LRM) for parametric 3D face reconstruction from single-view images. Parametric 3D Morphable Models (3DMMs) have been widely used for facial reconstruction due to their compact and interpretable parameterization, yet existing 3DMM regressors often exhibit poor consistency across varying viewpoints. To address this, we harness the pre-trained 3D prior of LRM and incorporate FLAME-based 2D Gaussian Splatting into LRM's rendering pipeline. Specifically, KaoLRM projects LRM's pre-trained triplane features into the FLAME parameter space to recover geometry, and models appearance via 2D Gaussian primitives that are tightly coupled to the FLAME mesh. The rich prior enables the FLAME regressor to be aware of the 3D structure, leading to accurate and robust reconstructions under self-occlusions and diverse viewpoints. Experiments on both controlled and in-the-wild benchmarks demonstrate that KaoLRM achieves superior reconstruction accuracy and cross-view consistency, while existing methods remain sensitive to viewpoint variations. The code is released at https://github.com/CyberAgentAILab/KaoLRM.
AniCrafter: Customizing Realistic Human-Centric Animation via Avatar-Background Conditioning in Video Diffusion Models
May 26, 2025Recent advances in video diffusion models have significantly improved character animation techniques. However, current approaches rely on basic structural conditions such as DWPose or SMPL-X to animate character images, limiting their effectiveness in open-domain scenarios with dynamic backgrounds or challenging human poses. In this paper, we introduce $\textbf{AniCrafter}$, a diffusion-based human-centric animation model that can seamlessly integrate and animate a given character into open-domain dynamic backgrounds while following given human motion sequences. Built on cutting-edge Image-to-Video (I2V) diffusion architectures, our model incorporates an innovative "avatar-background" conditioning mechanism that reframes open-domain human-centric animation as a restoration task, enabling more stable and versatile animation outputs. Experimental results demonstrate the superior performance of our method. Codes will be available at https://github.com/MyNiuuu/AniCrafter.
Tree-NeRV: A Tree-Structured Neural Representation for Efficient Non-Uniform Video Encoding
Apr 17, 2025Implicit Neural Representations for Videos (NeRV) have emerged as a powerful paradigm for video representation, enabling direct mappings from frame indices to video frames. However, existing NeRV-based methods do not fully exploit temporal redundancy, as they rely on uniform sampling along the temporal axis, leading to suboptimal rate-distortion (RD) performance. To address this limitation, we propose Tree-NeRV, a novel tree-structured feature representation for efficient and adaptive video encoding. Unlike conventional approaches, Tree-NeRV organizes feature representations within a Binary Search Tree (BST), enabling non-uniform sampling along the temporal axis. Additionally, we introduce an optimization-driven sampling strategy, dynamically allocating higher sampling density to regions with greater temporal variation. Extensive experiments demonstrate that Tree-NeRV achieves superior compression efficiency and reconstruction quality, outperforming prior uniform sampling-based methods. Code will be released.
R3-Avatar: Record and Retrieve Temporal Codebook for Reconstructing Photorealistic Human Avatars
Mar 17, 2025
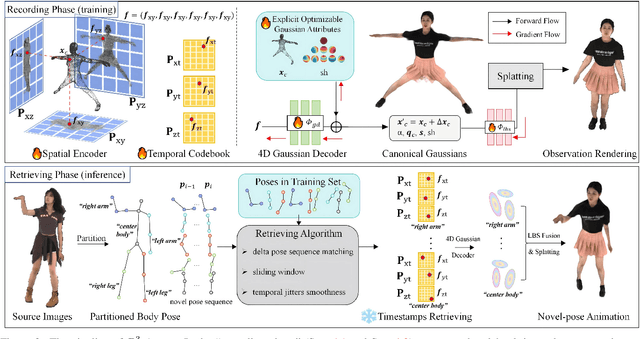
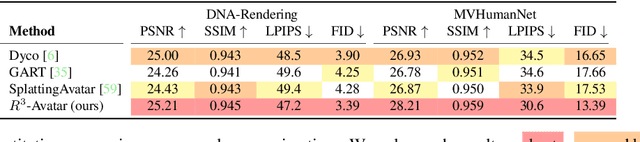

We present R3-Avatar, incorporating a temporal codebook, to overcome the inability of human avatars to be both animatable and of high-fidelity rendering quality. Existing video-based reconstruction of 3D human avatars either focuses solely on rendering, lacking animation support, or learns a pose-appearance mapping for animating, which degrades under limited training poses or complex clothing. In this paper, we adopt a "record-retrieve-reconstruct" strategy that ensures high-quality rendering from novel views while mitigating degradation in novel poses. Specifically, disambiguating timestamps record temporal appearance variations in a codebook, ensuring high-fidelity novel-view rendering, while novel poses retrieve corresponding timestamps by matching the most similar training poses for augmented appearance. Our R3-Avatar outperforms cutting-edge video-based human avatar reconstruction, particularly in overcoming visual quality degradation in extreme scenarios with limited training human poses and complex clothing.
Robustifying Fourier Features Embeddings for Implicit Neural Representations
Feb 08, 2025Implicit Neural Representations (INRs) employ neural networks to represent continuous functions by mapping coordinates to the corresponding values of the target function, with applications e.g., inverse graphics. However, INRs face a challenge known as spectral bias when dealing with scenes containing varying frequencies. To overcome spectral bias, the most common approach is the Fourier features-based methods such as positional encoding. However, Fourier features-based methods will introduce noise to output, which degrades their performances when applied to downstream tasks. In response, this paper initially hypothesizes that combining multi-layer perceptrons (MLPs) with Fourier feature embeddings mutually enhances their strengths, yet simultaneously introduces limitations inherent in Fourier feature embeddings. By presenting a simple theorem, we validate our hypothesis, which serves as a foundation for the design of our solution. Leveraging these insights, we propose the use of multi-layer perceptrons (MLPs) without additive
SUICA: Learning Super-high Dimensional Sparse Implicit Neural Representations for Spatial Transcriptomics
Dec 02, 2024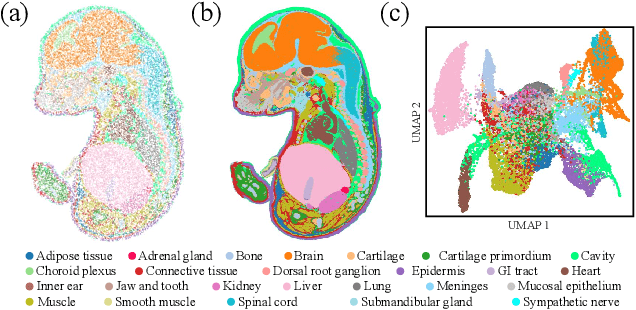
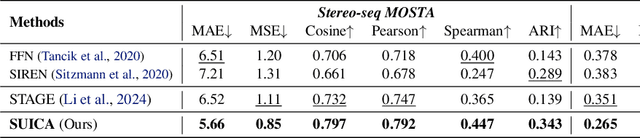
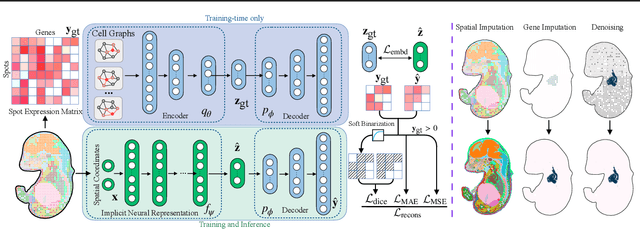

Spatial Transcriptomics (ST) is a method that captures spatial gene expression profiles within histological sections. The discrete spatial distribution and the super-high dimensional sequencing results make ST data challenging to be modeled effectively. In this paper, we manage to model ST in a continuous and compact manner by the proposed tool, SUICA, empowered by the great approximation capability of Implicit Neural Representations (INRs) that can improve both the spatial resolution and the gene expression. Concretely within the proposed SUICA, we incorporate a graph-augmented Autoencoder to effectively model the context information of the unstructured spots and provide informative embeddings that are structure-aware for spatial mapping. We also tackle the extremely skewed distribution in a regression-by-classification fashion and enforce classification-based loss functions for the optimization of SUICA. By extensive experiments of a wide range of common ST platforms, SUICA outperforms both conventional INR variants and SOTA methods for ST super-resolution regarding numerical fidelity, statistical correlation, and bio-conservation. The prediction by SUICA also showcases amplified gene signatures that enriches the bio-conservation of the raw data and benefits subsequent analysis. The code is available at https://github.com/Szym29/SUICA.
Bundle Adjusted Gaussian Avatars Deblurring
Nov 24, 2024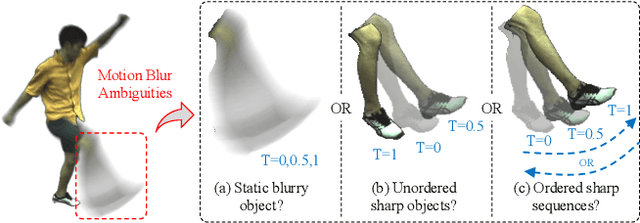
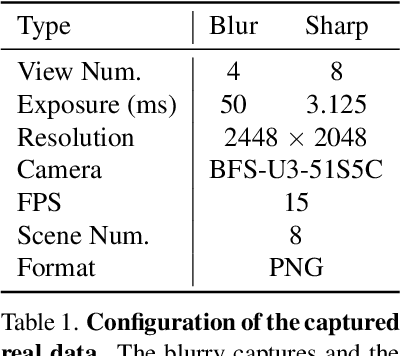
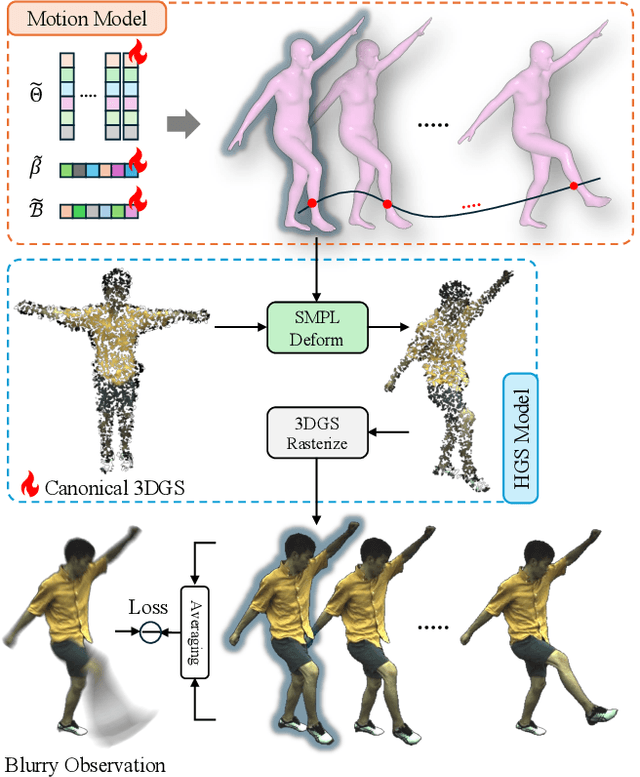
The development of 3D human avatars from multi-view videos represents a significant yet challenging task in the field. Recent advancements, including 3D Gaussian Splattings (3DGS), have markedly progressed this domain. Nonetheless, existing techniques necessitate the use of high-quality sharp images, which are often impractical to obtain in real-world settings due to variations in human motion speed and intensity. In this study, we attempt to explore deriving sharp intrinsic 3D human Gaussian avatars from blurry video footage in an end-to-end manner. Our approach encompasses a 3D-aware, physics-oriented model of blur formation attributable to human movement, coupled with a 3D human motion model to clarify ambiguities found in motion-induced blurry images. This methodology facilitates the concurrent learning of avatar model parameters and the refinement of sub-frame motion parameters from a coarse initialization. We have established benchmarks for this task through a synthetic dataset derived from existing multi-view captures, alongside a real-captured dataset acquired through a 360-degree synchronous hybrid-exposure camera system. Comprehensive evaluations demonstrate that our model surpasses existing baselines.
ToMiE: Towards Modular Growth in Enhanced SMPL Skeleton for 3D Human with Animatable Garments
Oct 10, 2024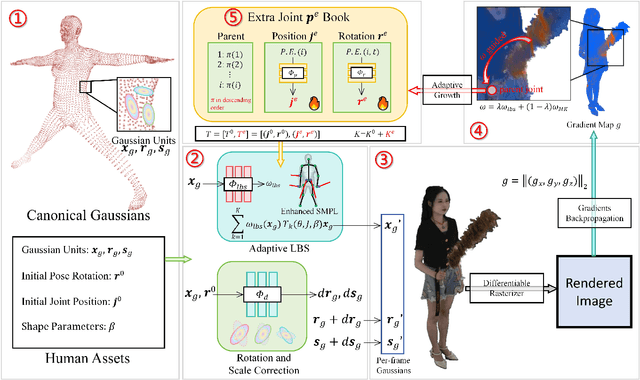
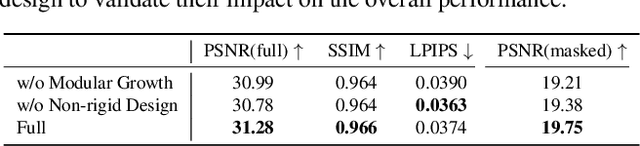
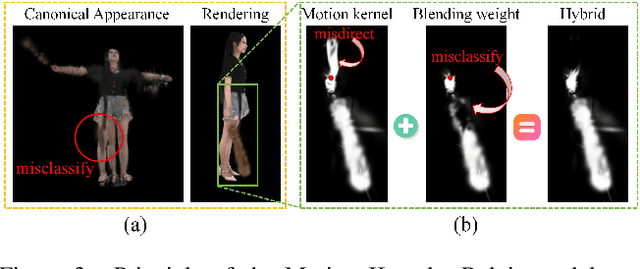

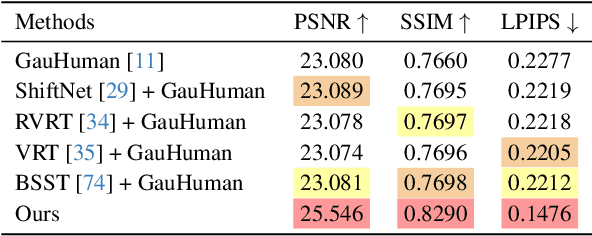
In this paper, we highlight a critical yet often overlooked factor in most 3D human tasks, namely modeling humans with complex garments. It is known that the parameterized formulation of SMPL is able to fit human skin; while complex garments, e.g., hand-held objects and loose-fitting garments, are difficult to get modeled within the unified framework, since their movements are usually decoupled with the human body. To enhance the capability of SMPL skeleton in response to this situation, we propose a modular growth strategy that enables the joint tree of the skeleton to expand adaptively. Specifically, our method, called ToMiE, consists of parent joints localization and external joints optimization. For parent joints localization, we employ a gradient-based approach guided by both LBS blending weights and motion kernels. Once the external joints are obtained, we proceed to optimize their transformations in SE(3) across different frames, enabling rendering and explicit animation. ToMiE manages to outperform other methods across various cases with garments, not only in rendering quality but also by offering free animation of grown joints, thereby enhancing the expressive ability of SMPL skeleton for a broader range of applications.
Autonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

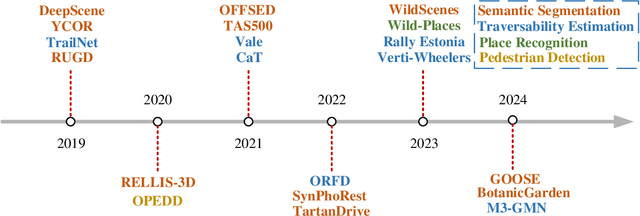

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
Learning-based Multi-View Stereo: A Survey
Aug 27, 2024



3D reconstruction aims to recover the dense 3D structure of a scene. It plays an essential role in various applications such as Augmented/Virtual Reality (AR/VR), autonomous driving and robotics. Leveraging multiple views of a scene captured from different viewpoints, Multi-View Stereo (MVS) algorithms synthesize a comprehensive 3D representation, enabling precise reconstruction in complex environments. Due to its efficiency and effectiveness, MVS has become a pivotal method for image-based 3D reconstruction. Recently, with the success of deep learning, many learning-based MVS methods have been proposed, achieving impressive performance against traditional methods. We categorize these learning-based methods as: depth map-based, voxel-based, NeRF-based, 3D Gaussian Splatting-based, and large feed-forward methods. Among these, we focus significantly on depth map-based methods, which are the main family of MVS due to their conciseness, flexibility and scalability. In this survey, we provide a comprehensive review of the literature at the time of this writing. We investigate these learning-based methods, summarize their performances on popular benchmarks, and discuss promising future research directions in this area.