 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Open-source World Models
Jan 28, 2026We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, LingBot-World offers the following features. (1) It maintains high fidelity and robust dynamics in a broad spectrum of environments, including realism, scientific contexts, cartoon styles, and beyond. (2) It enables a minute-level horizon while preserving contextual consistency over time, which is also known as "long-term memory". (3) It supports real-time interactivity, achieving a latency of under 1 second when producing 16 frames per second. We provide public access to the code and model in an effort to narrow the divide between open-source and closed-source technologies. We believe our release will empower the community with practical applications across areas like content creation, gaming, and robot learning.
The World is Your Canvas: Painting Promptable Events with Reference Images, Trajectories, and Text
Dec 18, 2025



We present WorldCanvas, a framework for promptable world events that enables rich, user-directed simulation by combining text, trajectories, and reference images. Unlike text-only approaches and existing trajectory-controlled image-to-video methods, our multimodal approach combines trajectories -- encoding motion, timing, and visibility -- with natural language for semantic intent and reference images for visual grounding of object identity, enabling the generation of coherent, controllable events that include multi-agent interactions, object entry/exit, reference-guided appearance and counterintuitive events. The resulting videos demonstrate not only temporal coherence but also emergent consistency, preserving object identity and scene despite temporary disappearance. By supporting expressive world events generation, WorldCanvas advances world models from passive predictors to interactive, user-shaped simulators. Our project page is available at: https://worldcanvas.github.io/.
HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives
Oct 23, 2025State-of-the-art text-to-video models excel at generating isolated clips but fall short of creating the coherent, multi-shot narratives, which are the essence of storytelling. We bridge this "narrative gap" with HoloCine, a model that generates entire scenes holistically to ensure global consistency from the first shot to the last. Our architecture achieves precise directorial control through a Window Cross-Attention mechanism that localizes text prompts to specific shots, while a Sparse Inter-Shot Self-Attention pattern (dense within shots but sparse between them) ensures the efficiency required for minute-scale generation. Beyond setting a new state-of-the-art in narrative coherence, HoloCine develops remarkable emergent abilities: a persistent memory for characters and scenes, and an intuitive grasp of cinematic techniques. Our work marks a pivotal shift from clip synthesis towards automated filmmaking, making end-to-end cinematic creation a tangible future. Our code is available at: https://holo-cine.github.io/.
CharacterShot: Controllable and Consistent 4D Character Animation
Aug 10, 2025In this paper, we propose \textbf{CharacterShot}, a controllable and consistent 4D character animation framework that enables any individual designer to create dynamic 3D characters (i.e., 4D character animation) from a single reference character image and a 2D pose sequence. We begin by pretraining a powerful 2D character animation model based on a cutting-edge DiT-based image-to-video model, which allows for any 2D pose sequnce as controllable signal. We then lift the animation model from 2D to 3D through introducing dual-attention module together with camera prior to generate multi-view videos with spatial-temporal and spatial-view consistency. Finally, we employ a novel neighbor-constrained 4D gaussian splatting optimization on these multi-view videos, resulting in continuous and stable 4D character representations. Moreover, to improve character-centric performance, we construct a large-scale dataset Character4D, containing 13,115 unique characters with diverse appearances and motions, rendered from multiple viewpoints. Extensive experiments on our newly constructed benchmark, CharacterBench, demonstrate that our approach outperforms current state-of-the-art methods. Code, models, and datasets will be publicly available at https://github.com/Jeoyal/CharacterShot.
AniCrafter: Customizing Realistic Human-Centric Animation via Avatar-Background Conditioning in Video Diffusion Models
May 26, 2025Recent advances in video diffusion models have significantly improved character animation techniques. However, current approaches rely on basic structural conditions such as DWPose or SMPL-X to animate character images, limiting their effectiveness in open-domain scenarios with dynamic backgrounds or challenging human poses. In this paper, we introduce $\textbf{AniCrafter}$, a diffusion-based human-centric animation model that can seamlessly integrate and animate a given character into open-domain dynamic backgrounds while following given human motion sequences. Built on cutting-edge Image-to-Video (I2V) diffusion architectures, our model incorporates an innovative "avatar-background" conditioning mechanism that reframes open-domain human-centric animation as a restoration task, enabling more stable and versatile animation outputs. Experimental results demonstrate the superior performance of our method. Codes will be available at https://github.com/MyNiuuu/AniCrafter.
PSDiffusion: Harmonized Multi-Layer Image Generation via Layout and Appearance Alignment
May 16, 2025



Diffusion models have made remarkable advancements in generating high-quality images from textual descriptions. Recent works like LayerDiffuse have extended the previous single-layer, unified image generation paradigm to transparent image layer generation. However, existing multi-layer generation methods fail to handle the interactions among multiple layers such as rational global layout, physics-plausible contacts and visual effects like shadows and reflections while maintaining high alpha quality. To solve this problem, we propose PSDiffusion, a unified diffusion framework for simultaneous multi-layer text-to-image generation. Our model can automatically generate multi-layer images with one RGB background and multiple RGBA foregrounds through a single feed-forward process. Unlike existing methods that combine multiple tools for post-decomposition or generate layers sequentially and separately, our method introduces a global-layer interactive mechanism that generates layered-images concurrently and collaboratively, ensuring not only high quality and completeness for each layer, but also spatial and visual interactions among layers for global coherence.
WORLDMEM: Long-term Consistent World Simulation with Memory
Apr 16, 2025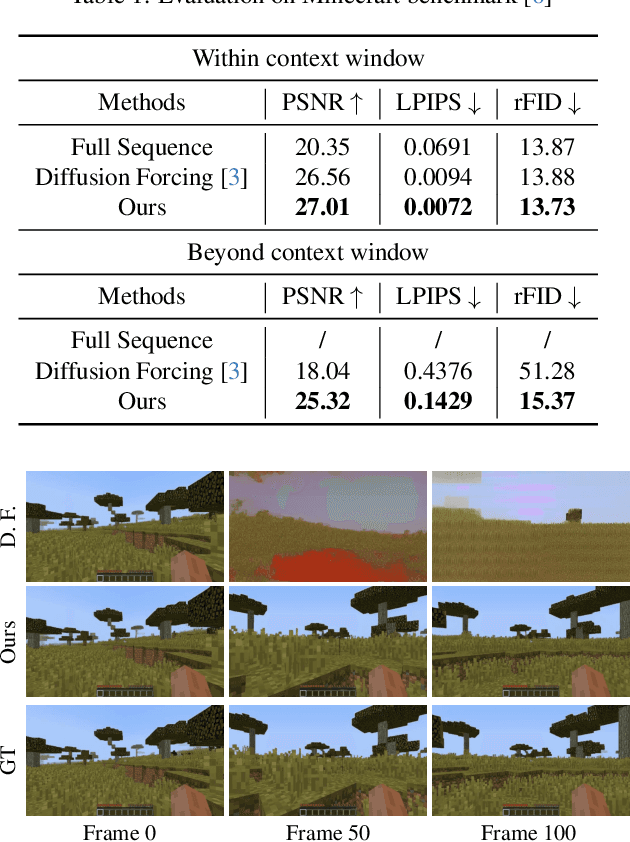
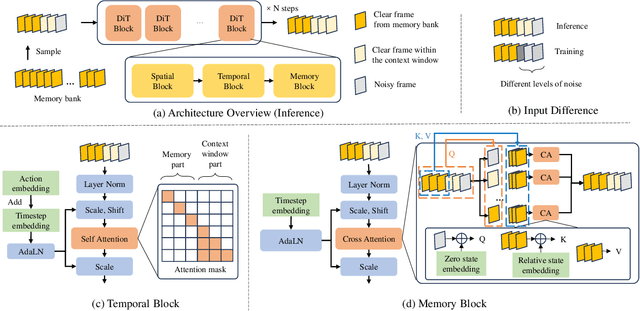
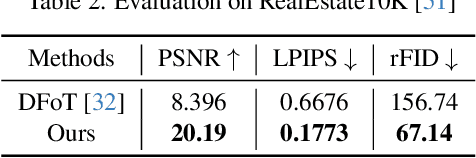
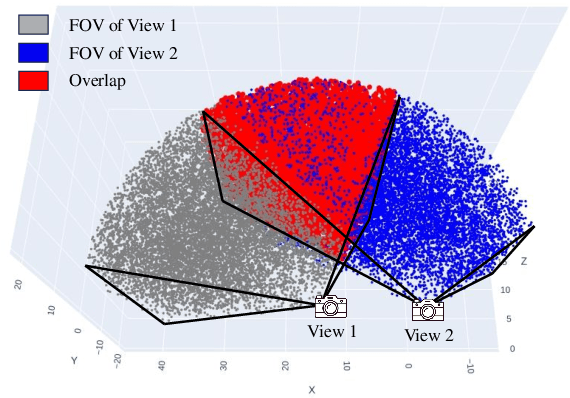
World simulation has gained increasing popularity due to its ability to model virtual environments and predict the consequences of actions. However, the limited temporal context window often leads to failures in maintaining long-term consistency, particularly in preserving 3D spatial consistency. In this work, we present WorldMem, a framework that enhances scene generation with a memory bank consisting of memory units that store memory frames and states (e.g., poses and timestamps). By employing a memory attention mechanism that effectively extracts relevant information from these memory frames based on their states, our method is capable of accurately reconstructing previously observed scenes, even under significant viewpoint or temporal gaps. Furthermore, by incorporating timestamps into the states, our framework not only models a static world but also captures its dynamic evolution over time, enabling both perception and interaction within the simulated world. Extensive experiments in both virtual and real scenarios validate the effectiveness of our approach.
Multi-identity Human Image Animation with Structural Video Diffusion
Apr 05, 2025Generating human videos from a single image while ensuring high visual quality and precise control is a challenging task, especially in complex scenarios involving multiple individuals and interactions with objects. Existing methods, while effective for single-human cases, often fail to handle the intricacies of multi-identity interactions because they struggle to associate the correct pairs of human appearance and pose condition and model the distribution of 3D-aware dynamics. To address these limitations, we present Structural Video Diffusion, a novel framework designed for generating realistic multi-human videos. Our approach introduces two core innovations: identity-specific embeddings to maintain consistent appearances across individuals and a structural learning mechanism that incorporates depth and surface-normal cues to model human-object interactions. Additionally, we expand existing human video dataset with 25K new videos featuring diverse multi-human and object interaction scenarios, providing a robust foundation for training. Experimental results demonstrate that Structural Video Diffusion achieves superior performance in generating lifelike, coherent videos for multiple subjects with dynamic and rich interactions, advancing the state of human-centric video generation.
LEGO-Puzzles: How Good Are MLLMs at Multi-Step Spatial Reasoning?
Mar 25, 2025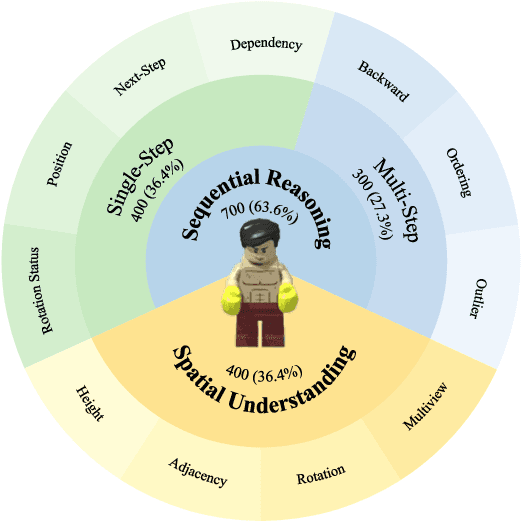
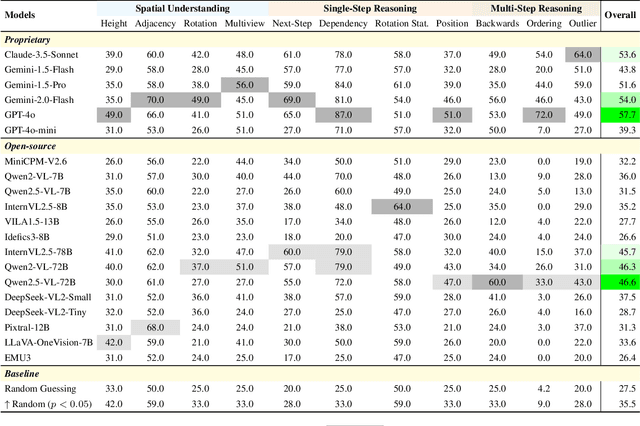
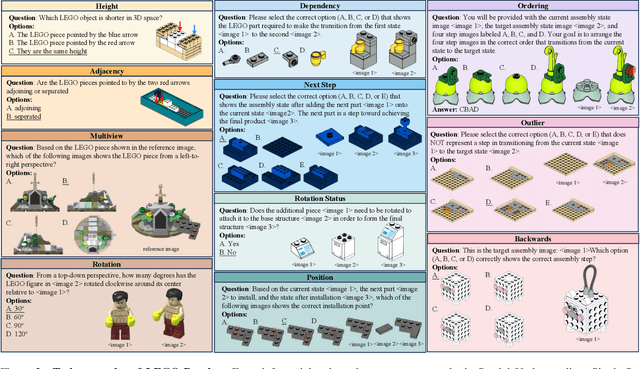
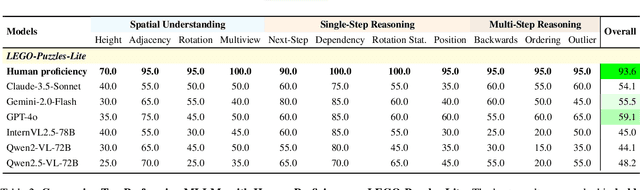
Multi-step spatial reasoning entails understanding and reasoning about spatial relationships across multiple sequential steps, which is crucial for tackling complex real-world applications, such as robotic manipulation, autonomous navigation, and automated assembly. To assess how well current Multimodal Large Language Models (MLLMs) have acquired this fundamental capability, we introduce \textbf{LEGO-Puzzles}, a scalable benchmark designed to evaluate both \textbf{spatial understanding} and \textbf{sequential reasoning} in MLLMs through LEGO-based tasks. LEGO-Puzzles consists of 1,100 carefully curated visual question-answering (VQA) samples spanning 11 distinct tasks, ranging from basic spatial understanding to complex multi-step reasoning. Based on LEGO-Puzzles, we conduct a comprehensive evaluation of state-of-the-art MLLMs and uncover significant limitations in their spatial reasoning capabilities: even the most powerful MLLMs can answer only about half of the test cases, whereas human participants achieve over 90\% accuracy. In addition to VQA tasks, we evaluate MLLMs' abilities to generate LEGO images following assembly illustrations. Our experiments show that only Gemini-2.0-Flash and GPT-4o exhibit a limited ability to follow these instructions, while other MLLMs either replicate the input image or generate completely irrelevant outputs. Overall, LEGO-Puzzles exposes critical deficiencies in existing MLLMs' spatial understanding and sequential reasoning capabilities, and underscores the need for further advancements in multimodal spatial reasoning.
DiffSensei: Bridging Multi-Modal LLMs and Diffusion Models for Customized Manga Generation
Dec 10, 2024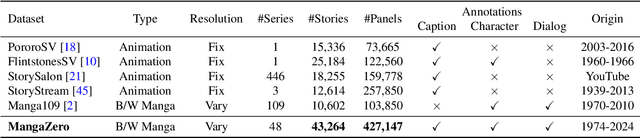

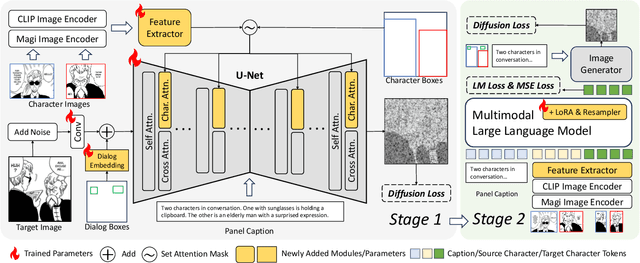
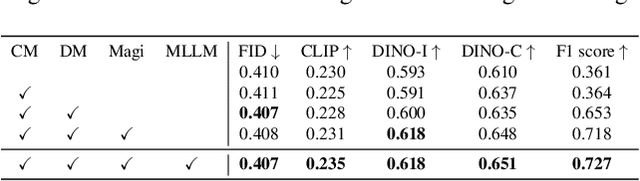
Story visualization, the task of creating visual narratives from textual descriptions, has seen progress with text-to-image generation models. However, these models often lack effective control over character appearances and interactions, particularly in multi-character scenes. To address these limitations, we propose a new task: \textbf{customized manga generation} and introduce \textbf{DiffSensei}, an innovative framework specifically designed for generating manga with dynamic multi-character control. DiffSensei integrates a diffusion-based image generator with a multimodal large language model (MLLM) that acts as a text-compatible identity adapter. Our approach employs masked cross-attention to seamlessly incorporate character features, enabling precise layout control without direct pixel transfer. Additionally, the MLLM-based adapter adjusts character features to align with panel-specific text cues, allowing flexible adjustments in character expressions, poses, and actions. We also introduce \textbf{MangaZero}, a large-scale dataset tailored to this task, containing 43,264 manga pages and 427,147 annotated panels, supporting the visualization of varied character interactions and movements across sequential frames. Extensive experiments demonstrate that DiffSensei outperforms existing models, marking a significant advancement in manga generation by enabling text-adaptable character customization. The project page is https://jianzongwu.github.io/projects/diffsensei/.