 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive2Diff: Live Stream Translation via Uni-directional Attention in Video Diffusion Models
Paper and Code
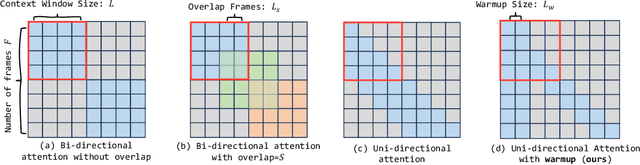
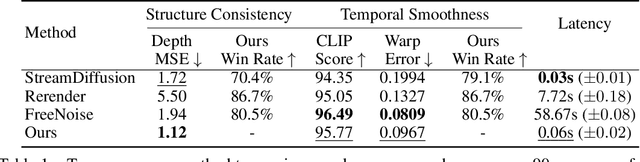
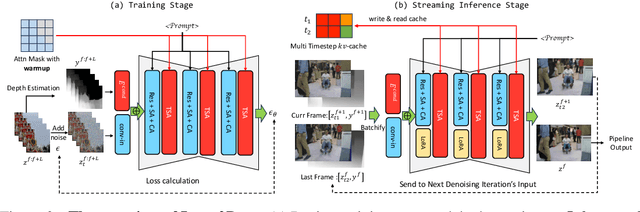
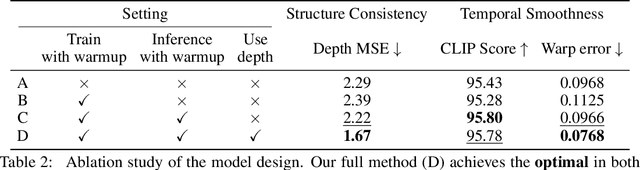
Large Language Models have shown remarkable efficacy in generating streaming data such as text and audio, thanks to their temporally uni-directional attention mechanism, which models correlations between the current token and previous tokens. However, video streaming remains much less explored, despite a growing need for live video processing. State-of-the-art video diffusion models leverage bi-directional temporal attention to model the correlations between the current frame and all the surrounding (i.e. including future) frames, which hinders them from processing streaming videos. To address this problem, we present Live2Diff, the first attempt at designing a video diffusion model with uni-directional temporal attention, specifically targeting live streaming video translation. Compared to previous works, our approach ensures temporal consistency and smoothness by correlating the current frame with its predecessors and a few initial warmup frames, without any future frames. Additionally, we use a highly efficient denoising scheme featuring a KV-cache mechanism and pipelining, to facilitate streaming video translation at interactive framerates. Extensive experiments demonstrate the effectiveness of the proposed attention mechanism and pipeline, outperforming previous methods in terms of temporal smoothness and/or efficiency.