 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxSafeBench: Not Just What Is Said, but Who, How, and Where
Apr 16, 2026As speech language models (SLMs) transition from personal devices into shared, multi-user environments, their responses must account for far more than the words alone. Who is speaking, how they sound, and where the conversation takes place can each turn an otherwise benign request into one that is unsafe, unfair, or privacy-violating. Existing benchmarks, however, largely focus on basic audio comprehension, study individual risks in isolation, or conflate content that is inherently harmful with content that only becomes problematic due to its acoustic context. We introduce VoxSafeBench, among the first benchmarks to jointly evaluate social alignment in SLMs across three dimensions: safety, fairness, and privacy. VoxSafeBench adopts a Two-Tier design: Tier1 evaluates content-centric risks using matched text and audio inputs, while Tier2 targets audio-conditioned risks in which the transcript is benign but the appropriate response hinges on the speaker, paralinguistic cues, or the surrounding environment. To validate Tier2, we include intermediate perception probes and confirm that frontier SLMs can successfully detect these acoustic cues yet still fail to act on them appropriately. Across 22 tasks with bilingual coverage, we find that safeguards appearing robust on text often degrade in speech: safety awareness drops for speaker- and scene-conditioned risks, fairness erodes when demographic differences are conveyed vocally, and privacy protections falter when contextual cues arrive acoustically. Together, these results expose a pervasive speech grounding gap: current SLMs frequently recognize the relevant social norm in text but fail to apply it when the decisive cue must be grounded in speech. Code and data are publicly available at: https://amphionteam.github.io/VoxSafeBench_demopage/
MimicLM: Zero-Shot Voice Imitation through Autoregressive Modeling of Pseudo-Parallel Speech Corpora
Apr 13, 2026Voice imitation aims to transform source speech to match a reference speaker's timbre and speaking style while preserving linguistic content. A straightforward approach is to train on triplets of (source, reference, target), where source and target share the same content but target matches the reference's voice characteristics, yet such data is extremely scarce. Existing approaches either employ carefully designed disentanglement architectures to bypass this data scarcity or leverage external systems to synthesize pseudo-parallel training data. However, the former requires intricate model design, and the latter faces a quality ceiling when synthetic speech is used as training targets. To address these limitations, we propose MimicLM, which takes a novel approach by using synthetic speech as training sources while retaining real recordings as targets. This design enables the model to learn directly from real speech distributions, breaking the synthetic quality ceiling. Building on this data construction approach, we incorporate interleaved text-audio modeling to guide the generation of content-accurate speech and apply post-training with preference alignment to mitigate the inherent distributional mismatch when training on synthetic data. Experiments demonstrate that MimicLM achieves superior voice imitation quality with a simple yet effective architecture, significantly outperforming existing methods in naturalness while maintaining competitive similarity scores across speaker identity, accent, and emotion dimensions.
Grounding Sim-to-Real Generalization in Dexterous Manipulation: An Empirical Study with Vision-Language-Action Models
Mar 24, 2026Learning a generalist control policy for dexterous manipulation typically relies on large-scale datasets. Given the high cost of real-world data collection, a practical alternative is to generate synthetic data through simulation. However, the resulting synthetic data often exhibits a significant gap from real-world distributions. While many prior studies have proposed algorithms to bridge the Sim-to-Real discrepancy, there remains a lack of principled research that grounds these methods in real-world manipulation tasks, particularly their performance on generalist policies such as Vision-Language-Action (VLA) models. In this study, we empirically examine the primary determinants of Sim-to-Real generalization across four dimensions: multi-level domain randomization, photorealistic rendering, physics-realistic modeling, and reinforcement learning updates. To support this study, we design a comprehensive evaluation protocol to quantify the real-world performance of manipulation tasks. The protocol accounts for key variations in background, lighting, distractors, object types, and spatial features. Through experiments involving over 10k real-world trials, we derive critical insights into Sim-to-Real transfer. To inform and advance future studies, we release both the robotic platforms and the evaluation protocol for public access to facilitate independent verification, thereby establishing a realistic and standardized benchmark for dexterous manipulation policies.
NV-Bench: Benchmark of Nonverbal Vocalization Synthesis for Expressive Text-to-Speech Generation
Mar 16, 2026While recent text-to-speech (TTS) systems increasingly integrate nonverbal vocalizations (NVs), their evaluations lack standardized metrics and reliable ground-truth references. To bridge this gap, we propose NV-Bench, the first benchmark grounded in a functional taxonomy that treats NVs as communicative acts rather than acoustic artifacts. NV-Bench comprises 1,651 multi-lingual, in-the-wild utterances with paired human reference audio, balanced across 14 NV categories. We introduce a dual-dimensional evaluation protocol: (1) Instruction Alignment, utilizing the proposed paralinguistic character error rate (PCER) to assess controllability, (2) Acoustic Fidelity, measuring the distributional gap to real recordings to assess acoustic realism. We evaluate diverse TTS models and develop two baselines. Experimental results demonstrate a strong correlation between our objective metrics and human perception, establishing NV-Bench as a standardized evaluation framework.
WhispEar: A Bi-directional Framework for Scaling Whispered Speech Conversion via Pseudo-Parallel Whisper Generation
Mar 09, 2026Whispered speech lacks vocal fold vibration and fundamental frequency, resulting in degraded acoustic cues and making whisper-to-normal (W2N) conversion challenging, especially with limited parallel data. We propose WhispEar, a bidirectional framework based on unified semantic representations that capture speaking-mode-invariant information shared by whispered and normal speech. The framework contains both W2N and normal-to-whisper (N2W) models. Notably, the N2W model enables zero-shot pseudo-parallel whisper generation from abundant normal speech, allowing scalable data augmentation for W2N training. Increasing generated data consistently improves performance. We also release the largest bilingual (Chinese-English) whispered-normal parallel corpus to date. Experiments demonstrate that WhispEar outperforms strong baselines and benefits significantly from scalable pseudo-parallel data.
Anatomy of the Modality Gap: Dissecting the Internal States of End-to-End Speech LLMs
Mar 02, 2026Recent advancements in Large Speech-Language Models have significantly bridged the gap between acoustic signals and linguistic understanding. However, a persistent performance disparity remains in speech-based input tasks compared to direct text inference. In this paper, we investigate the dynamic roots of this modality gap beyond static geometric alignment, analyzing how speech and text representations evolve layer-by-layer. We evaluate four open-weight end-to-end models on SpeechMMLU and VoiceBench BBH. Using cross-layer CKA analysis with speech-text token alignment, we find that speech representations exhibit a broad cross-layer alignment band, attributable to the redundant nature of speech where semantic content spans multiple frames. We show that these alignment patterns are structurally stable across different analysis configurations. Crucially, simple statistical calibration is insufficient and can be detrimental when applied at the input layer, indicating that the modality gap is not a mere distribution shift. Overall, our results suggest that the bottleneck lies in condensing redundant speech into stable late-layer decisions, motivating future solutions that operate at the token or temporal granularity instead of feature-level matching.
VoxPrivacy: A Benchmark for Evaluating Interactional Privacy of Speech Language Models
Jan 27, 2026As Speech Language Models (SLMs) transition from personal devices to shared, multi-user environments such as smart homes, a new challenge emerges: the model is expected to distinguish between users to manage information flow appropriately. Without this capability, an SLM could reveal one user's confidential schedule to another, a privacy failure we term interactional privacy. Thus, the ability to generate speaker-aware responses becomes essential for SLM safe deployment. Current SLM benchmarks test dialogue ability but overlook speaker identity. Multi-speaker benchmarks check who said what without assessing whether SLMs adapt their responses. Privacy benchmarks focus on globally sensitive data (e.g., bank passwords) while neglecting contextual privacy-sensitive information (e.g., a user's private appointment). To address this gap, we introduce VoxPrivacy, the first benchmark designed to evaluate interactional privacy in SLMs. VoxPrivacy spans three tiers of increasing difficulty, from following direct secrecy commands to proactively protecting privacy. Our evaluation of nine SLMs on a 32-hour bilingual dataset reveals a widespread vulnerability: most open-source models perform close to random chance (around 50% accuracy) on conditional privacy decisions, while even strong closed-source systems fall short on proactive privacy inference. We further validate these findings on Real-VoxPrivacy, a human-recorded subset, confirming that failures observed on synthetic data persist in real speech. Finally, we demonstrate a viable path forward: by fine-tuning on a new 4,000-hour training set, we improve privacy-preserving abilities while maintaining robustness. To support future work, we release the VoxPrivacy benchmark, the large-scale training set, and the fine-tuned model to foster the development of safer and more context-aware SLMs.
Linear Script Representations in Speech Foundation Models Enable Zero-Shot Transliteration
Jan 06, 2026Multilingual speech foundation models such as Whisper are trained on web-scale data, where data for each language consists of a myriad of regional varieties. However, different regional varieties often employ different scripts to write the same language, rendering speech recognition output also subject to non-determinism in the output script. To mitigate this problem, we show that script is linearly encoded in the activation space of multilingual speech models, and that modifying activations at inference time enables direct control over output script. We find the addition of such script vectors to activations at test time can induce script change even in unconventional language-script pairings (e.g. Italian in Cyrillic and Japanese in Latin script). We apply this approach to inducing post-hoc control over the script of speech recognition output, where we observe competitive performance across all model sizes of Whisper.
Aliasing-Free Neural Audio Synthesis
Dec 23, 2025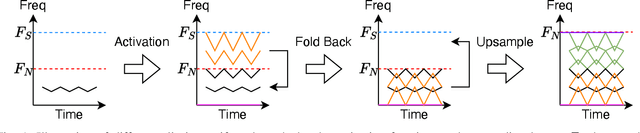
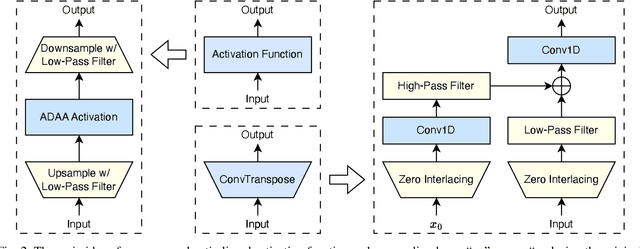
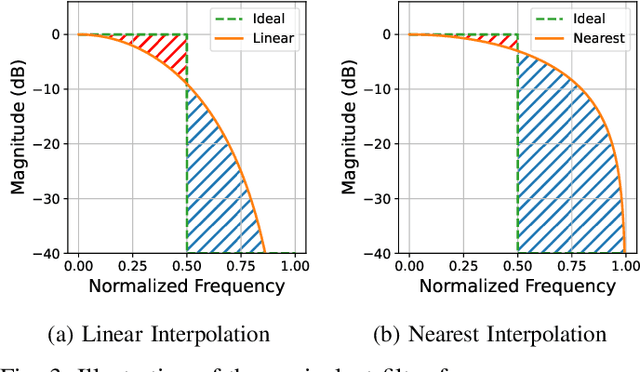
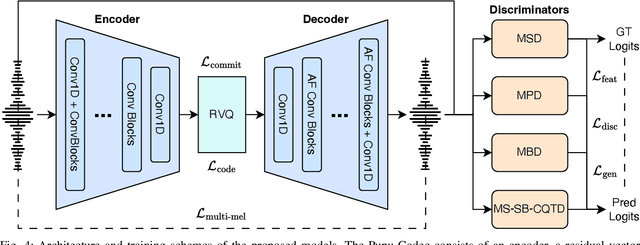
Neural vocoders and codecs reconstruct waveforms from acoustic representations, which directly impact the audio quality. Among existing methods, upsampling-based time-domain models are superior in both inference speed and synthesis quality, achieving state-of-the-art performance. Still, despite their success in producing perceptually natural sound, their synthesis fidelity remains limited due to the aliasing artifacts brought by the inadequately designed model architectures. In particular, the unconstrained nonlinear activation generates an infinite number of harmonics that exceed the Nyquist frequency, resulting in ``folded-back'' aliasing artifacts. The widely used upsampling layer, ConvTranspose, copies the mirrored low-frequency parts to fill the empty high-frequency region, resulting in ``mirrored'' aliasing artifacts. Meanwhile, the combination of its inherent periodicity and the mirrored DC bias also brings ``tonal artifact,'' resulting in constant-frequency ringing. This paper aims to solve these issues from a signal processing perspective. Specifically, we apply oversampling and anti-derivative anti-aliasing to the activation function to obtain its anti-aliased form, and replace the problematic ConvTranspose layer with resampling to avoid the ``tonal artifact'' and eliminate aliased components. Based on our proposed anti-aliased modules, we introduce Pupu-Vocoder and Pupu-Codec, and release high-quality pre-trained checkpoints to facilitate audio generation research. We build a test signal benchmark to illustrate the effectiveness of the anti-aliased modules, and conduct experiments on speech, singing voice, music, and audio to validate our proposed models. Experimental results confirm that our lightweight Pupu-Vocoder and Pupu-Codec models can easily outperform existing systems on singing voice, music, and audio, while achieving comparable performance on speech.
SpeechJudge: Towards Human-Level Judgment for Speech Naturalness
Nov 11, 2025

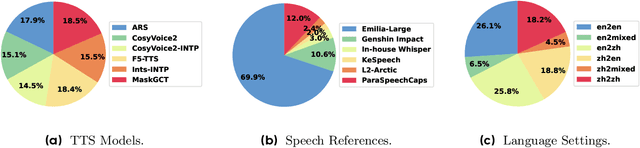
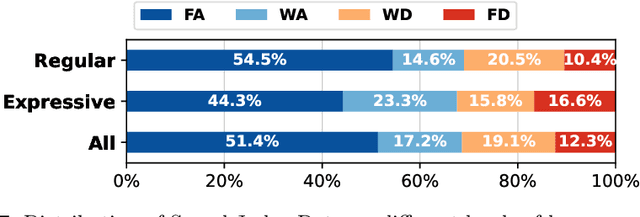
Aligning large generative models with human feedback is a critical challenge. In speech synthesis, this is particularly pronounced due to the lack of a large-scale human preference dataset, which hinders the development of models that truly align with human perception. To address this, we introduce SpeechJudge, a comprehensive suite comprising a dataset, a benchmark, and a reward model centered on naturalness--one of the most fundamental subjective metrics for speech synthesis. First, we present SpeechJudge-Data, a large-scale human feedback corpus of 99K speech pairs. The dataset is constructed using a diverse set of advanced zero-shot text-to-speech (TTS) models across diverse speech styles and multiple languages, with human annotations for both intelligibility and naturalness preference. From this, we establish SpeechJudge-Eval, a challenging benchmark for speech naturalness judgment. Our evaluation reveals that existing metrics and AudioLLMs struggle with this task; the leading model, Gemini-2.5-Flash, achieves less than 70% agreement with human judgment, highlighting a significant gap for improvement. To bridge this gap, we develop SpeechJudge-GRM, a generative reward model (GRM) based on Qwen2.5-Omni-7B. It is trained on SpeechJudge-Data via a two-stage post-training process: Supervised Fine-Tuning (SFT) with Chain-of-Thought rationales followed by Reinforcement Learning (RL) with GRPO on challenging cases. On the SpeechJudge-Eval benchmark, the proposed SpeechJudge-GRM demonstrates superior performance, achieving 77.2% accuracy (and 79.4% after inference-time scaling @10) compared to a classic Bradley-Terry reward model (72.7%). Furthermore, SpeechJudge-GRM can be also employed as a reward function during the post-training of speech generation models to facilitate their alignment with human preferences.