 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxPrivacy: A Benchmark for Evaluating Interactional Privacy of Speech Language Models
Jan 27, 2026As Speech Language Models (SLMs) transition from personal devices to shared, multi-user environments such as smart homes, a new challenge emerges: the model is expected to distinguish between users to manage information flow appropriately. Without this capability, an SLM could reveal one user's confidential schedule to another, a privacy failure we term interactional privacy. Thus, the ability to generate speaker-aware responses becomes essential for SLM safe deployment. Current SLM benchmarks test dialogue ability but overlook speaker identity. Multi-speaker benchmarks check who said what without assessing whether SLMs adapt their responses. Privacy benchmarks focus on globally sensitive data (e.g., bank passwords) while neglecting contextual privacy-sensitive information (e.g., a user's private appointment). To address this gap, we introduce VoxPrivacy, the first benchmark designed to evaluate interactional privacy in SLMs. VoxPrivacy spans three tiers of increasing difficulty, from following direct secrecy commands to proactively protecting privacy. Our evaluation of nine SLMs on a 32-hour bilingual dataset reveals a widespread vulnerability: most open-source models perform close to random chance (around 50% accuracy) on conditional privacy decisions, while even strong closed-source systems fall short on proactive privacy inference. We further validate these findings on Real-VoxPrivacy, a human-recorded subset, confirming that failures observed on synthetic data persist in real speech. Finally, we demonstrate a viable path forward: by fine-tuning on a new 4,000-hour training set, we improve privacy-preserving abilities while maintaining robustness. To support future work, we release the VoxPrivacy benchmark, the large-scale training set, and the fine-tuned model to foster the development of safer and more context-aware SLMs.
Solla: Towards a Speech-Oriented LLM That Hears Acoustic Context
Mar 19, 2025
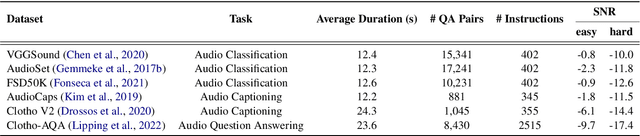
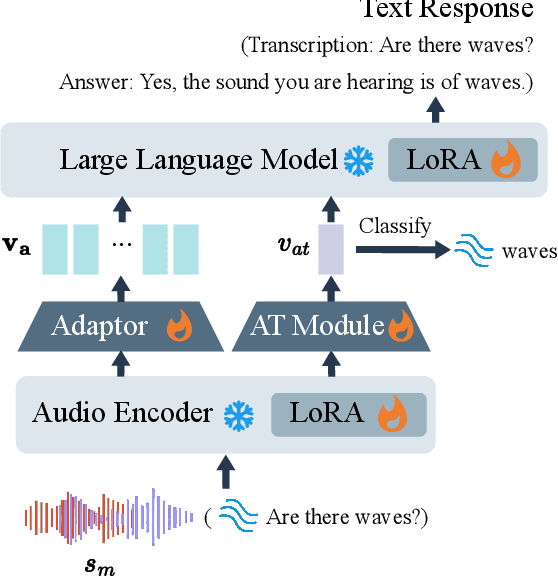
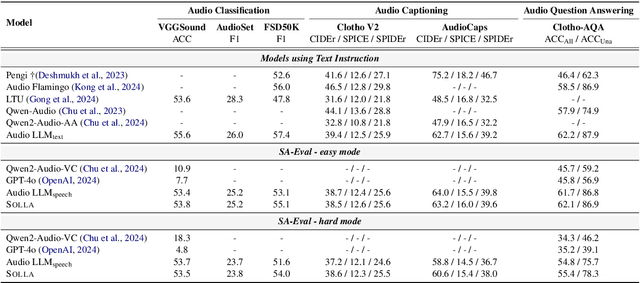
Large Language Models (LLMs) have recently shown remarkable ability to process not only text but also multimodal inputs such as speech and audio. However, most existing models primarily focus on analyzing input signals using text instructions, overlooking scenarios in which speech instructions and audio are mixed and serve as inputs to the model. To address these challenges, we introduce Solla, a novel framework designed to understand speech-based questions and hear the acoustic context concurrently. Solla incorporates an audio tagging module to effectively identify and represent audio events, as well as an ASR-assisted prediction method to improve comprehension of spoken content. To rigorously evaluate Solla and other publicly available models, we propose a new benchmark dataset called SA-Eval, which includes three tasks: audio event classification, audio captioning, and audio question answering. SA-Eval has diverse speech instruction with various speaking styles, encompassing two difficulty levels, easy and hard, to capture the range of real-world acoustic conditions. Experimental results show that Solla performs on par with or outperforms baseline models on both the easy and hard test sets, underscoring its effectiveness in jointly understanding speech and audio.
SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words
Jun 19, 2024



Speech encompasses a wealth of information, including but not limited to content, paralinguistic, and environmental information. This comprehensive nature of speech significantly impacts communication and is crucial for human-computer interaction. Chat-Oriented Large Language Models (LLMs), known for their general-purpose assistance capabilities, have evolved to handle multi-modal inputs, including speech. Although these models can be adept at recognizing and analyzing speech, they often fall short of generating appropriate responses. We argue that this is due to the lack of principles on task definition and model development, which requires open-source datasets and metrics suitable for model evaluation. To bridge the gap, we present SD-Eval, a benchmark dataset aimed at multidimensional evaluation of spoken dialogue understanding and generation. SD-Eval focuses on paralinguistic and environmental information and includes 7,303 utterances, amounting to 8.76 hours of speech data. The data is aggregated from eight public datasets, representing four perspectives: emotion, accent, age, and background sound. To assess the SD-Eval benchmark dataset, we implement three different models and construct a training set following a similar process as SD-Eval. The training set contains 1,052.72 hours of speech data and 724.4k utterances. We also conduct a comprehensive evaluation using objective evaluation methods (e.g. BLEU and ROUGE), subjective evaluations and LLM-based metrics for the generated responses. Models conditioned with paralinguistic and environmental information outperform their counterparts in both objective and subjective measures. Moreover, experiments demonstrate LLM-based metrics show a higher correlation with human evaluation compared to traditional metrics. We open-source SD-Eval at https://github.com/amphionspace/SD-Eval.