 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolla: Towards a Speech-Oriented LLM That Hears Acoustic Context
Paper and Code

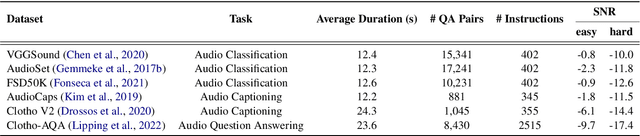
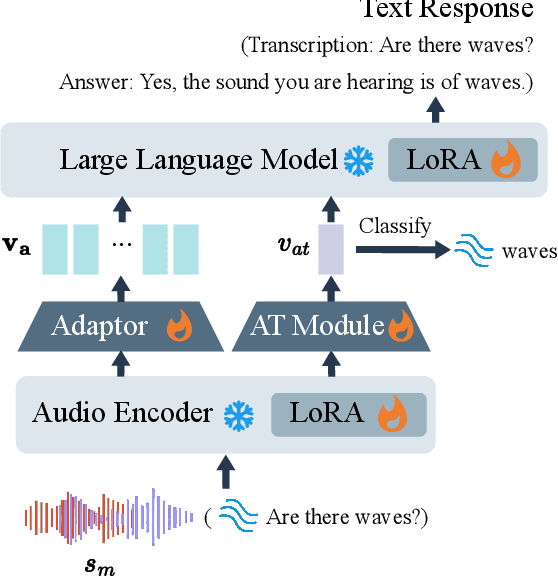
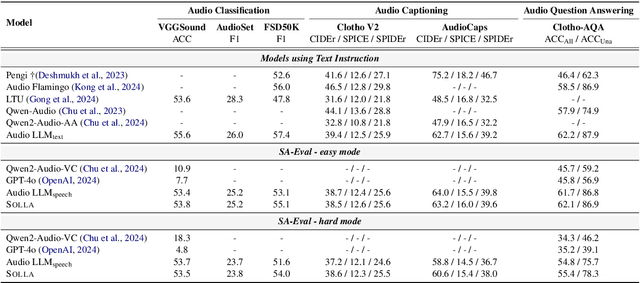
Large Language Models (LLMs) have recently shown remarkable ability to process not only text but also multimodal inputs such as speech and audio. However, most existing models primarily focus on analyzing input signals using text instructions, overlooking scenarios in which speech instructions and audio are mixed and serve as inputs to the model. To address these challenges, we introduce Solla, a novel framework designed to understand speech-based questions and hear the acoustic context concurrently. Solla incorporates an audio tagging module to effectively identify and represent audio events, as well as an ASR-assisted prediction method to improve comprehension of spoken content. To rigorously evaluate Solla and other publicly available models, we propose a new benchmark dataset called SA-Eval, which includes three tasks: audio event classification, audio captioning, and audio question answering. SA-Eval has diverse speech instruction with various speaking styles, encompassing two difficulty levels, easy and hard, to capture the range of real-world acoustic conditions. Experimental results show that Solla performs on par with or outperforms baseline models on both the easy and hard test sets, underscoring its effectiveness in jointly understanding speech and audio.