 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolla: Towards a Speech-Oriented LLM That Hears Acoustic Context
Mar 19, 2025
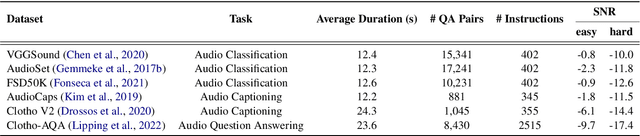
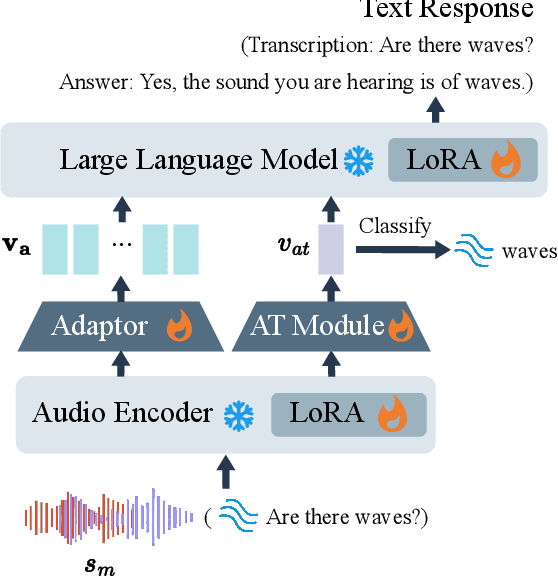
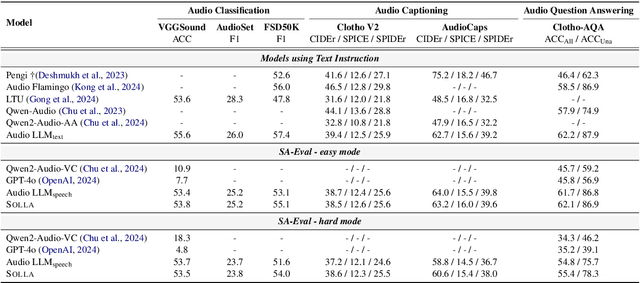
Large Language Models (LLMs) have recently shown remarkable ability to process not only text but also multimodal inputs such as speech and audio. However, most existing models primarily focus on analyzing input signals using text instructions, overlooking scenarios in which speech instructions and audio are mixed and serve as inputs to the model. To address these challenges, we introduce Solla, a novel framework designed to understand speech-based questions and hear the acoustic context concurrently. Solla incorporates an audio tagging module to effectively identify and represent audio events, as well as an ASR-assisted prediction method to improve comprehension of spoken content. To rigorously evaluate Solla and other publicly available models, we propose a new benchmark dataset called SA-Eval, which includes three tasks: audio event classification, audio captioning, and audio question answering. SA-Eval has diverse speech instruction with various speaking styles, encompassing two difficulty levels, easy and hard, to capture the range of real-world acoustic conditions. Experimental results show that Solla performs on par with or outperforms baseline models on both the easy and hard test sets, underscoring its effectiveness in jointly understanding speech and audio.
ID$^3$: Identity-Preserving-yet-Diversified Diffusion Models for Synthetic Face Recognition
Sep 26, 2024



Synthetic face recognition (SFR) aims to generate synthetic face datasets that mimic the distribution of real face data, which allows for training face recognition models in a privacy-preserving manner. Despite the remarkable potential of diffusion models in image generation, current diffusion-based SFR models struggle with generalization to real-world faces. To address this limitation, we outline three key objectives for SFR: (1) promoting diversity across identities (inter-class diversity), (2) ensuring diversity within each identity by injecting various facial attributes (intra-class diversity), and (3) maintaining identity consistency within each identity group (intra-class identity preservation). Inspired by these goals, we introduce a diffusion-fueled SFR model termed $\text{ID}^3$. $\text{ID}^3$ employs an ID-preserving loss to generate diverse yet identity-consistent facial appearances. Theoretically, we show that minimizing this loss is equivalent to maximizing the lower bound of an adjusted conditional log-likelihood over ID-preserving data. This equivalence motivates an ID-preserving sampling algorithm, which operates over an adjusted gradient vector field, enabling the generation of fake face recognition datasets that approximate the distribution of real-world faces. Extensive experiments across five challenging benchmarks validate the advantages of $\text{ID}^3$.
Data-Free Federated Class Incremental Learning with Diffusion-Based Generative Memory
May 22, 2024Federated Class Incremental Learning (FCIL) is a critical yet largely underexplored issue that deals with the dynamic incorporation of new classes within federated learning (FL). Existing methods often employ generative adversarial networks (GANs) to produce synthetic images to address privacy concerns in FL. However, GANs exhibit inherent instability and high sensitivity, compromising the effectiveness of these methods. In this paper, we introduce a novel data-free federated class incremental learning framework with diffusion-based generative memory (DFedDGM) to mitigate catastrophic forgetting by generating stable, high-quality images through diffusion models. We design a new balanced sampler to help train the diffusion models to alleviate the common non-IID problem in FL, and introduce an entropy-based sample filtering technique from an information theory perspective to enhance the quality of generative samples. Finally, we integrate knowledge distillation with a feature-based regularization term for better knowledge transfer. Our framework does not incur additional communication costs compared to the baseline FedAvg method. Extensive experiments across multiple datasets demonstrate that our method significantly outperforms existing baselines, e.g., over a 4% improvement in average accuracy on the Tiny-ImageNet dataset.
One-Shot Sequential Federated Learning for Non-IID Data by Enhancing Local Model Diversity
Apr 18, 2024Traditional federated learning mainly focuses on parallel settings (PFL), which can suffer significant communication and computation costs. In contrast, one-shot and sequential federated learning (SFL) have emerged as innovative paradigms to alleviate these costs. However, the issue of non-IID (Independent and Identically Distributed) data persists as a significant challenge in one-shot and SFL settings, exacerbated by the restricted communication between clients. In this paper, we improve the one-shot sequential federated learning for non-IID data by proposing a local model diversity-enhancing strategy. Specifically, to leverage the potential of local model diversity for improving model performance, we introduce a local model pool for each client that comprises diverse models generated during local training, and propose two distance measurements to further enhance the model diversity and mitigate the effect of non-IID data. Consequently, our proposed framework can improve the global model performance while maintaining low communication costs. Extensive experiments demonstrate that our method exhibits superior performance to existing one-shot PFL methods and achieves better accuracy compared with state-of-the-art one-shot SFL methods on both label-skew and domain-shift tasks (e.g., 6%+ accuracy improvement on the CIFAR-10 dataset).
SemRoDe: Macro Adversarial Training to Learn Representations That are Robust to Word-Level Attacks
Mar 27, 2024Language models (LMs) are indispensable tools for natural language processing tasks, but their vulnerability to adversarial attacks remains a concern. While current research has explored adversarial training techniques, their improvements to defend against word-level attacks have been limited. In this work, we propose a novel approach called Semantic Robust Defence (SemRoDe), a Macro Adversarial Training strategy to enhance the robustness of LMs. Drawing inspiration from recent studies in the image domain, we investigate and later confirm that in a discrete data setting such as language, adversarial samples generated via word substitutions do indeed belong to an adversarial domain exhibiting a high Wasserstein distance from the base domain. Our method learns a robust representation that bridges these two domains. We hypothesize that if samples were not projected into an adversarial domain, but instead to a domain with minimal shift, it would improve attack robustness. We align the domains by incorporating a new distance-based objective. With this, our model is able to learn more generalized representations by aligning the model's high-level output features and therefore better handling unseen adversarial samples. This method can be generalized across word embeddings, even when they share minimal overlap at both vocabulary and word-substitution levels. To evaluate the effectiveness of our approach, we conduct experiments on BERT and RoBERTa models on three datasets. The results demonstrate promising state-of-the-art robustness.
Graph Descriptive Order Improves Reasoning with Large Language Model
Feb 24, 2024
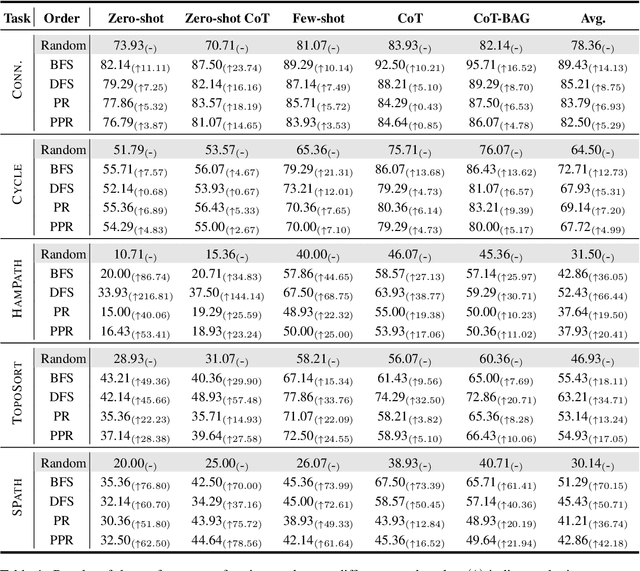
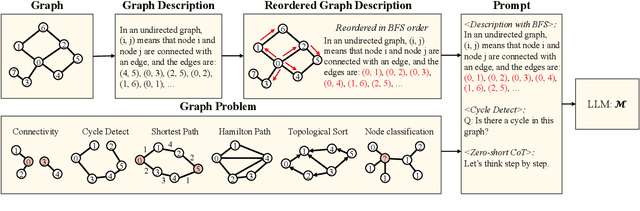
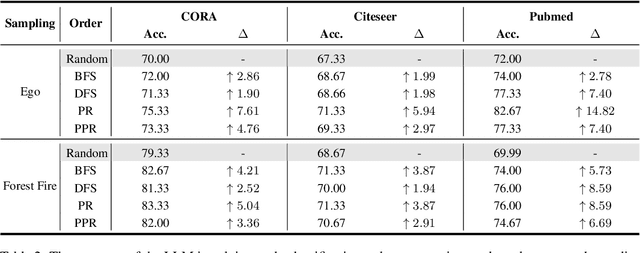
In recent years, large language models have achieved state-of-the-art performance across multiple domains. However, the progress in the field of graph reasoning with LLM remains limited. Our work delves into this gap by thoroughly investigating graph reasoning with LLMs. In this work, we reveal the impact of the order of graph description on LLMs' graph reasoning performance, which significantly affects LLMs' reasoning abilities. By altering this order, we enhance the performance of LLMs from 42.22\% to 70\%. Furthermore, we introduce the Scaled Graph Reasoning benchmark for assessing LLMs' performance across various graph sizes and evaluate the relationship between LLMs' graph reasoning abilities and graph size. We discover that the graph reasoning performance of LLMs does not monotonically decrease with the increase in graph size. The experiments span several mainstream models, including GPT-3.5, LLaMA-2-7B, and LLaMA-2-13B, to offer a comprehensive evaluation.
Towards Better Graph Representation Learning with Parameterized Decomposition & Filtering
May 10, 2023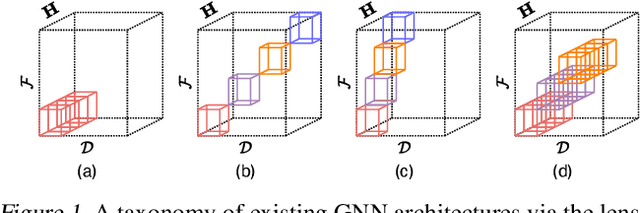

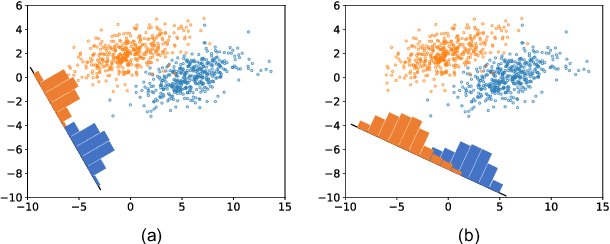
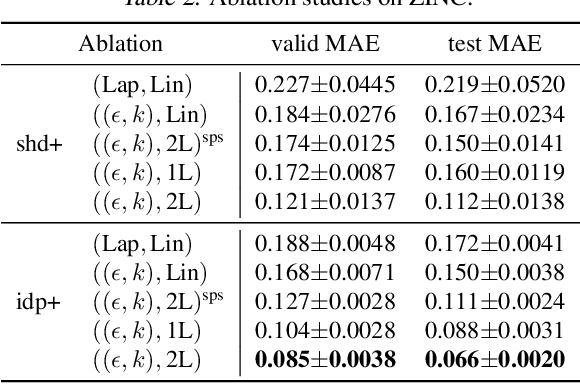
Proposing an effective and flexible matrix to represent a graph is a fundamental challenge that has been explored from multiple perspectives, e.g., filtering in Graph Fourier Transforms. In this work, we develop a novel and general framework which unifies many existing GNN models from the view of parameterized decomposition and filtering, and show how it helps to enhance the flexibility of GNNs while alleviating the smoothness and amplification issues of existing models. Essentially, we show that the extensively studied spectral graph convolutions with learnable polynomial filters are constrained variants of this formulation, and releasing these constraints enables our model to express the desired decomposition and filtering simultaneously. Based on this generalized framework, we develop models that are simple in implementation but achieve significant improvements and computational efficiency on a variety of graph learning tasks. Code is available at https://github.com/qslim/PDF.
Data-Free Diversity-Based Ensemble Selection For One-Shot Federated Learning in Machine Learning Model Market
Feb 23, 2023



The emerging availability of trained machine learning models has put forward the novel concept of Machine Learning Model Market in which one can harness the collective intelligence of multiple well-trained models to improve the performance of the resultant model through one-shot federated learning and ensemble learning in a data-free manner. However, picking the models available in the market for ensemble learning is time-consuming, as using all the models is not always the best approach. It is thus crucial to have an effective ensemble selection strategy that can find a good subset of the base models for the ensemble. Conventional ensemble selection techniques are not applicable, as we do not have access to the local datasets of the parties in the federated learning setting. In this paper, we present a novel Data-Free Diversity-Based method called DeDES to address the ensemble selection problem for models generated by one-shot federated learning in practical applications such as model markets. Experiments showed that our method can achieve both better performance and higher efficiency over 5 datasets and 4 different model structures under the different data-partition strategies.
Birds of a Feather Trust Together: Knowing When to Trust a Classifier via Adaptive Neighborhood Aggregation
Nov 29, 2022


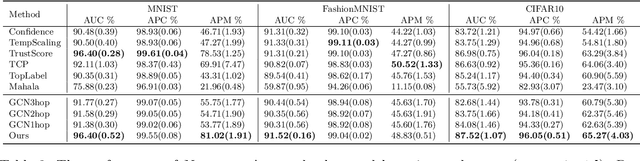
How do we know when the predictions made by a classifier can be trusted? This is a fundamental problem that also has immense practical applicability, especially in safety-critical areas such as medicine and autonomous driving. The de facto approach of using the classifier's softmax outputs as a proxy for trustworthiness suffers from the over-confidence issue; while the most recent works incur problems such as additional retraining cost and accuracy versus trustworthiness trade-off. In this work, we argue that the trustworthiness of a classifier's prediction for a sample is highly associated with two factors: the sample's neighborhood information and the classifier's output. To combine the best of both worlds, we design a model-agnostic post-hoc approach NeighborAgg to leverage the two essential information via an adaptive neighborhood aggregation. Theoretically, we show that NeighborAgg is a generalized version of a one-hop graph convolutional network, inheriting the powerful modeling ability to capture the varying similarity between samples within each class. We also extend our approach to the closely related task of mislabel detection and provide a theoretical coverage guarantee to bound the false negative. Empirically, extensive experiments on image and tabular benchmarks verify our theory and suggest that NeighborAgg outperforms other methods, achieving state-of-the-art trustworthiness performance.
* Published in Transactions on Machine Learning Research (TMLR) 2022
AdaRNN: Adaptive Learning and Forecasting of Time Series
Aug 11, 2021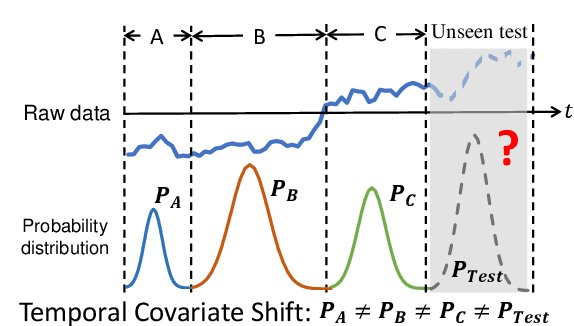

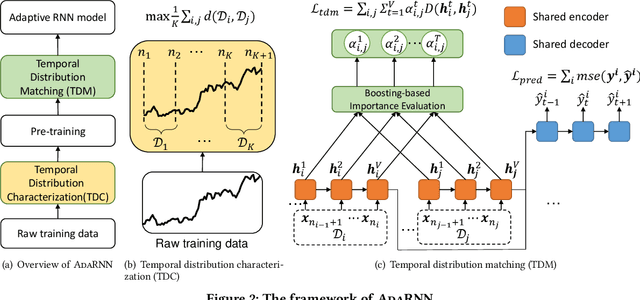
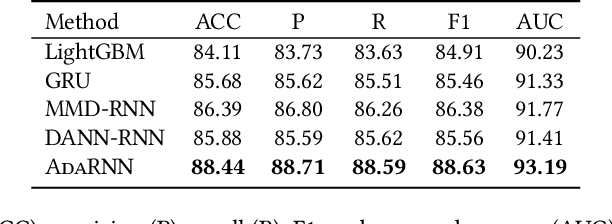
Time series has wide applications in the real world and is known to be difficult to forecast. Since its statistical properties change over time, its distribution also changes temporally, which will cause severe distribution shift problem to existing methods. However, it remains unexplored to model the time series in the distribution perspective. In this paper, we term this as Temporal Covariate Shift (TCS). This paper proposes Adaptive RNNs (AdaRNN) to tackle the TCS problem by building an adaptive model that generalizes well on the unseen test data. AdaRNN is sequentially composed of two novel algorithms. First, we propose Temporal Distribution Characterization to better characterize the distribution information in the TS. Second, we propose Temporal Distribution Matching to reduce the distribution mismatch in TS to learn the adaptive TS model. AdaRNN is a general framework with flexible distribution distances integrated. Experiments on human activity recognition, air quality prediction, and financial analysis show that AdaRNN outperforms the latest methods by a classification accuracy of 2.6% and significantly reduces the RMSE by 9.0%. We also show that the temporal distribution matching algorithm can be extended in Transformer structure to boost its performance.