 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteerFace: Debiasing Synthetic Face Generation via Adaptive Residue Perturbation
May 29, 2026The shortage of legally compliant data for face recognition training has sparked growing interest in using synthetic data as an alternative. While recent diffusion-based methods enable the generation of photorealistic face images with strong identity adherence and data diversity, their downstream recognition performance still exhibits a significant synthetic-real gap. This paper identifies visual tendency as a previously underexplored limitation, whereby synthetic data exhibit an unrealistic prevalence of visual attributes and thus deviate from the real-data distribution. Visual tendency can be attributed to the generator's conditioning on identity embeddings, through which co-occurring residual visual cues are unintentionally absorbed into learned identity semantics. To discourage the generator from exploiting such visual cues, this paper proposes SteerFace, a simple and efficient training framework that perturbs identity embeddings by steering them toward random orthogonal directions on the embedding hypersphere. The perturbation serves as an identity-preserving regularizer that penalizes the generator's reliance on non-identity components, as supported by theoretical analysis. This paper further introduces an adaptive strategy that learns perturbation strengths with both sample-wise preference and favorable overall statistics. Extensive experiments show that SteerFace effectively mitigates visual tendency, outperforms prior methods in downstream face recognition, and generalizes well across different training datasets and generation pipelines.
TranX-Adapter: Bridging Artifacts and Semantics within MLLMs for Robust AI-generated Image Detection
Feb 25, 2026Rapid advances in AI-generated image (AIGI) technology enable highly realistic synthesis, threatening public information integrity and security. Recent studies have demonstrated that incorporating texture-level artifact features alongside semantic features into multimodal large language models (MLLMs) can enhance their AIGI detection capability. However, our preliminary analyses reveal that artifact features exhibit high intra-feature similarity, leading to an almost uniform attention map after the softmax operation. This phenomenon causes attention dilution, thereby hindering effective fusion between semantic and artifact features. To overcome this limitation, we propose a lightweight fusion adapter, TranX-Adapter, which integrates a Task-aware Optimal-Transport Fusion that leverages the Jensen-Shannon divergence between artifact and semantic prediction probabilities as a cost matrix to transfer artifact information into semantic features, and an X-Fusion that employs cross-attention to transfer semantic information into artifact features. Experiments on standard AIGI detection benchmarks upon several advanced MLLMs, show that our TranX-Adapter brings consistent and significant improvements (up to +6% accuracy).
Data Synthesis with Diverse Styles for Face Recognition via 3DMM-Guided Diffusion
Apr 01, 2025



Identity-preserving face synthesis aims to generate synthetic face images of virtual subjects that can substitute real-world data for training face recognition models. While prior arts strive to create images with consistent identities and diverse styles, they face a trade-off between them. Identifying their limitation of treating style variation as subject-agnostic and observing that real-world persons actually have distinct, subject-specific styles, this paper introduces MorphFace, a diffusion-based face generator. The generator learns fine-grained facial styles, e.g., shape, pose and expression, from the renderings of a 3D morphable model (3DMM). It also learns identities from an off-the-shelf recognition model. To create virtual faces, the generator is conditioned on novel identities of unlabeled synthetic faces, and novel styles that are statistically sampled from a real-world prior distribution. The sampling especially accounts for both intra-subject variation and subject distinctiveness. A context blending strategy is employed to enhance the generator's responsiveness to identity and style conditions. Extensive experiments show that MorphFace outperforms the best prior arts in face recognition efficacy.
UIFace: Unleashing Inherent Model Capabilities to Enhance Intra-Class Diversity in Synthetic Face Recognition
Feb 27, 2025



Face recognition (FR) stands as one of the most crucial applications in computer vision. The accuracy of FR models has significantly improved in recent years due to the availability of large-scale human face datasets. However, directly using these datasets can inevitably lead to privacy and legal problems. Generating synthetic data to train FR models is a feasible solution to circumvent these issues. While existing synthetic-based face recognition methods have made significant progress in generating identity-preserving images, they are severely plagued by context overfitting, resulting in a lack of intra-class diversity of generated images and poor face recognition performance. In this paper, we propose a framework to Unleash Inherent capability of the model to enhance intra-class diversity for synthetic face recognition, shortened as UIFace. Our framework first trains a diffusion model that can perform sampling conditioned on either identity contexts or a learnable empty context. The former generates identity-preserving images but lacks variations, while the latter exploits the model's intrinsic ability to synthesize intra-class-diversified images but with random identities. Then we adopt a novel two-stage sampling strategy during inference to fully leverage the strengths of both types of contexts, resulting in images that are diverse as well as identitypreserving. Moreover, an attention injection module is introduced to further augment the intra-class variations by utilizing attention maps from the empty context to guide the sampling process in ID-conditioned generation. Experiments show that our method significantly surpasses previous approaches with even less training data and half the size of synthetic dataset. The proposed UIFace even achieves comparable performance with FR models trained on real datasets when we further increase the number of synthetic identities.
ID$^3$: Identity-Preserving-yet-Diversified Diffusion Models for Synthetic Face Recognition
Sep 26, 2024



Synthetic face recognition (SFR) aims to generate synthetic face datasets that mimic the distribution of real face data, which allows for training face recognition models in a privacy-preserving manner. Despite the remarkable potential of diffusion models in image generation, current diffusion-based SFR models struggle with generalization to real-world faces. To address this limitation, we outline three key objectives for SFR: (1) promoting diversity across identities (inter-class diversity), (2) ensuring diversity within each identity by injecting various facial attributes (intra-class diversity), and (3) maintaining identity consistency within each identity group (intra-class identity preservation). Inspired by these goals, we introduce a diffusion-fueled SFR model termed $\text{ID}^3$. $\text{ID}^3$ employs an ID-preserving loss to generate diverse yet identity-consistent facial appearances. Theoretically, we show that minimizing this loss is equivalent to maximizing the lower bound of an adjusted conditional log-likelihood over ID-preserving data. This equivalence motivates an ID-preserving sampling algorithm, which operates over an adjusted gradient vector field, enabling the generation of fake face recognition datasets that approximate the distribution of real-world faces. Extensive experiments across five challenging benchmarks validate the advantages of $\text{ID}^3$.
SlerpFace: Face Template Protection via Spherical Linear Interpolation
Jul 03, 2024



Contemporary face recognition systems use feature templates extracted from face images to identify persons. To enhance privacy, face template protection techniques are widely employed to conceal sensitive identity and appearance information stored in the template. This paper identifies an emerging privacy attack form utilizing diffusion models that could nullify prior protection, referred to as inversion attacks. The attack can synthesize high-quality, identity-preserving face images from templates, revealing persons' appearance. Based on studies of the diffusion model's generative capability, this paper proposes a defense to deteriorate the attack, by rotating templates to a noise-like distribution. This is achieved efficiently by spherically and linearly interpolating templates, or slerp, on their located hypersphere. This paper further proposes to group-wisely divide and drop out templates' feature dimensions, to enhance the irreversibility of rotated templates. The division of groups and dropouts within each group are learned in a recognition-favored way. The proposed techniques are concretized as a novel face template protection technique, SlerpFace. Extensive experiments show that SlerpFace provides satisfactory recognition accuracy and comprehensive privacy protection against inversion and other attack forms, superior to prior arts.
Privacy-Preserving Face Recognition Using Trainable Feature Subtraction
Mar 19, 2024The widespread adoption of face recognition has led to increasing privacy concerns, as unauthorized access to face images can expose sensitive personal information. This paper explores face image protection against viewing and recovery attacks. Inspired by image compression, we propose creating a visually uninformative face image through feature subtraction between an original face and its model-produced regeneration. Recognizable identity features within the image are encouraged by co-training a recognition model on its high-dimensional feature representation. To enhance privacy, the high-dimensional representation is crafted through random channel shuffling, resulting in randomized recognizable images devoid of attacker-leverageable texture details. We distill our methodologies into a novel privacy-preserving face recognition method, MinusFace. Experiments demonstrate its high recognition accuracy and effective privacy protection. Its code is available at https://github.com/Tencent/TFace.
Generalized Category Discovery in Semantic Segmentation
Nov 20, 2023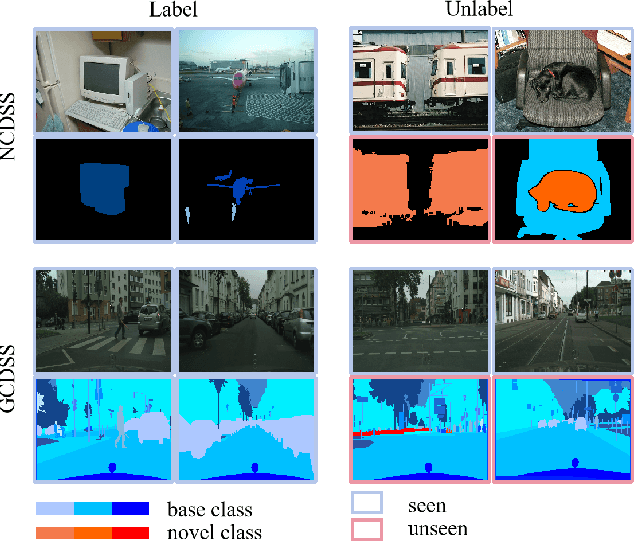
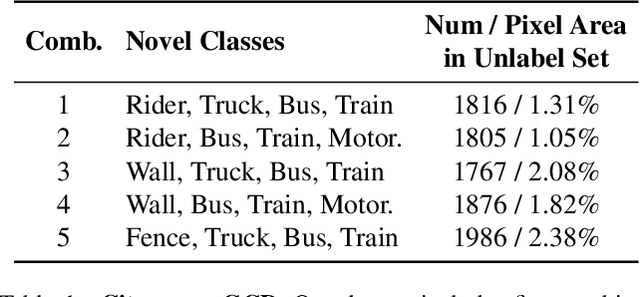
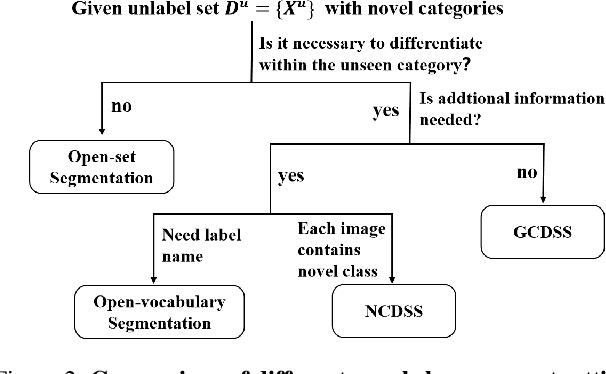

This paper explores a novel setting called Generalized Category Discovery in Semantic Segmentation (GCDSS), aiming to segment unlabeled images given prior knowledge from a labeled set of base classes. The unlabeled images contain pixels of the base class or novel class. In contrast to Novel Category Discovery in Semantic Segmentation (NCDSS), there is no prerequisite for prior knowledge mandating the existence of at least one novel class in each unlabeled image. Besides, we broaden the segmentation scope beyond foreground objects to include the entire image. Existing NCDSS methods rely on the aforementioned priors, making them challenging to truly apply in real-world situations. We propose a straightforward yet effective framework that reinterprets the GCDSS challenge as a task of mask classification. Additionally, we construct a baseline method and introduce the Neighborhood Relations-Guided Mask Clustering Algorithm (NeRG-MaskCA) for mask categorization to address the fragmentation in semantic representation. A benchmark dataset, Cityscapes-GCD, derived from the Cityscapes dataset, is established to evaluate the GCDSS framework. Our method demonstrates the feasibility of the GCDSS problem and the potential for discovering and segmenting novel object classes in unlabeled images. We employ the generated pseudo-labels from our approach as ground truth to supervise the training of other models, thereby enabling them with the ability to segment novel classes. It paves the way for further research in generalized category discovery, broadening the horizons of semantic segmentation and its applications. For details, please visit https://github.com/JethroPeng/GCDSS
Proximity-Informed Calibration for Deep Neural Networks
Jun 07, 2023Confidence calibration is central to providing accurate and interpretable uncertainty estimates, especially under safety-critical scenarios. However, we find that existing calibration algorithms often overlook the issue of proximity bias, a phenomenon where models tend to be more overconfident in low proximity data (i.e., lying in the sparse region of the data distribution) compared to high proximity samples, and thus suffer from inconsistent miscalibration across different proximity samples. We examine the problem over pretrained ImageNet models and observe that: 1) Proximity bias exists across a wide variety of model architectures and sizes; 2) Transformer-based models are more susceptible to proximity bias than CNN-based models; 3) Proximity bias persists even after performing popular calibration algorithms like temperature scaling; 4) Models tend to overfit more heavily on low proximity samples than on high proximity samples. Motivated by the empirical findings, we propose ProCal, a plug-and-play algorithm with a theoretical guarantee to adjust sample confidence based on proximity. To further quantify the effectiveness of calibration algorithms in mitigating proximity bias, we introduce proximity-informed expected calibration error (PIECE) with theoretical analysis. We show that ProCal is effective in addressing proximity bias and improving calibration on balanced, long-tail, and distribution-shift settings under four metrics over various model architectures.
Probabilistic Contrastive Loss for Self-Supervised Learning
Dec 02, 2021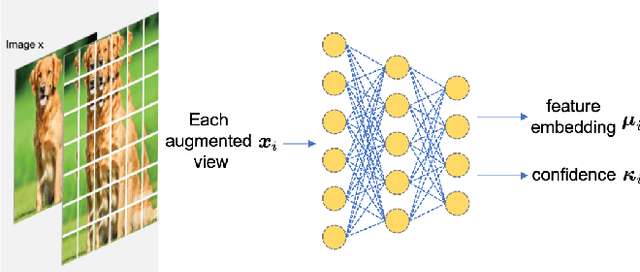
This paper proposes a probabilistic contrastive loss function for self-supervised learning. The well-known contrastive loss is deterministic and involves a temperature hyperparameter that scales the inner product between two normed feature embeddings. By reinterpreting the temperature hyperparameter as a quantity related to the radius of the hypersphere, we derive a new loss function that involves a confidence measure which quantifies uncertainty in a mathematically grounding manner. Some intriguing properties of the proposed loss function are empirically demonstrated, which agree with human-like predictions. We believe the present work brings up a new prospective to the area of contrastive learning.