 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboStereo: Dual-Tower 4D Embodied World Models for Unified Policy Optimization
Mar 13, 2026Scalable Embodied AI faces fundamental constraints due to prohibitive costs and safety risks of real-world interaction. While Embodied World Models (EWMs) offer promise through imagined rollouts, existing approaches suffer from geometric hallucinations and lack unified optimization frameworks for practical policy improvement. We introduce RoboStereo, a symmetric dual-tower 4D world model that employs bidirectional cross-modal enhancement to ensure spatiotemporal geometric consistency and alleviate physics hallucinations. Building upon this high-fidelity 4D simulator, we present the first unified framework for world-model-based policy optimization: (1) Test-Time Policy Augmentation (TTPA) for pre-execution verification, (2) Imitative-Evolutionary Policy Learning (IEPL) leveraging visual perceptual rewards to learn from expert demonstrations, and (3) Open-Exploration Policy Learning (OEPL) enabling autonomous skill discovery and self-correction. Comprehensive experiments demonstrate RoboStereo achieves state-of-the-art generation quality, with our unified framework delivering >97% average relative improvement on fine-grained manipulation tasks.
Beyond VLM-Based Rewards: Diffusion-Native Latent Reward Modeling
Feb 11, 2026Preference optimization for diffusion and flow-matching models relies on reward functions that are both discriminatively robust and computationally efficient. Vision-Language Models (VLMs) have emerged as the primary reward provider, leveraging their rich multimodal priors to guide alignment. However, their computation and memory cost can be substantial, and optimizing a latent diffusion generator through a pixel-space reward introduces a domain mismatch that complicates alignment. In this paper, we propose DiNa-LRM, a diffusion-native latent reward model that formulates preference learning directly on noisy diffusion states. Our method introduces a noise-calibrated Thurstone likelihood with diffusion-noise-dependent uncertainty. DiNa-LRM leverages a pretrained latent diffusion backbone with a timestep-conditioned reward head, and supports inference-time noise ensembling, providing a diffusion-native mechanism for test-time scaling and robust rewarding. Across image alignment benchmarks, DiNa-LRM substantially outperforms existing diffusion-based reward baselines and achieves performance competitive with state-of-the-art VLMs at a fraction of the computational cost. In preference optimization, we demonstrate that DiNa-LRM improves preference optimization dynamics, enabling faster and more resource-efficient model alignment.
NeRF-MIR: Towards High-Quality Restoration of Masked Images with Neural Radiance Fields
Jan 24, 2026Neural Radiance Fields (NeRF) have demonstrated remarkable performance in novel view synthesis. However, there is much improvement room on restoring 3D scenes based on NeRF from corrupted images, which are common in natural scene captures and can significantly impact the effectiveness of NeRF. This paper introduces NeRF-MIR, a novel neural rendering approach specifically proposed for the restoration of masked images, demonstrating the potential of NeRF in this domain. Recognizing that randomly emitting rays to pixels in NeRF may not effectively learn intricate image textures, we propose a \textbf{P}atch-based \textbf{E}ntropy for \textbf{R}ay \textbf{E}mitting (\textbf{PERE}) strategy to distribute emitted rays properly. This enables NeRF-MIR to fuse comprehensive information from images of different views. Additionally, we introduce a \textbf{P}rogressively \textbf{I}terative \textbf{RE}storation (\textbf{PIRE}) mechanism to restore the masked regions in a self-training process. Furthermore, we design a dynamically-weighted loss function that automatically recalibrates the loss weights for masked regions. As existing datasets do not support NeRF-based masked image restoration, we construct three masked datasets to simulate corrupted scenarios. Extensive experiments on real data and constructed datasets demonstrate the superiority of NeRF-MIR over its counterparts in masked image restoration.
IDDR-NGP: Incorporating Detectors for Distractor Removal with Instant Neural Radiance Field
Jan 16, 2026This paper presents the first unified distractor removal method, named IDDR-NGP, which directly operates on Instant-NPG. The method is able to remove a wide range of distractors in 3D scenes, such as snowflakes, confetti, defoliation and petals, whereas existing methods usually focus on a specific type of distractors. By incorporating implicit 3D representations with 2D detectors, we demonstrate that it is possible to efficiently restore 3D scenes from multiple corrupted images. We design the learned perceptual image patch similarity~( LPIPS) loss and the multi-view compensation loss (MVCL) to jointly optimize the rendering results of IDDR-NGP, which could aggregate information from multi-view corrupted images. All of them can be trained in an end-to-end manner to synthesize high-quality 3D scenes. To support the research on distractors removal in implicit 3D representations, we build a new benchmark dataset that consists of both synthetic and real-world distractors. To validate the effectiveness and robustness of IDDR-NGP, we provide a wide range of distractors with corresponding annotated labels added to both realistic and synthetic scenes. Extensive experimental results demonstrate the effectiveness and robustness of IDDR-NGP in removing multiple types of distractors. In addition, our approach achieves results comparable with the existing SOTA desnow methods and is capable of accurately removing both realistic and synthetic distractors.
* 8 pages, 7 figures, accepted by ACM-MM23
VISTA: Enhancing Vision-Text Alignment in MLLMs via Cross-Modal Mutual Information Maximization
May 19, 2025Current multimodal large language models (MLLMs) face a critical challenge in modality alignment, often exhibiting a bias towards textual information at the expense of other modalities like vision. This paper conducts a systematic information-theoretic analysis of the widely used cross-entropy loss in MLLMs, uncovering its implicit alignment objective. Our theoretical investigation reveals that this implicit objective has inherent limitations, leading to a degradation of cross-modal alignment as text sequence length increases, thereby hindering effective multimodal information fusion. To overcome these drawbacks, we propose Vision-Text Alignment (VISTA), a novel approach guided by our theoretical insights. VISTA introduces an explicit alignment objective designed to maximize cross-modal mutual information, preventing the degradation of visual alignment. Notably, VISTA enhances the visual understanding capabilities of existing MLLMs without requiring any additional trainable modules or extra training data, making it both efficient and practical. Our method significantly outperforms baseline models across more than a dozen benchmark datasets, including VQAv2, MMStar, and MME, paving the way for new directions in MLLM modal alignment research.
Data Synthesis with Diverse Styles for Face Recognition via 3DMM-Guided Diffusion
Apr 01, 2025



Identity-preserving face synthesis aims to generate synthetic face images of virtual subjects that can substitute real-world data for training face recognition models. While prior arts strive to create images with consistent identities and diverse styles, they face a trade-off between them. Identifying their limitation of treating style variation as subject-agnostic and observing that real-world persons actually have distinct, subject-specific styles, this paper introduces MorphFace, a diffusion-based face generator. The generator learns fine-grained facial styles, e.g., shape, pose and expression, from the renderings of a 3D morphable model (3DMM). It also learns identities from an off-the-shelf recognition model. To create virtual faces, the generator is conditioned on novel identities of unlabeled synthetic faces, and novel styles that are statistically sampled from a real-world prior distribution. The sampling especially accounts for both intra-subject variation and subject distinctiveness. A context blending strategy is employed to enhance the generator's responsiveness to identity and style conditions. Extensive experiments show that MorphFace outperforms the best prior arts in face recognition efficacy.
From Visuals to Vocabulary: Establishing Equivalence Between Image and Text Token Through Autoregressive Pre-training in MLLMs
Feb 13, 2025
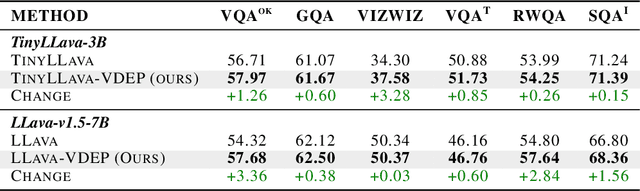
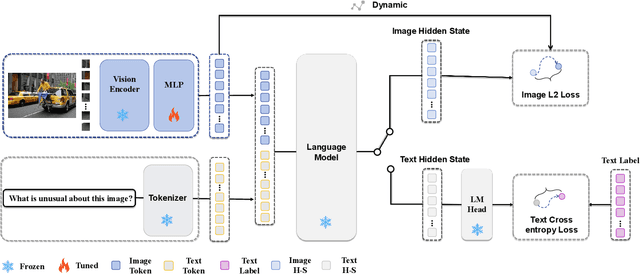
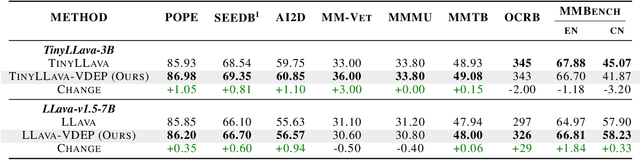
While MLLMs perform well on perceptual tasks, they lack precise multimodal alignment, limiting performance. To address this challenge, we propose Vision Dynamic Embedding-Guided Pretraining (VDEP), a hybrid autoregressive training paradigm for MLLMs. Utilizing dynamic embeddings from the MLP following the visual encoder, this approach supervises image hidden states and integrates image tokens into autoregressive training. Existing MLLMs primarily focused on recovering information from textual inputs, often neglecting the effective processing of image data. In contrast, the key improvement of this work is the reinterpretation of multimodal alignment as a process of recovering information from input data, with particular emphasis on reconstructing detailed visual features.The proposed method seamlessly integrates into standard models without architectural changes. Experiments on 13 benchmarks show VDEP outperforms baselines, surpassing existing methods.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
SlerpFace: Face Template Protection via Spherical Linear Interpolation
Jul 03, 2024



Contemporary face recognition systems use feature templates extracted from face images to identify persons. To enhance privacy, face template protection techniques are widely employed to conceal sensitive identity and appearance information stored in the template. This paper identifies an emerging privacy attack form utilizing diffusion models that could nullify prior protection, referred to as inversion attacks. The attack can synthesize high-quality, identity-preserving face images from templates, revealing persons' appearance. Based on studies of the diffusion model's generative capability, this paper proposes a defense to deteriorate the attack, by rotating templates to a noise-like distribution. This is achieved efficiently by spherically and linearly interpolating templates, or slerp, on their located hypersphere. This paper further proposes to group-wisely divide and drop out templates' feature dimensions, to enhance the irreversibility of rotated templates. The division of groups and dropouts within each group are learned in a recognition-favored way. The proposed techniques are concretized as a novel face template protection technique, SlerpFace. Extensive experiments show that SlerpFace provides satisfactory recognition accuracy and comprehensive privacy protection against inversion and other attack forms, superior to prior arts.
LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control
Jul 03, 2024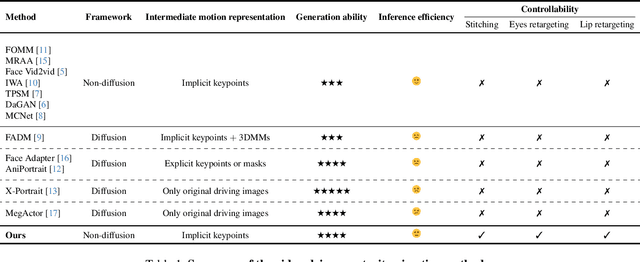
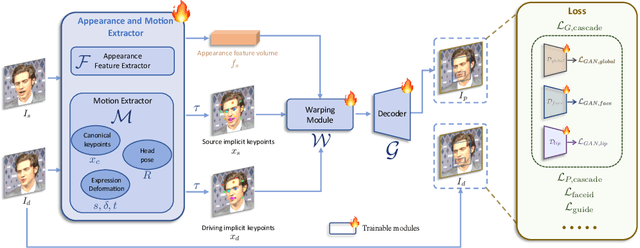
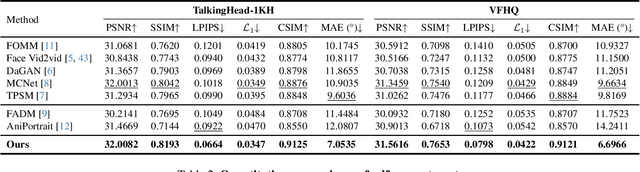
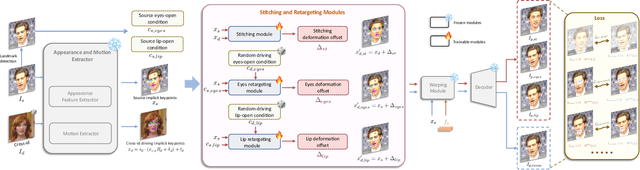
Portrait Animation aims to synthesize a lifelike video from a single source image, using it as an appearance reference, with motion (i.e., facial expressions and head pose) derived from a driving video, audio, text, or generation. Instead of following mainstream diffusion-based methods, we explore and extend the potential of the implicit-keypoint-based framework, which effectively balances computational efficiency and controllability. Building upon this, we develop a video-driven portrait animation framework named LivePortrait with a focus on better generalization, controllability, and efficiency for practical usage. To enhance the generation quality and generalization ability, we scale up the training data to about 69 million high-quality frames, adopt a mixed image-video training strategy, upgrade the network architecture, and design better motion transformation and optimization objectives. Additionally, we discover that compact implicit keypoints can effectively represent a kind of blendshapes and meticulously propose a stitching and two retargeting modules, which utilize a small MLP with negligible computational overhead, to enhance the controllability. Experimental results demonstrate the efficacy of our framework even compared to diffusion-based methods. The generation speed remarkably reaches 12.8ms on an RTX 4090 GPU with PyTorch. The inference code and models are available at https://github.com/KwaiVGI/LivePortrait