 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control
Jul 03, 2024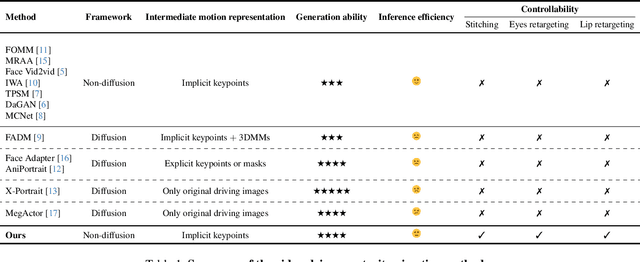
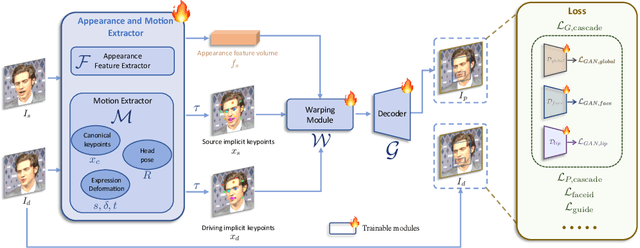
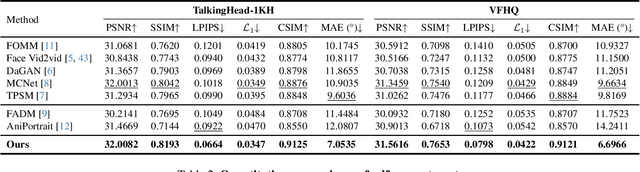
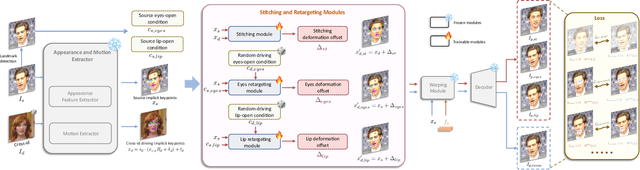
Portrait Animation aims to synthesize a lifelike video from a single source image, using it as an appearance reference, with motion (i.e., facial expressions and head pose) derived from a driving video, audio, text, or generation. Instead of following mainstream diffusion-based methods, we explore and extend the potential of the implicit-keypoint-based framework, which effectively balances computational efficiency and controllability. Building upon this, we develop a video-driven portrait animation framework named LivePortrait with a focus on better generalization, controllability, and efficiency for practical usage. To enhance the generation quality and generalization ability, we scale up the training data to about 69 million high-quality frames, adopt a mixed image-video training strategy, upgrade the network architecture, and design better motion transformation and optimization objectives. Additionally, we discover that compact implicit keypoints can effectively represent a kind of blendshapes and meticulously propose a stitching and two retargeting modules, which utilize a small MLP with negligible computational overhead, to enhance the controllability. Experimental results demonstrate the efficacy of our framework even compared to diffusion-based methods. The generation speed remarkably reaches 12.8ms on an RTX 4090 GPU with PyTorch. The inference code and models are available at https://github.com/KwaiVGI/LivePortrait
Unsupervised Deep Manifold Attributed Graph Embedding
Apr 27, 2021



Unsupervised attributed graph representation learning is challenging since both structural and feature information are required to be represented in the latent space. Existing methods concentrate on learning latent representation via reconstruction tasks, but cannot directly optimize representation and are prone to oversmoothing, thus limiting the applications on downstream tasks. To alleviate these issues, we propose a novel graph embedding framework named Deep Manifold Attributed Graph Embedding (DMAGE). A node-to-node geodesic similarity is proposed to compute the inter-node similarity between the data space and the latent space and then use Bergman divergence as loss function to minimize the difference between them. We then design a new network structure with fewer aggregation to alleviate the oversmoothing problem and incorporate graph structure augmentation to improve the representation's stability. Our proposed DMAGE surpasses state-of-the-art methods by a significant margin on three downstream tasks: unsupervised visualization, node clustering, and link prediction across four popular datasets.
AutoMix: Unveiling the Power of Mixup
Mar 24, 2021



Mixup-based data augmentation has achieved great success as regularizer for deep neural networks. However, existing mixup methods require explicitly designed mixup policies. In this paper, we present a flexible, general Automatic Mixup (AutoMix) framework which utilizes discriminative features to learn a sample mixing policy adaptively. We regard mixup as a pretext task and split it into two sub-problems: mixed samples generation and mixup classification. To this end, we design a lightweight mix block to generate synthetic samples based on feature maps and mix labels. Since the two sub-problems are in the nature of Expectation-Maximization (EM), we also propose a momentum training pipeline to optimize the mixup process and mixup classification process alternatively in an end-to-end fashion. Extensive experiments on six popular classification benchmarks show that AutoMix consistently outperforms other leading mixup methods and improves generalization abilities to downstream tasks. We hope AutoMix will motivate the community to rethink the role of mixup in representation learning. The code will be released soon.
Searching for Alignment in Face Recognition
Feb 10, 2021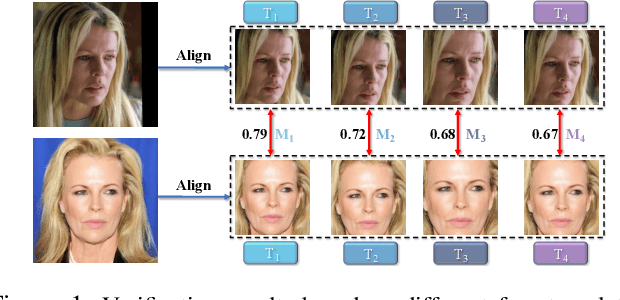

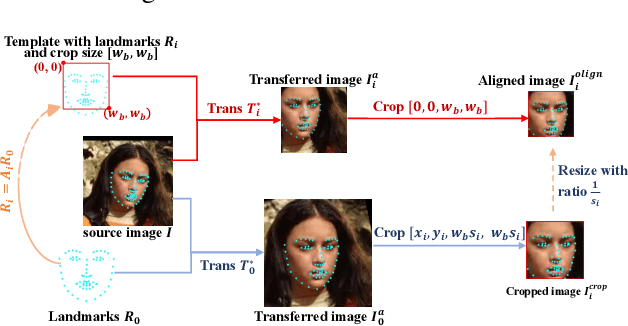
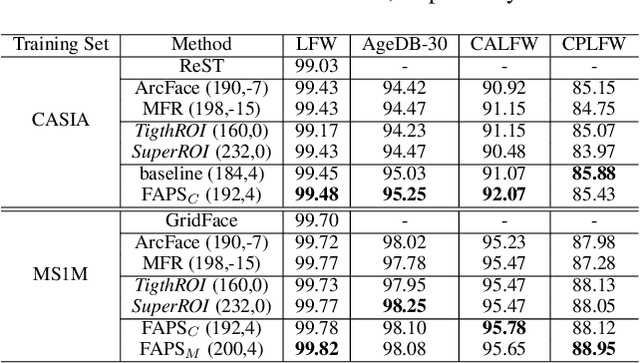
A standard pipeline of current face recognition frameworks consists of four individual steps: locating a face with a rough bounding box and several fiducial landmarks, aligning the face image using a pre-defined template, extracting representations and comparing. Among them, face detection, landmark detection and representation learning have long been studied and a lot of works have been proposed. As an essential step with a significant impact on recognition performance, the alignment step has attracted little attention. In this paper, we first explore and highlight the effects of different alignment templates on face recognition. Then, for the first time, we try to search for the optimal template automatically. We construct a well-defined searching space by decomposing the template searching into the crop size and vertical shift, and propose an efficient method Face Alignment Policy Search (FAPS). Besides, a well-designed benchmark is proposed to evaluate the searched policy. Experiments on our proposed benchmark validate the effectiveness of our method to improve face recognition performance.
Towards Fast, Accurate and Stable 3D Dense Face Alignment
Sep 21, 2020



Existing methods of 3D dense face alignment mainly concentrate on accuracy, thus limiting the scope of their practical applications. In this paper, we propose a novel regression framework which makes a balance among speed, accuracy and stability. Firstly, on the basis of a lightweight backbone, we propose a meta-joint optimization strategy to dynamically regress a small set of 3DMM parameters, which greatly enhances speed and accuracy simultaneously. To further improve the stability on videos, we present a virtual synthesis method to transform one still image to a short-video which incorporates in-plane and out-of-plane face moving. On the premise of high accuracy and stability, our model runs at over 50fps on a single CPU core and outperforms other state-of-the-art heavy models simultaneously. Experiments on several challenging datasets validate the efficiency of our method. Pre-trained models and code are available at https://github.com/cleardusk/3DDFA_V2.
Domain Balancing: Face Recognition on Long-Tailed Domains
Mar 30, 2020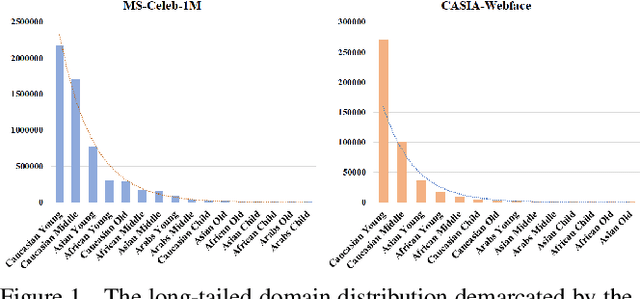
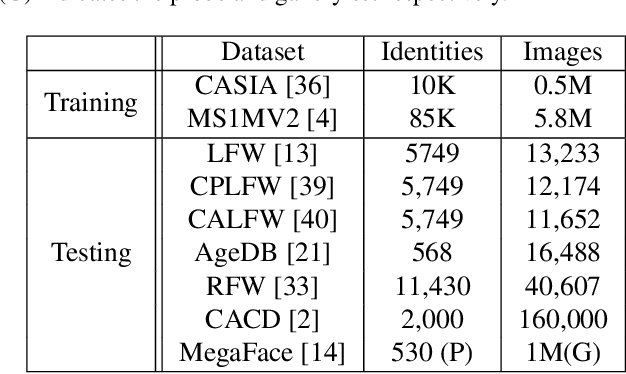
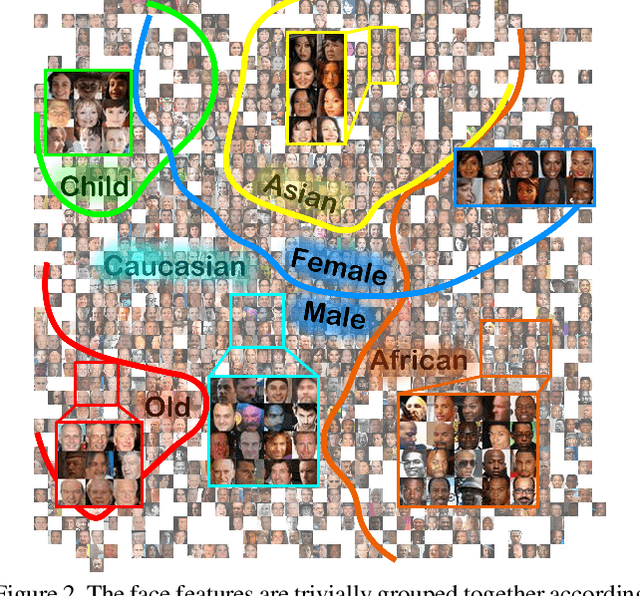
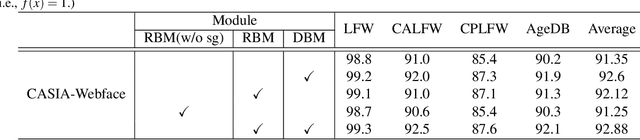
Long-tailed problem has been an important topic in face recognition task. However, existing methods only concentrate on the long-tailed distribution of classes. Differently, we devote to the long-tailed domain distribution problem, which refers to the fact that a small number of domains frequently appear while other domains far less existing. The key challenge of the problem is that domain labels are too complicated (related to race, age, pose, illumination, etc.) and inaccessible in real applications. In this paper, we propose a novel Domain Balancing (DB) mechanism to handle this problem. Specifically, we first propose a Domain Frequency Indicator (DFI) to judge whether a sample is from head domains or tail domains. Secondly, we formulate a light-weighted Residual Balancing Mapping (RBM) block to balance the domain distribution by adjusting the network according to DFI. Finally, we propose a Domain Balancing Margin (DBM) in the loss function to further optimize the feature space of the tail domains to improve generalization. Extensive analysis and experiments on several face recognition benchmarks demonstrate that the proposed method effectively enhances the generalization capacities and achieves superior performance.
Learning Meta Face Recognition in Unseen Domains
Mar 25, 2020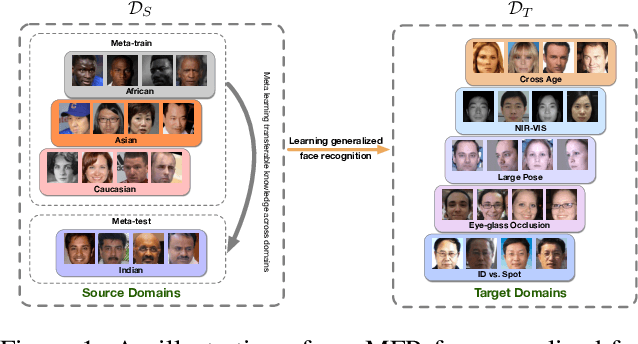
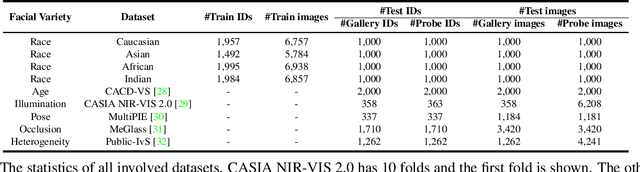
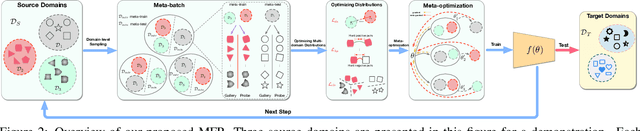

Face recognition systems are usually faced with unseen domains in real-world applications and show unsatisfactory performance due to their poor generalization. For example, a well-trained model on webface data cannot deal with the ID vs. Spot task in surveillance scenario. In this paper, we aim to learn a generalized model that can directly handle new unseen domains without any model updating. To this end, we propose a novel face recognition method via meta-learning named Meta Face Recognition (MFR). MFR synthesizes the source/target domain shift with a meta-optimization objective, which requires the model to learn effective representations not only on synthesized source domains but also on synthesized target domains. Specifically, we build domain-shift batches through a domain-level sampling strategy and get back-propagated gradients/meta-gradients on synthesized source/target domains by optimizing multi-domain distributions. The gradients and meta-gradients are further combined to update the model to improve generalization. Besides, we propose two benchmarks for generalized face recognition evaluation. Experiments on our benchmarks validate the generalization of our method compared to several baselines and other state-of-the-arts. The proposed benchmarks will be available at https://github.com/cleardusk/MFR.
Improving Face Anti-Spoofing by 3D Virtual Synthesis
Jan 02, 2019

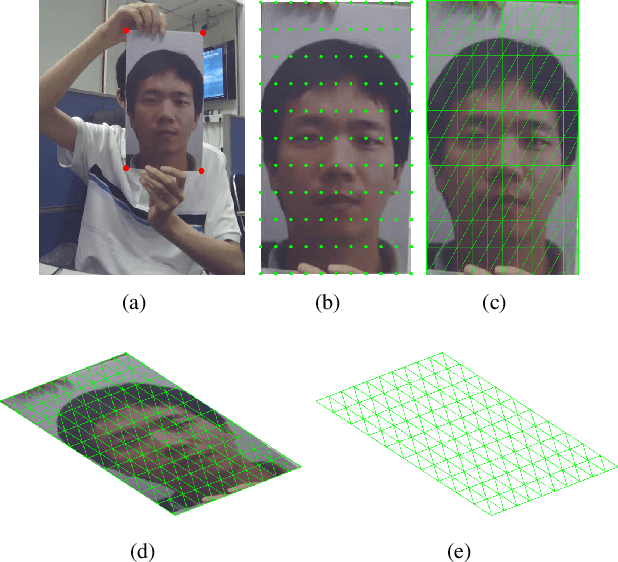
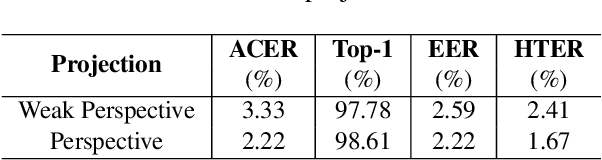
Face anti-spoofing is crucial for the security of face recognition systems. Learning based methods especially deep learning based methods need large-scale training samples to reduce overfitting. However, acquiring spoof data is very expensive since the live faces should be re-printed and re-captured in many views. In this paper, we present a method to synthesize virtual spoof data in 3D space to alleviate this problem. Specifically, we consider a printed photo as a flat surface and mesh it into a 3D object, which is then randomly bent and rotated in 3D space. Afterward, the transformed 3D photo is rendered through perspective projection as a virtual sample. The synthetic virtual samples can significantly boost the anti-spoofing performance when combined with a proposed data balancing strategy. Our promising results open up new possibilities for advancing face anti-spoofing using cheap and large-scale synthetic data.
Face Synthesis for Eyeglass-Robust Face Recognition
Jun 04, 2018



In the application of face recognition, eyeglasses could significantly degrade the recognition accuracy. A feasible method is to collect large-scale face images with eyeglasses for training deep learning methods. However, it is difficult to collect the images with and without glasses of the same identity, so that it is difficult to optimize the intra-variations caused by eyeglasses. In this paper, we propose to address this problem in a virtual synthesis manner. The high-fidelity face images with eyeglasses are synthesized based on 3D face model and 3D eyeglasses. Models based on deep learning methods are then trained on the synthesized eyeglass face dataset, achieving better performance than previous ones. Experiments on the real face database validate the effectiveness of our synthesized data for improving eyeglass face recognition performance.