 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeServing Large Language Models on Huawei CloudMatrix384
Jun 15, 2025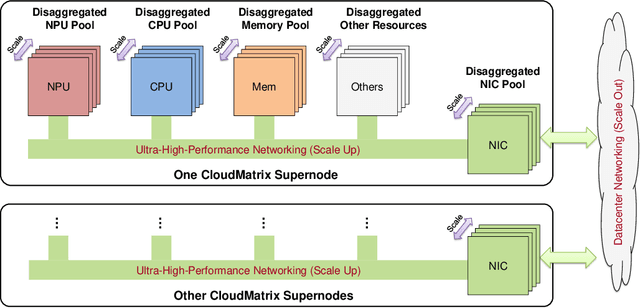
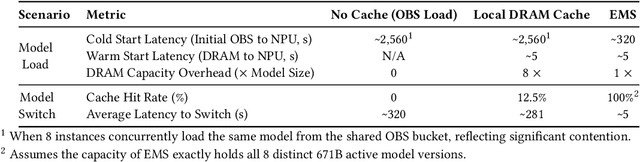
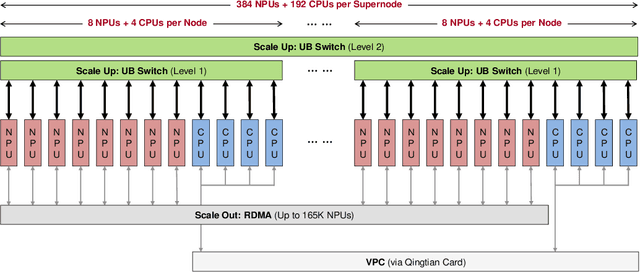
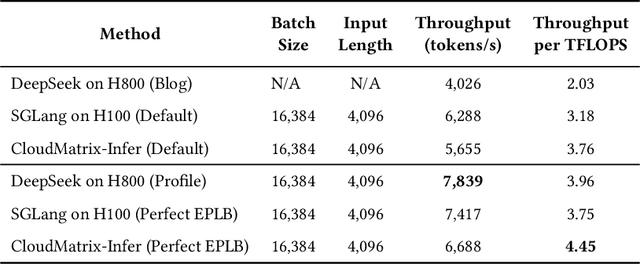
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
CoCo-Bench: A Comprehensive Code Benchmark For Multi-task Large Language Model Evaluation
Apr 29, 2025Large language models (LLMs) play a crucial role in software engineering, excelling in tasks like code generation and maintenance. However, existing benchmarks are often narrow in scope, focusing on a specific task and lack a comprehensive evaluation framework that reflects real-world applications. To address these gaps, we introduce CoCo-Bench (Comprehensive Code Benchmark), designed to evaluate LLMs across four critical dimensions: code understanding, code generation, code modification, and code review. These dimensions capture essential developer needs, ensuring a more systematic and representative evaluation. CoCo-Bench includes multiple programming languages and varying task difficulties, with rigorous manual review to ensure data quality and accuracy. Empirical results show that CoCo-Bench aligns with existing benchmarks while uncovering significant variations in model performance, effectively highlighting strengths and weaknesses. By offering a holistic and objective evaluation, CoCo-Bench provides valuable insights to guide future research and technological advancements in code-oriented LLMs, establishing a reliable benchmark for the field.
Distilling Temporal Knowledge with Masked Feature Reconstruction for 3D Object Detection
Jan 08, 2024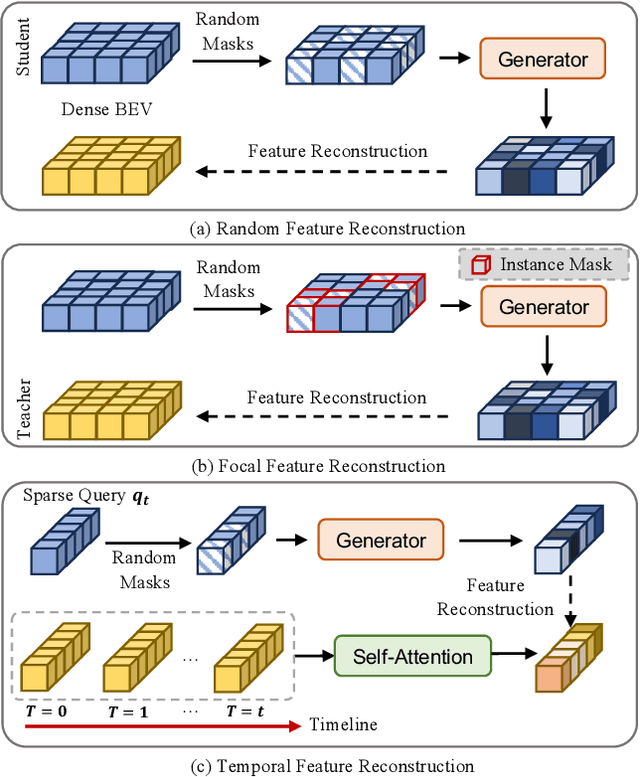
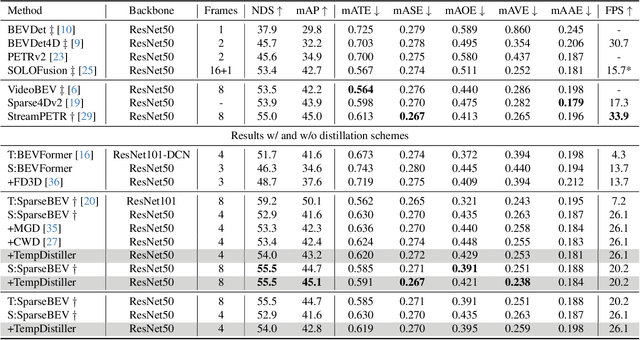
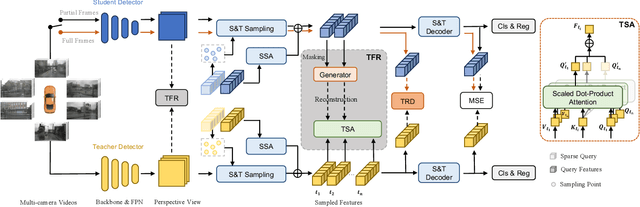
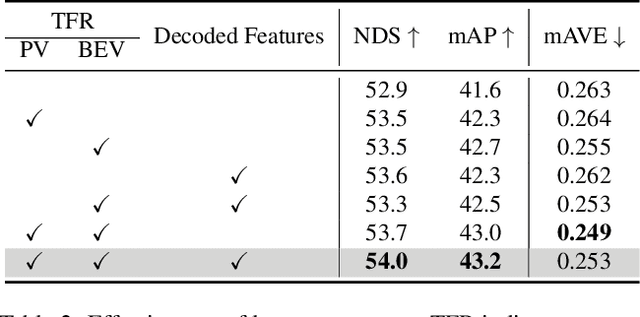
Striking a balance between precision and efficiency presents a prominent challenge in the bird's-eye-view (BEV) 3D object detection. Although previous camera-based BEV methods achieved remarkable performance by incorporating long-term temporal information, most of them still face the problem of low efficiency. One potential solution is knowledge distillation. Existing distillation methods only focus on reconstructing spatial features, while overlooking temporal knowledge. To this end, we propose TempDistiller, a Temporal knowledge Distiller, to acquire long-term memory from a teacher detector when provided with a limited number of frames. Specifically, a reconstruction target is formulated by integrating long-term temporal knowledge through self-attention operation applied to feature teachers. Subsequently, novel features are generated for masked student features via a generator. Ultimately, we utilize this reconstruction target to reconstruct the student features. In addition, we also explore temporal relational knowledge when inputting full frames for the student model. We verify the effectiveness of the proposed method on the nuScenes benchmark. The experimental results show our method obtain an enhancement of +1.6 mAP and +1.1 NDS compared to the baseline, a speed improvement of approximately 6 FPS after compressing temporal knowledge, and the most accurate velocity estimation.
BEV Lane Det: Fast Lane Detection on BEV Ground
Oct 12, 2022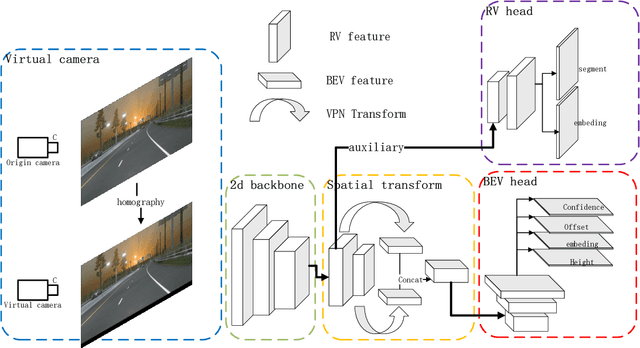
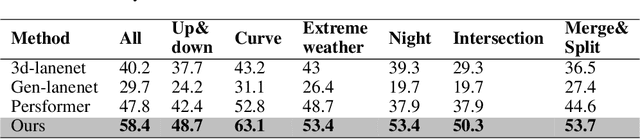
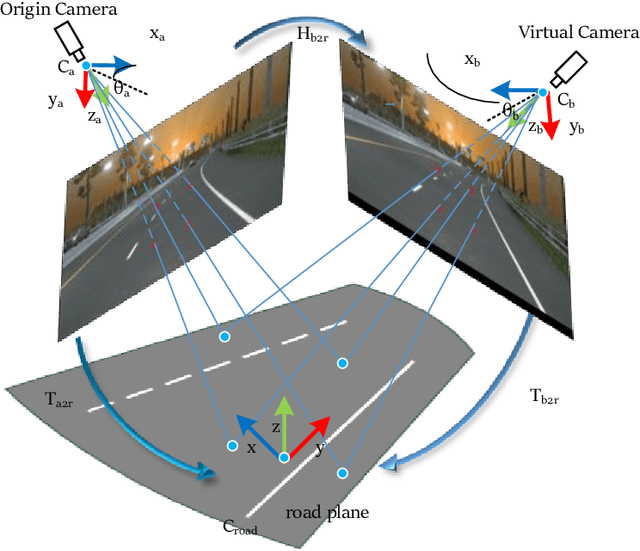

Recently, 3D lane detection has been an actively developing area in autonomous driving which is the key to routing the vehicle. This work proposes a deployment-oriented monocular 3D lane detector with only naive CNN and FC layers. This detector achieved state-of-the-art results on the Apollo 3D Lane Synthetic dataset and OpenLane real-world dataset with 96 FPS runtime speed. We conduct three techniques in our detector: (1) Virtual Camera eliminates the difference in poses of cameras mounted on different vehicles. (2) Spatial Feature Pyramid Transform as a light-weighed image-view to bird-eye view transformer can utilize scales of image-view featmaps. (3) Yolo Style Lane Representation makes a good balance between bird-eye view resolution and runtime speed. Meanwhile, it can reduce the inefficiency caused by the class imbalance due to the sparsity of the lane detection task during training. Combining these three techniques, we obtained a 58.4% F1-score on the OpenLane dataset, which is a 10.6% improvement over the baseline. On the Apollo dataset, we achieved an F1-score of 96.9%, which is 4% points of supremacy over the best on the leaderboard. The source code will release soon.
Domain Balancing: Face Recognition on Long-Tailed Domains
Mar 30, 2020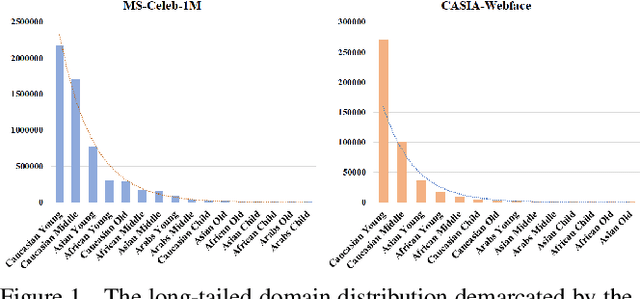
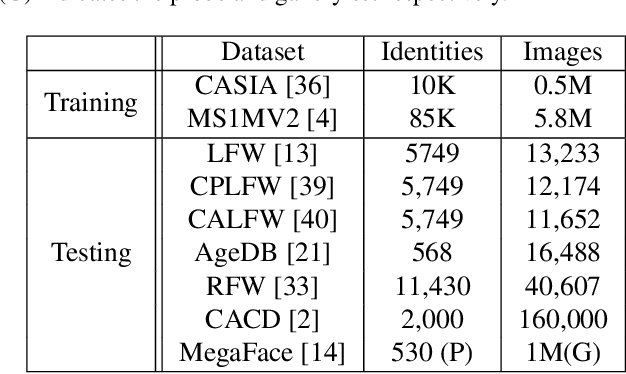
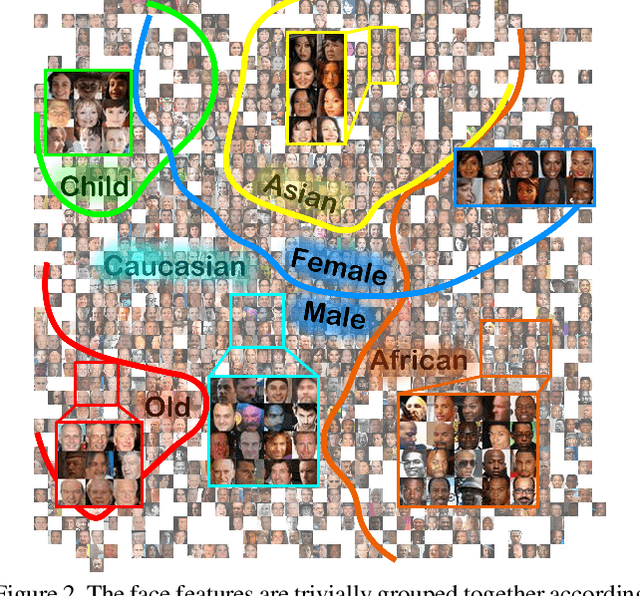
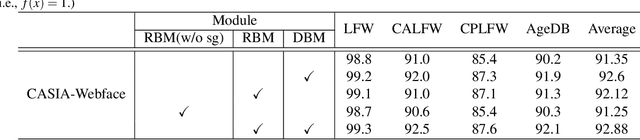
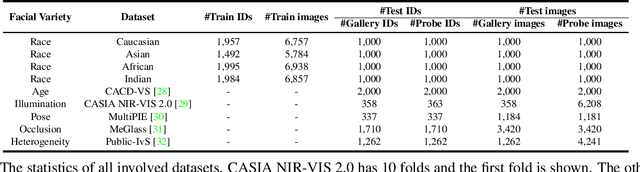
Long-tailed problem has been an important topic in face recognition task. However, existing methods only concentrate on the long-tailed distribution of classes. Differently, we devote to the long-tailed domain distribution problem, which refers to the fact that a small number of domains frequently appear while other domains far less existing. The key challenge of the problem is that domain labels are too complicated (related to race, age, pose, illumination, etc.) and inaccessible in real applications. In this paper, we propose a novel Domain Balancing (DB) mechanism to handle this problem. Specifically, we first propose a Domain Frequency Indicator (DFI) to judge whether a sample is from head domains or tail domains. Secondly, we formulate a light-weighted Residual Balancing Mapping (RBM) block to balance the domain distribution by adjusting the network according to DFI. Finally, we propose a Domain Balancing Margin (DBM) in the loss function to further optimize the feature space of the tail domains to improve generalization. Extensive analysis and experiments on several face recognition benchmarks demonstrate that the proposed method effectively enhances the generalization capacities and achieves superior performance.
Learning Meta Face Recognition in Unseen Domains
Mar 25, 2020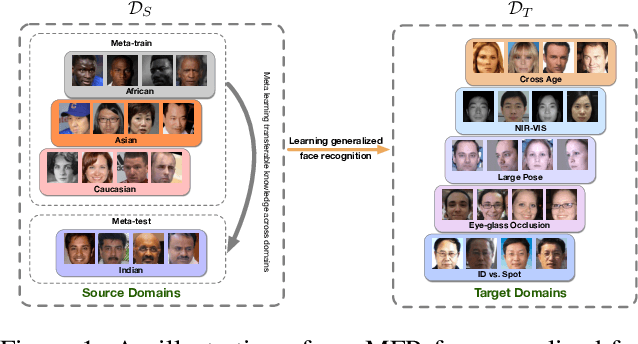
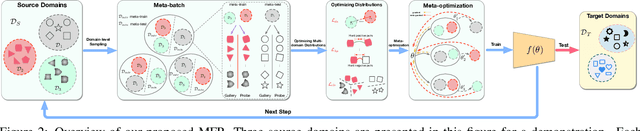

Face recognition systems are usually faced with unseen domains in real-world applications and show unsatisfactory performance due to their poor generalization. For example, a well-trained model on webface data cannot deal with the ID vs. Spot task in surveillance scenario. In this paper, we aim to learn a generalized model that can directly handle new unseen domains without any model updating. To this end, we propose a novel face recognition method via meta-learning named Meta Face Recognition (MFR). MFR synthesizes the source/target domain shift with a meta-optimization objective, which requires the model to learn effective representations not only on synthesized source domains but also on synthesized target domains. Specifically, we build domain-shift batches through a domain-level sampling strategy and get back-propagated gradients/meta-gradients on synthesized source/target domains by optimizing multi-domain distributions. The gradients and meta-gradients are further combined to update the model to improve generalization. Besides, we propose two benchmarks for generalized face recognition evaluation. Experiments on our benchmarks validate the generalization of our method compared to several baselines and other state-of-the-arts. The proposed benchmarks will be available at https://github.com/cleardusk/MFR.
Bypass Enhancement RGB Stream Model for Pedestrian Action Recognition of Autonomous Vehicles
Sep 02, 2019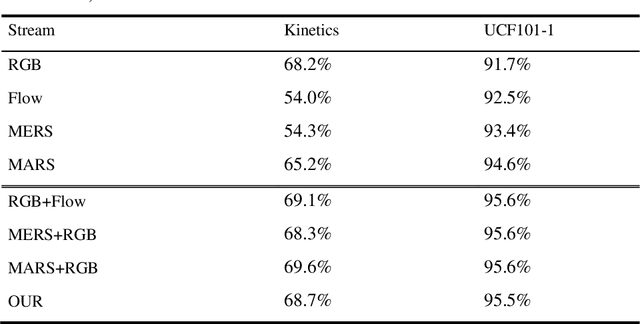

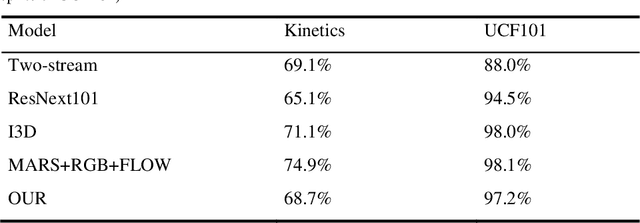
Pedestrian action recognition and intention prediction is one of the core issues in the field of autonomous driving. In this research field, action recognition is one of the key technologies. A large number of scholars have done a lot of work to im-prove the accuracy of the algorithm for the task. However, there are relatively few studies and improvements in the computational complexity of algorithms and sys-tem real-time. In the autonomous driving application scenario, the real-time per-formance and ultra-low latency of the algorithm are extremely important evalua-tion indicators, which are directly related to the availability and safety of the au-tonomous driving system. To this end, we construct a bypass enhanced RGB flow model, which combines the previous two-branch algorithm to extract RGB feature information and optical flow feature information respectively. In the train-ing phase, the two branches are merged by distillation method, and the bypass enhancement is combined in the inference phase to ensure accuracy. The real-time behavior of the behavior recognition algorithm is significantly improved on the premise that the accuracy does not decrease. Experiments confirm the superiority and effectiveness of our algorithm.
Action Recognition in Untrimmed Videos with Composite Self-Attention Two-Stream Framework
Sep 02, 2019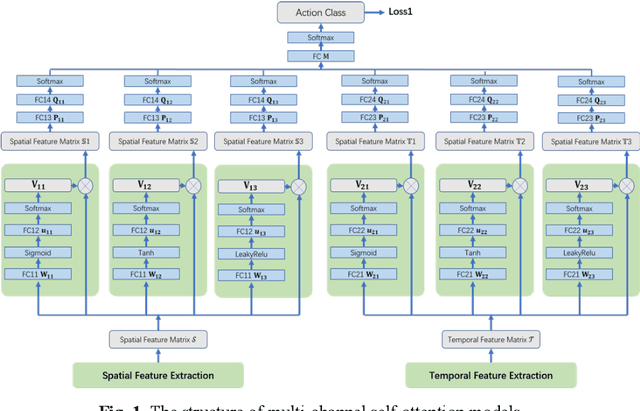
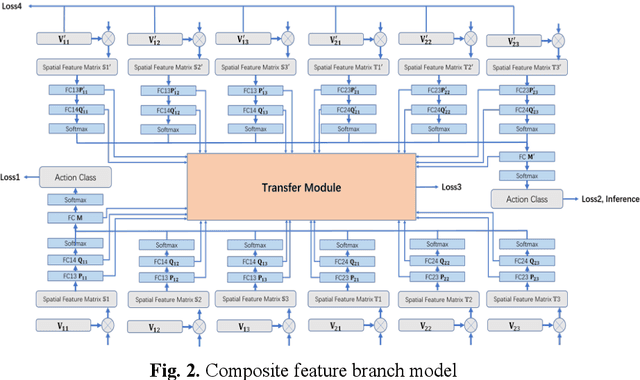
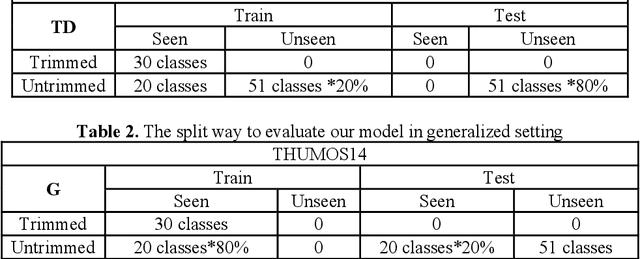
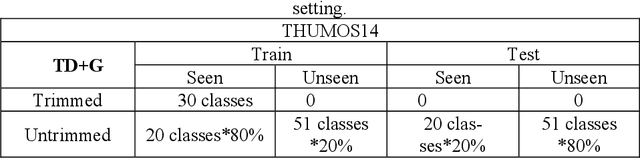
With the rapid development of deep learning algorithms, action recognition in video has achieved many important research results. One issue in action recognition, Zero-Shot Action Recognition (ZSAR), has recently attracted considerable attention, which classify new categories without any positive examples. Another difficulty in action recognition is that untrimmed data may seriously affect model performance. We propose a composite two-stream framework with a pre-trained model. Our proposed framework includes a classifier branch and a composite feature branch. The graph network model is adopted in each of the two branches, which effectively improves the feature extraction and reasoning ability of the framework. In the composite feature branch, a 3-channel self-attention models are constructed to weight each frame in the video and give more attention to the key frames. Each self-attention models channel outputs a set of attention weights to focus on a particular aspect of the video, and a set of attention weights corresponds to a one-dimensional vector. The 3-channel self-attention models can evaluate key frames from multiple aspects, and the output sets of attention weight vectors form an attention matrix, which effectively enhances the attention of key frames with strong correlation of action. This model can implement action recognition under zero-shot conditions, and has good recognition performance for untrimmed video data. Experimental results on relevant data sets confirm the validity of our model.
Cross-Enhancement Transform Two-Stream 3D ConvNets for Pedestrian Action Recognition of Autonomous Vehicles
Aug 19, 2019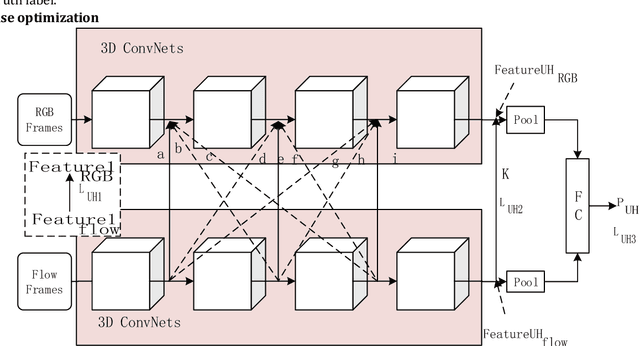
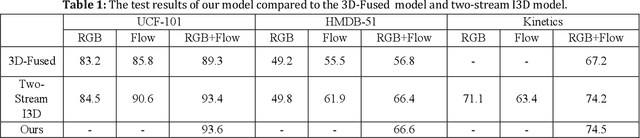
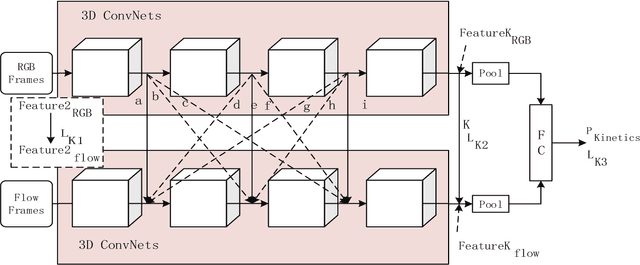
Action recognition is an important research topic in machine vision. It is widely used in many fields and is one of the key technologies in pedestrian behavior recognition and intention prediction in the field of autonomous driving. Based on the widely used 3D ConvNets algorithm, combined with Two-Stream Inflated algorithm and transfer learning algorithm, we construct a Cross-Enhancement Transform based Two-Stream 3D ConvNets algorithm. On the datasets with different data distribution characteristics, the performance of the algorithm is different, especially the performance of the RGB and optical flow stream in the two stream is different. For this case, we combine the data distribution characteristics on the specific dataset. As a teaching model, the stream with better performance in the two stream is used to assist in training another stream, and then two stream inference is made. We conducted experiments on the UCF-101, HMDB-51, and Kinetics data sets, and the experimental results confirmed the effectiveness of our algorithm.
A Novel Task-Oriented Text Corpus in Silent Speech Recognition and its Natural Language Generation Construction Method
Apr 19, 2019
Millions of people with severe speech disorders around the world may regain their communication capabilities through techniques of silent speech recognition (SSR). Using electroencephalography (EEG) as a biomarker for speech decoding has been popular for SSR. However, the lack of SSR text corpus has impeded the development of this technique. Here, we construct a novel task-oriented text corpus, which is utilized in the field of SSR. In the process of construction, we propose a task-oriented hybrid construction method based on natural language generation algorithm. The algorithm focuses on the strategy of data-to-text generation, and has two advantages including linguistic quality and high diversity. These two advantages use template-based method and deep neural networks respectively. In an SSR experiment with the generated text corpus, analysis results show that the performance of our hybrid construction method outperforms the pure method such as template-based natural language generation or neural natural language generation models.