 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Recognition in Untrimmed Videos with Composite Self-Attention Two-Stream Framework
Paper and Code
Sep 02, 2019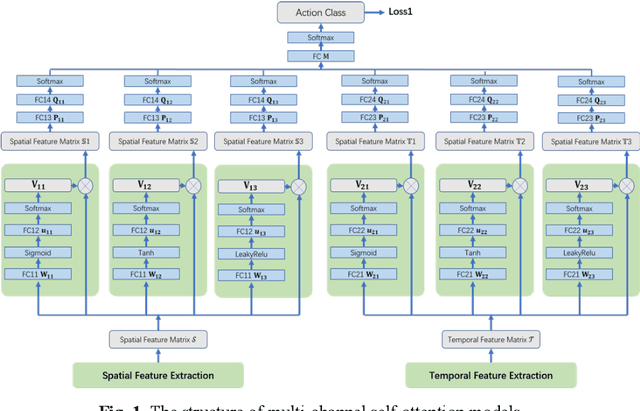
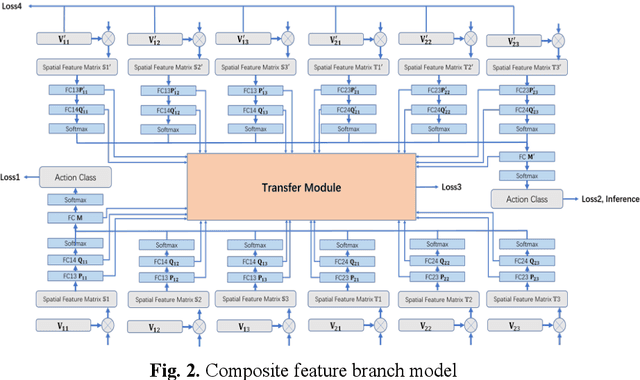
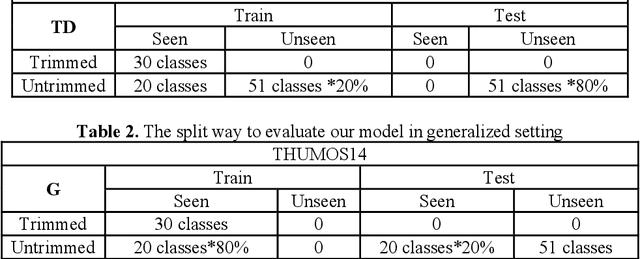
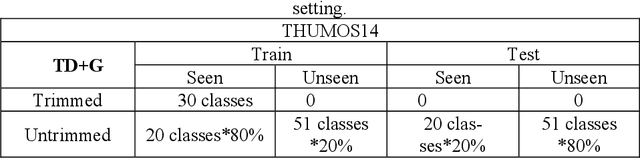
With the rapid development of deep learning algorithms, action recognition in video has achieved many important research results. One issue in action recognition, Zero-Shot Action Recognition (ZSAR), has recently attracted considerable attention, which classify new categories without any positive examples. Another difficulty in action recognition is that untrimmed data may seriously affect model performance. We propose a composite two-stream framework with a pre-trained model. Our proposed framework includes a classifier branch and a composite feature branch. The graph network model is adopted in each of the two branches, which effectively improves the feature extraction and reasoning ability of the framework. In the composite feature branch, a 3-channel self-attention models are constructed to weight each frame in the video and give more attention to the key frames. Each self-attention models channel outputs a set of attention weights to focus on a particular aspect of the video, and a set of attention weights corresponds to a one-dimensional vector. The 3-channel self-attention models can evaluate key frames from multiple aspects, and the output sets of attention weight vectors form an attention matrix, which effectively enhances the attention of key frames with strong correlation of action. This model can implement action recognition under zero-shot conditions, and has good recognition performance for untrimmed video data. Experimental results on relevant data sets confirm the validity of our model.