 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemeBLIP2: A novel lightweight multimodal system to detect harmful memes
Apr 29, 2025



Memes often merge visuals with brief text to share humor or opinions, yet some memes contain harmful messages such as hate speech. In this paper, we introduces MemeBLIP2, a light weight multimodal system that detects harmful memes by combining image and text features effectively. We build on previous studies by adding modules that align image and text representations into a shared space and fuse them for better classification. Using BLIP-2 as the core vision-language model, our system is evaluated on the PrideMM datasets. The results show that MemeBLIP2 can capture subtle cues in both modalities, even in cases with ironic or culturally specific content, thereby improving the detection of harmful material.
Bypass Enhancement RGB Stream Model for Pedestrian Action Recognition of Autonomous Vehicles
Sep 02, 2019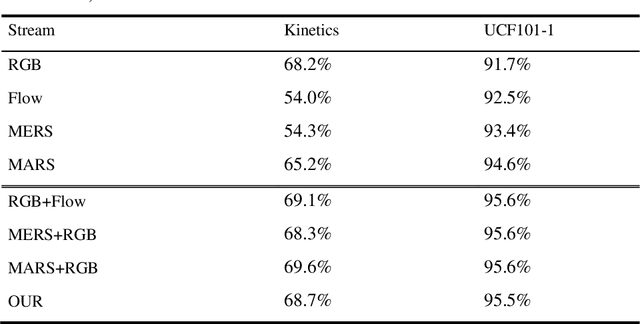

Pedestrian action recognition and intention prediction is one of the core issues in the field of autonomous driving. In this research field, action recognition is one of the key technologies. A large number of scholars have done a lot of work to im-prove the accuracy of the algorithm for the task. However, there are relatively few studies and improvements in the computational complexity of algorithms and sys-tem real-time. In the autonomous driving application scenario, the real-time per-formance and ultra-low latency of the algorithm are extremely important evalua-tion indicators, which are directly related to the availability and safety of the au-tonomous driving system. To this end, we construct a bypass enhanced RGB flow model, which combines the previous two-branch algorithm to extract RGB feature information and optical flow feature information respectively. In the train-ing phase, the two branches are merged by distillation method, and the bypass enhancement is combined in the inference phase to ensure accuracy. The real-time behavior of the behavior recognition algorithm is significantly improved on the premise that the accuracy does not decrease. Experiments confirm the superiority and effectiveness of our algorithm.
Action Recognition in Untrimmed Videos with Composite Self-Attention Two-Stream Framework
Sep 02, 2019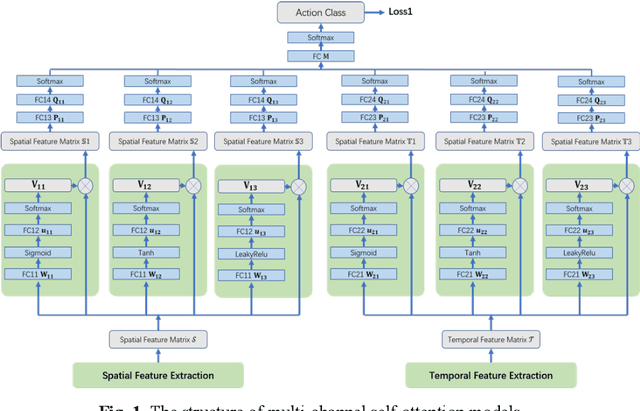
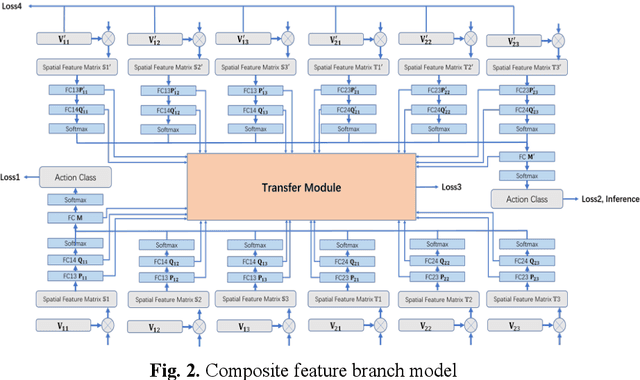
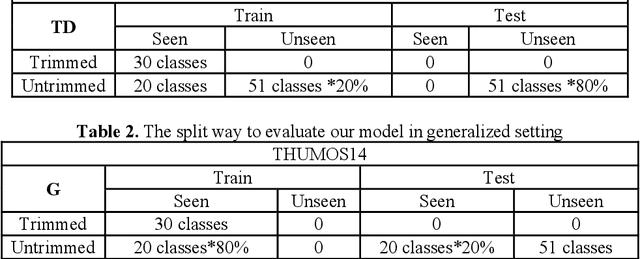
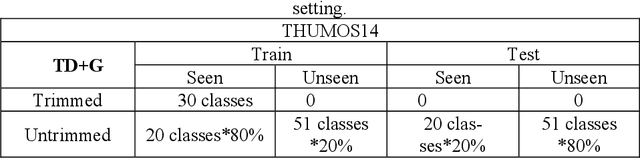
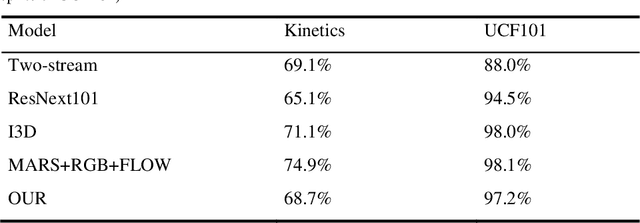
With the rapid development of deep learning algorithms, action recognition in video has achieved many important research results. One issue in action recognition, Zero-Shot Action Recognition (ZSAR), has recently attracted considerable attention, which classify new categories without any positive examples. Another difficulty in action recognition is that untrimmed data may seriously affect model performance. We propose a composite two-stream framework with a pre-trained model. Our proposed framework includes a classifier branch and a composite feature branch. The graph network model is adopted in each of the two branches, which effectively improves the feature extraction and reasoning ability of the framework. In the composite feature branch, a 3-channel self-attention models are constructed to weight each frame in the video and give more attention to the key frames. Each self-attention models channel outputs a set of attention weights to focus on a particular aspect of the video, and a set of attention weights corresponds to a one-dimensional vector. The 3-channel self-attention models can evaluate key frames from multiple aspects, and the output sets of attention weight vectors form an attention matrix, which effectively enhances the attention of key frames with strong correlation of action. This model can implement action recognition under zero-shot conditions, and has good recognition performance for untrimmed video data. Experimental results on relevant data sets confirm the validity of our model.
Cross-Enhancement Transform Two-Stream 3D ConvNets for Pedestrian Action Recognition of Autonomous Vehicles
Aug 19, 2019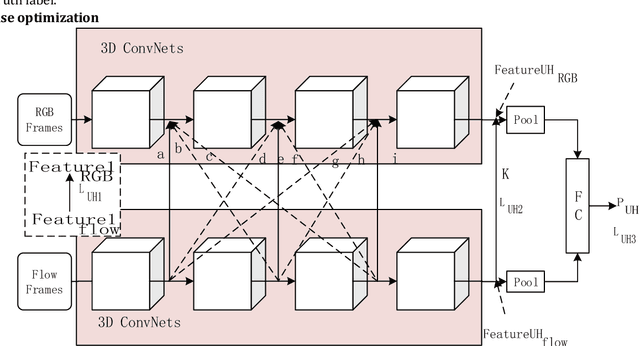
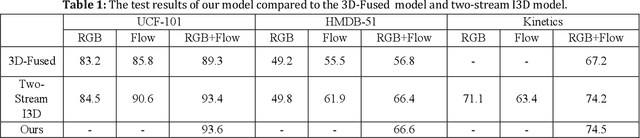
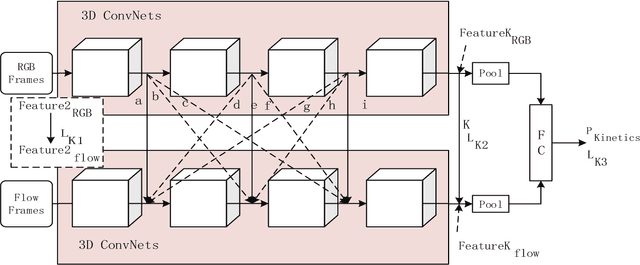
Action recognition is an important research topic in machine vision. It is widely used in many fields and is one of the key technologies in pedestrian behavior recognition and intention prediction in the field of autonomous driving. Based on the widely used 3D ConvNets algorithm, combined with Two-Stream Inflated algorithm and transfer learning algorithm, we construct a Cross-Enhancement Transform based Two-Stream 3D ConvNets algorithm. On the datasets with different data distribution characteristics, the performance of the algorithm is different, especially the performance of the RGB and optical flow stream in the two stream is different. For this case, we combine the data distribution characteristics on the specific dataset. As a teaching model, the stream with better performance in the two stream is used to assist in training another stream, and then two stream inference is made. We conducted experiments on the UCF-101, HMDB-51, and Kinetics data sets, and the experimental results confirmed the effectiveness of our algorithm.