 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Data Mixing from the Perspective of Large Language Models
Apr 09, 2026Data mixing strategy is essential for large language model (LLM) training. Empirical evidence shows that inappropriate strategies can significantly reduce generalization. Although recent methods have improved empirical performance, several fundamental questions remain open: what constitutes a domain, whether human and model perceptions of domains are aligned, and how domain weighting influences generalization. We address these questions by establishing formal connections between gradient dynamics and domain distributions, offering a theoretical framework that clarifies the role of domains in training dynamics. Building on this analysis, we introduce DoGraph, a reweighting framework that formulates data scheduling as a graph-constrained optimization problem. Extensive experiments on GPT-2 models of varying scales demonstrate that DoGraph consistently achieves competitive performance.
Poisson-MNL Bandit: Nearly Optimal Dynamic Joint Assortment and Pricing with Decision-Dependent Customer Arrivals
Feb 18, 2026We study dynamic joint assortment and pricing where a seller updates decisions at regular accounting/operating intervals to maximize the cumulative per-period revenue over a horizon $T$. In many settings, assortment and prices affect not only what an arriving customer buys but also how many customers arrive within the period, whereas classical multinomial logit (MNL) models assume arrivals as fixed, potentially leading to suboptimal decisions. We propose a Poisson-MNL model that couples a contextual MNL choice model with a Poisson arrival model whose rate depends on the offered assortment and prices. Building on this model, we develop an efficient algorithm PMNL based on the idea of upper confidence bound (UCB). We establish its (near) optimality by proving a non-asymptotic regret bound of order $\sqrt{T\log{T}}$ and a matching lower bound (up to $\log T$). Simulation studies underscore the importance of accounting for the dependency of arrival rates on assortment and pricing: PMNL effectively learns customer choice and arrival models and provides joint assortment-pricing decisions that outperform others that assume fixed arrival rates.
BFTS: Thompson Sampling with Bayesian Additive Regression Trees
Feb 08, 2026Contextual bandits are a core technology for personalized mobile health interventions, where decision-making requires adapting to complex, non-linear user behaviors. While Thompson Sampling (TS) is a preferred strategy for these problems, its performance hinges on the quality of the underlying reward model. Standard linear models suffer from high bias, while neural network approaches are often brittle and difficult to tune in online settings. Conversely, tree ensembles dominate tabular data prediction but typically rely on heuristic uncertainty quantification, lacking a principled probabilistic basis for TS. We propose Bayesian Forest Thompson Sampling (BFTS), the first contextual bandit algorithm to integrate Bayesian Additive Regression Trees (BART), a fully probabilistic sum-of-trees model, directly into the exploration loop. We prove that BFTS is theoretically sound, deriving an information-theoretic Bayesian regret bound of $\tilde{O}(\sqrt{T})$. As a complementary result, we establish frequentist minimax optimality for a "feel-good" variant, confirming the structural suitability of BART priors for non-parametric bandits. Empirically, BFTS achieves state-of-the-art regret on tabular benchmarks with near-nominal uncertainty calibration. Furthermore, in an offline policy evaluation on the Drink Less micro-randomized trial, BFTS improves engagement rates by over 30% compared to the deployed policy, demonstrating its practical effectiveness for behavioral interventions.
Interpolative Decoding: Exploring the Spectrum of Personality Traits in LLMs
Dec 23, 2025
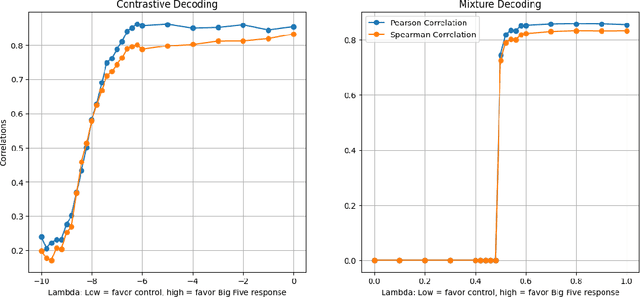
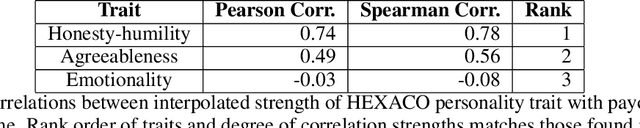
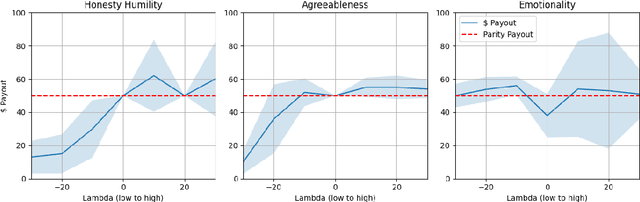
Recent research has explored using very large language models (LLMs) as proxies for humans in tasks such as simulation, surveys, and studies. While LLMs do not possess a human psychology, they often can emulate human behaviors with sufficiently high fidelity to drive simulations to test human behavioral hypotheses, exhibiting more nuance and range than the rule-based agents often employed in behavioral economics. One key area of interest is the effect of personality on decision making, but the requirement that a prompt must be created for every tested personality profile introduces experimental overhead and degrades replicability. To address this issue, we leverage interpolative decoding, representing each dimension of personality as a pair of opposed prompts and employing an interpolation parameter to simulate behavior along the dimension. We show that interpolative decoding reliably modulates scores along each of the Big Five dimensions. We then show how interpolative decoding causes LLMs to mimic human decision-making behavior in economic games, replicating results from human psychological research. Finally, we present preliminary results of our efforts to ``twin'' individual human players in a collaborative game through systematic search for points in interpolation space that cause the system to replicate actions taken by the human subject.
DiffuGR: Generative Document Retrieval with Diffusion Language Models
Nov 19, 2025Generative retrieval (GR) re-frames document retrieval as a sequence-based document identifier (DocID) generation task, memorizing documents with model parameters and enabling end-to-end retrieval without explicit indexing. Existing GR methods are based on auto-regressive generative models, i.e., the token generation is performed from left to right. However, such auto-regressive methods suffer from: (1) mismatch between DocID generation and natural language generation, e.g., an incorrect DocID token generated in early left steps would lead to totally erroneous retrieval; and (2) failure to balance the trade-off between retrieval efficiency and accuracy dynamically, which is crucial for practical applications. To address these limitations, we propose generative document retrieval with diffusion language models, dubbed DiffuGR. It models DocID generation as a discrete diffusion process: during training, DocIDs are corrupted through a stochastic masking process, and a diffusion language model is learned to recover them under a retrieval-aware objective. For inference, DiffuGR attempts to generate DocID tokens in parallel and refines them through a controllable number of denoising steps. In contrast to conventional left-to-right auto-regressive decoding, DiffuGR provides a novel mechanism to first generate more confident DocID tokens and refine the generation through diffusion-based denoising. Moreover, DiffuGR also offers explicit runtime control over the qualitylatency tradeoff. Extensive experiments on benchmark retrieval datasets show that DiffuGR is competitive with strong auto-regressive generative retrievers, while offering flexible speed and accuracy tradeoffs through variable denoising budgets. Overall, our results indicate that non-autoregressive diffusion models are a practical and effective alternative for generative document retrieval.
SOAEsV2-7B/72B: Full-Pipeline Optimization for State-Owned Enterprise LLMs via Continual Pre-Training, Domain-Progressive SFT and Distillation-Enhanced Speculative Decoding
May 07, 2025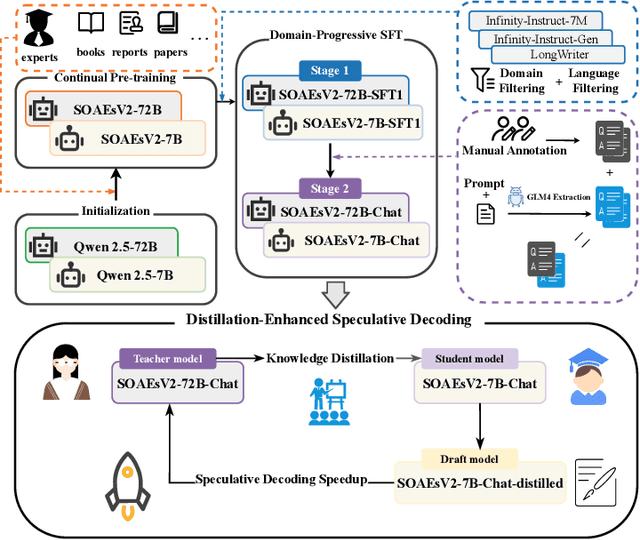
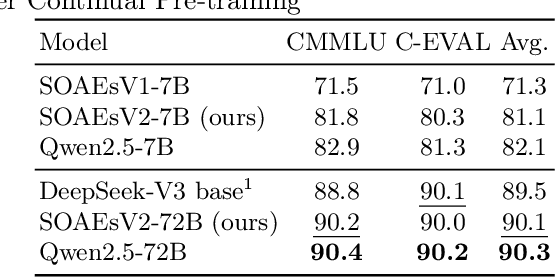
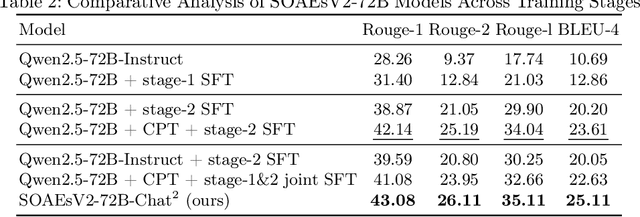
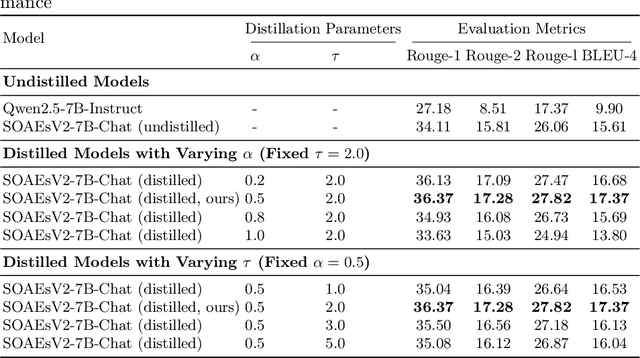
This study addresses key challenges in developing domain-specific large language models (LLMs) for Chinese state-owned assets and enterprises (SOAEs), where current approaches face three limitations: 1) constrained model capacity that limits knowledge integration and cross-task adaptability; 2) excessive reliance on domain-specific supervised fine-tuning (SFT) data, which neglects the broader applicability of general language patterns; and 3) inefficient inference acceleration for large models processing long contexts. In this work, we propose SOAEsV2-7B/72B, a specialized LLM series developed via a three-phase framework: 1) continual pre-training integrates domain knowledge while retaining base capabilities; 2) domain-progressive SFT employs curriculum-based learning strategy, transitioning from weakly relevant conversational data to expert-annotated SOAEs datasets to optimize domain-specific tasks; 3) distillation-enhanced speculative decoding accelerates inference via logit distillation between 72B target and 7B draft models, achieving 1.39-1.52$\times$ speedup without quality loss. Experimental results demonstrate that our domain-specific pre-training phase maintains 99.8% of original general language capabilities while significantly improving domain performance, resulting in a 1.08$\times$ improvement in Rouge-1 score and a 1.17$\times$ enhancement in BLEU-4 score. Ablation studies further show that domain-progressive SFT outperforms single-stage training, achieving 1.02$\times$ improvement in Rouge-1 and 1.06$\times$ in BLEU-4. Our work introduces a comprehensive, full-pipeline approach for optimizing SOAEs LLMs, bridging the gap between general language capabilities and domain-specific expertise.
CoCo-Bench: A Comprehensive Code Benchmark For Multi-task Large Language Model Evaluation
Apr 29, 2025Large language models (LLMs) play a crucial role in software engineering, excelling in tasks like code generation and maintenance. However, existing benchmarks are often narrow in scope, focusing on a specific task and lack a comprehensive evaluation framework that reflects real-world applications. To address these gaps, we introduce CoCo-Bench (Comprehensive Code Benchmark), designed to evaluate LLMs across four critical dimensions: code understanding, code generation, code modification, and code review. These dimensions capture essential developer needs, ensuring a more systematic and representative evaluation. CoCo-Bench includes multiple programming languages and varying task difficulties, with rigorous manual review to ensure data quality and accuracy. Empirical results show that CoCo-Bench aligns with existing benchmarks while uncovering significant variations in model performance, effectively highlighting strengths and weaknesses. By offering a holistic and objective evaluation, CoCo-Bench provides valuable insights to guide future research and technological advancements in code-oriented LLMs, establishing a reliable benchmark for the field.
GeoUni: A Unified Model for Generating Geometry Diagrams, Problems and Problem Solutions
Apr 14, 2025
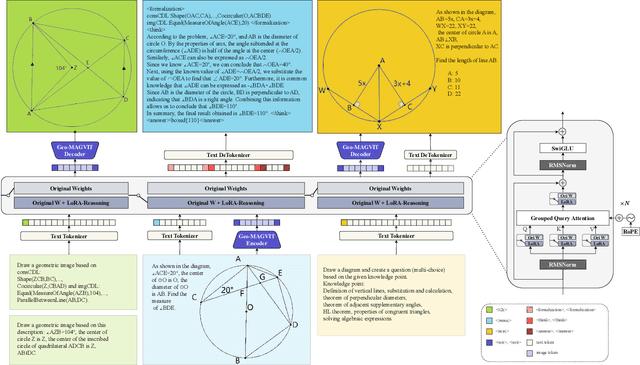

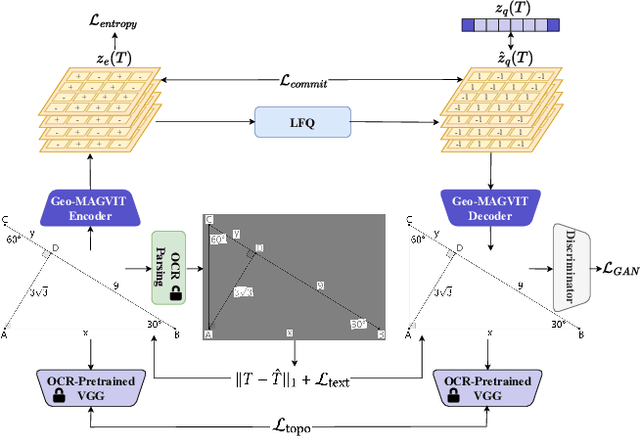
We propose GeoUni, the first unified geometry expert model capable of generating problem solutions and diagrams within a single framework in a way that enables the creation of unique and individualized geometry problems. Traditionally, solving geometry problems and generating diagrams have been treated as separate tasks in machine learning, with no models successfully integrating both to support problem creation. However, we believe that mastery in geometry requires frictionless integration of all of these skills, from solving problems to visualizing geometric relationships, and finally, crafting tailored problems. Our extensive experiments demonstrate that GeoUni, with only 1.5B parameters, achieves performance comparable to larger models such as DeepSeek-R1 with 671B parameters in geometric reasoning tasks. GeoUni also excels in generating precise geometric diagrams, surpassing both text-to-image models and unified models, including the GPT-4o image generation. Most importantly, GeoUni is the only model capable of successfully generating textual problems with matching diagrams based on specific knowledge points, thus offering a wider range of capabilities that extend beyond current models.
OpenCSG Chinese Corpus: A Series of High-quality Chinese Datasets for LLM Training
Jan 14, 2025Large language models (LLMs) have demonstrated remarkable capabilities, but their success heavily relies on the quality of pretraining corpora. For Chinese LLMs, the scarcity of high-quality Chinese datasets presents a significant challenge, often limiting their performance. To address this issue, we propose the OpenCSG Chinese Corpus, a series of high-quality datasets specifically designed for LLM pretraining, post-training, and fine-tuning. This corpus includes Fineweb-edu-chinese, Fineweb-edu-chinese-v2, Cosmopedia-chinese, and Smoltalk-chinese, each with distinct characteristics: Fineweb-edu datasets focus on filtered, high-quality content derived from diverse Chinese web sources; Cosmopedia-chinese provides synthetic, textbook-style data for knowledge-intensive training; and Smoltalk-chinese emphasizes stylistic and diverse chat-format data. The OpenCSG Chinese Corpus is characterized by its high-quality text, diverse coverage across domains, and scalable, reproducible data curation processes. Additionally, we conducted extensive experimental analyses, including evaluations on smaller parameter models, which demonstrated significant performance improvements in tasks such as C-Eval, showcasing the effectiveness of the corpus for training Chinese LLMs.
An Experimental Evaluation of Imputation Models for Spatial-Temporal Traffic Data
Dec 06, 2024



Traffic data imputation is a critical preprocessing step in intelligent transportation systems, enabling advanced transportation services. Despite significant advancements in this field, selecting the most suitable model for practical applications remains challenging due to three key issues: 1) incomprehensive consideration of missing patterns that describe how data loss along spatial and temporal dimensions, 2) the lack of test on standardized datasets, and 3) insufficient evaluations. To this end, we first propose practice-oriented taxonomies for missing patterns and imputation models, systematically identifying all possible forms of real-world traffic data loss and analyzing the characteristics of existing models. Furthermore, we introduce a unified benchmarking pipeline to comprehensively evaluate 10 representative models across various missing patterns and rates. This work aims to provide a holistic understanding of traffic data imputation research and serve as a practical guideline.