 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferTraj: A Vehicle Trajectory Learning Model for Region and Task Transferability
May 19, 2025Vehicle GPS trajectories provide valuable movement information that supports various downstream tasks and applications. A desirable trajectory learning model should be able to transfer across regions and tasks without retraining, avoiding the need to maintain multiple specialized models and subpar performance with limited training data. However, each region has its unique spatial features and contexts, which are reflected in vehicle movement patterns and difficult to generalize. Additionally, transferring across different tasks faces technical challenges due to the varying input-output structures required for each task. Existing efforts towards transferability primarily involve learning embedding vectors for trajectories, which perform poorly in region transfer and require retraining of prediction modules for task transfer. To address these challenges, we propose TransferTraj, a vehicle GPS trajectory learning model that excels in both region and task transferability. For region transferability, we introduce RTTE as the main learnable module within TransferTraj. It integrates spatial, temporal, POI, and road network modalities of trajectories to effectively manage variations in spatial context distribution across regions. It also introduces a TRIE module for incorporating relative information of spatial features and a spatial context MoE module for handling movement patterns in diverse contexts. For task transferability, we propose a task-transferable input-output scheme that unifies the input-output structure of different tasks into the masking and recovery of modalities and trajectory points. This approach allows TransferTraj to be pre-trained once and transferred to different tasks without retraining. Extensive experiments on three real-world vehicle trajectory datasets under task transfer, zero-shot, and few-shot region transfer, validating TransferTraj's effectiveness.
An Experimental Evaluation of Imputation Models for Spatial-Temporal Traffic Data
Dec 06, 2024



Traffic data imputation is a critical preprocessing step in intelligent transportation systems, enabling advanced transportation services. Despite significant advancements in this field, selecting the most suitable model for practical applications remains challenging due to three key issues: 1) incomprehensive consideration of missing patterns that describe how data loss along spatial and temporal dimensions, 2) the lack of test on standardized datasets, and 3) insufficient evaluations. To this end, we first propose practice-oriented taxonomies for missing patterns and imputation models, systematically identifying all possible forms of real-world traffic data loss and analyzing the characteristics of existing models. Furthermore, we introduce a unified benchmarking pipeline to comprehensively evaluate 10 representative models across various missing patterns and rates. This work aims to provide a holistic understanding of traffic data imputation research and serve as a practical guideline.
PTR: A Pre-trained Language Model for Trajectory Recovery
Oct 18, 2024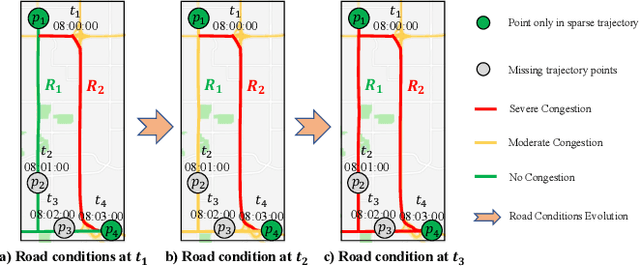



Spatiotemporal trajectory data is vital for web-of-things services and is extensively collected and analyzed by web-based hardware and platforms. However, issues such as service interruptions and network instability often lead to sparsely recorded trajectories, resulting in a loss of detailed movement data. As a result, recovering these trajectories to restore missing information becomes essential. Despite progress, several challenges remain unresolved. First, the lack of large-scale dense trajectory data hampers the performance of existing deep learning methods, which rely heavily on abundant data for supervised training. Second, current methods struggle to generalize across sparse trajectories with varying sampling intervals, necessitating separate re-training for each interval and increasing computational costs. Third, external factors crucial for the recovery of missing points are not fully incorporated. To address these challenges, we propose a framework called PTR. This framework mitigates the issue of limited dense trajectory data by leveraging the capabilities of pre-trained language models (PLMs). PTR incorporates an explicit trajectory prompt and is trained on datasets with multiple sampling intervals, enabling it to generalize effectively across different intervals in sparse trajectories. To capture external factors, we introduce an implicit trajectory prompt that models road conditions, providing richer information for recovering missing points. Additionally, we present a trajectory embedder that encodes trajectory points and transforms the embeddings of both observed and missing points into a format comprehensible to PLMs. Experimental results on two public trajectory datasets with three sampling intervals demonstrate the efficacy and scalability of PTR.
Micro-Macro Spatial-Temporal Graph-based Encoder-Decoder for Map-Constrained Trajectory Recovery
Apr 29, 2024Recovering intermediate missing GPS points in a sparse trajectory, while adhering to the constraints of the road network, could offer deep insights into users' moving behaviors in intelligent transportation systems. Although recent studies have demonstrated the advantages of achieving map-constrained trajectory recovery via an end-to-end manner, they still face two significant challenges. Firstly, existing methods are mostly sequence-based models. It is extremely hard for them to comprehensively capture the micro-semantics of individual trajectory, including the information of each GPS point and the movement between two GPS points. Secondly, existing approaches ignore the impact of the macro-semantics, i.e., the road conditions and the people's shared travel preferences reflected by a group of trajectories. To address the above challenges, we propose a Micro-Macro Spatial-Temporal Graph-based Encoder-Decoder (MM-STGED). Specifically, we model each trajectory as a graph to efficiently describe the micro-semantics of trajectory and design a novel message-passing mechanism to learn trajectory representations. Additionally, we extract the macro-semantics of trajectories and further incorporate them into a well-designed graph-based decoder to guide trajectory recovery. Extensive experiments conducted on sparse trajectories with three different sampling intervals that are respectively constructed from two real-world trajectory datasets demonstrate the superiority of our proposed model.
Diff-RNTraj: A Structure-aware Diffusion Model for Road Network-constrained Trajectory Generation
Feb 12, 2024Trajectory data is essential for various applications as it records the movement of vehicles. However, publicly available trajectory datasets remain limited in scale due to privacy concerns, which hinders the development of trajectory data mining and trajectory-based applications. To address this issue, some methods for generating synthetic trajectories have been proposed to expand the scale of the dataset. However, all existing methods generate trajectories in the geographical coordinate system, which poses two limitations for their utilization in practical applications: 1) the inability to ensure that the generated trajectories are constrained on the road. 2) the lack of road-related information. In this paper, we propose a new problem to meet the practical application need, \emph{i.e.}, road network-constrained trajectory (RNTraj) generation, which can directly generate trajectories on the road network with road-related information. RNTraj is a hybrid type of data, in which each point is represented by a discrete road segment and a continuous moving rate. To generate RNTraj, we design a diffusion model called Diff-RNTraj. This model can effectively handle the hybrid RNTraj using a continuous diffusion framework by incorporating a pre-training strategy to embed hybrid RNTraj into continuous representations. During the sampling stage, a RNTraj decoder is designed to map the continuous representation generated by the diffusion model back to the hybrid RNTraj format. Furthermore, Diff-RNTraj introduces a novel loss function to enhance the spatial validity of the generated trajectories. Extensive experiments conducted on two real-world trajectory datasets demonstrate the effectiveness of the proposed model.